
搜尋評價指標——NDCG
概念
NDCG,Normalized Discounted cumulative gain 直接翻譯為歸一化折損累計增益,可能有些晦澀,沒關係下面重點來解釋一下這個評價指標。這個指標通常是用來衡量和評價搜尋結果演算法(注意這裡維基百科中提到了還有推薦演算法,但是我個人覺得不太適合推薦演算法,後面我會給我出我的解釋)。DCG的兩個思想:
1、高關聯度的結果比一般關聯度的結果更影響最終的指標得分;
2、有高關聯度的結果出現在更靠前的位置的時候,指標會越高;
累計增益(CG)
CG,cumulative gain,是DCG的前身,只考慮到了相關性的關聯程度,沒有考慮到位置的因素。它是一個搜素結果相關性分數的總和。指定位置p上的CG為:

reli 代表i這個位置上的相關度。
舉例:假設搜尋“籃球”結果,最理想的結果是:B1、B2、 B3。而出現的結果是 B3、B1、B2的話,CG的值是沒有變化的,因此需要下面的DCG。
折損累計增益(DCG)
DCG, Discounted 的CG,就是在每一個CG的結果上處以一個折損值,為什麼要這麼做呢?目的就是為了讓排名越靠前的結果越能影響最後的結果。假設排序越往後,價值越低。到第i個位置的時候,它的價值是 1/log2

當然還有一種比較常用的公式,用來增加相關度影響比重的DCG計算方式是:

百科中寫到後一種更多用於工業。當然相關性值為二進位制時,即 reli在{0,1},二者結果是一樣的。當然CG相關性不止是兩個,可以是實數的形式。
歸一化折損累計增益(NDCG)
NDCG, Normalized 的DCG,由於搜尋結果隨著檢索詞的不同,返回的數量是不一致的,而DCG是一個累加的值,沒法針對兩個不同的搜尋結果進行比較,因此需要歸一化處理,這裡是處以IDCG。
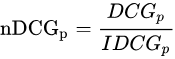
IDCG為理想情況下最大的DCG值。
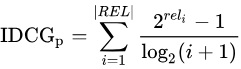
其中 |REL| 表示,結果按照相關性從大到小的順序排序,取前p個結果組成的集合。也就是按照最優的方式對結果進行排序。
實際的例子
假設搜尋回來的5個結果,其相關性分數分別是 3、2、3、0、1、2
那麼 CG = 3+2+3+0+1+2
可以看到只是對相關的分數進行了一個關聯的打分,並沒有召回的所在位置對排序結果評分對影響。而我們看DCG:
| i | reli | log2(i+1) | reli /log2(i+1) |
| 1 | 3 | 1 | 3 |
| 2 | 2 | 1.58 | 1.26 |
| 3 | 3 | 2 | 1.5 |
| 4 | 0 | 2.32 | 0 |
| 5 | 1 | 2.58 | 0.38 |
| 6 | 2 | 2.8 | 0.71 |
所以 DCG = 3+1.26+1.5+0+0.38+0.71 = 6.86
接下來我們歸一化,歸一化需要先結算 IDCG,假如我們實際召回了8個物品,除了上面的6個,還有兩個結果,假設第7個相關性為3,第8個相關性為0。那麼在理想情況下的相關性分數排序應該是:3、3、3、2、2、1、0、0。計算[email protected]:
| i | reli | log2(i+1) | reli /log2(i+1) |
| 1 | 3 | 1 | 3 |
| 2 | 3 | 1.58 | 1.89 |
| 3 | 3 | 2 | 1.5 |
| 4 | 2 | 2.32 | 0.86 |
| 5 | 2 | 2.58 | 0.77 |
| 6 | 1 | 2.8 | 0.35 |
所以IDCG = 3+1.89+1.5+0.86+0.77+0.35 = 8.37
so 最終 [email protected] = 6.86/8.37 = 81.96%