
利用scrapy獲取抽屜新熱榜的標題和內容以及新聞地址儲存到本地
阿新 • • 發佈:2018-11-09
1、安裝scrapy
pip3 install scrapy
2、開啟terminal,cd 到想要建立程式的目錄下
3、建立一個scrapy專案
在終端輸入:scrapy startproject my_first_scrapy(專案名)
4、在終端輸入:cd my_first_scrapy 進入到專案目錄下
5、新建爬蟲:
輸入: scrapy genspider chouti chouti.com (chouti: 爬蟲名稱, chouti.com : 要爬取的網站的起始網址)
6、在pycharm中開啟my_first_scrapy,就可以看到剛才建立的專案:

7、開啟settings.py可以對專案相關引數進行設定,如設定userAgent:
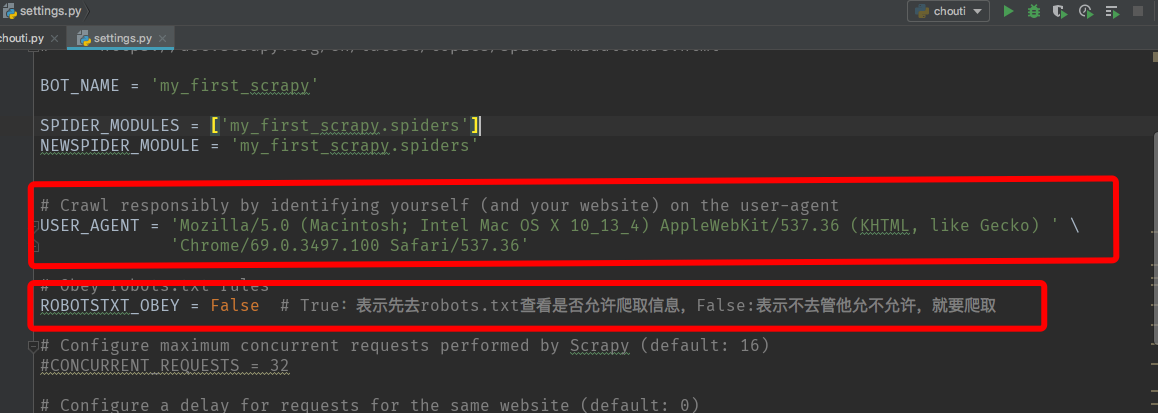
8、開啟chouti.py編寫程式碼:


# -*- coding: utf-8 -*- """ 獲取抽屜新熱榜的標題和內容以及新聞地址儲存到本地 """ import scrapy from scrapy.http.response.html import HtmlResponse class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.comView Code'] start_urls = ['http://chouti.com/'] def parse(self, response): # print(response, type(response)) # <class 'scrapy.http.response.html.HtmlResponse'> # print(response.text) # 解析文字內容, 提取標題和簡介,地址 # 去頁面中找id=content-list的div標籤,再去這個div下找class=item的divwith open("news.txt", "a+", encoding="utf-8") as f: items = response.xpath("//div[@id='content-list']/div[@class='item']") # "//"表示從html檔案的根部開始找。"/"表示從兒子裡面找。".//"表示相對的,及當前目錄下的兒子裡面找 for item in items: # 當前目錄下找class=part1的div標籤,再找div標籤下的a標籤的文字資訊text(),並且只取第一個 # a標籤後面可以加索引,表示取第幾個a標籤,如第一個:a[0] title = item.xpath(".//div[@class='part1']/a/text()").extract_first().strip() # 去掉標題兩端的空格 href = item.xpath(".//div[@class='part1']/a/@href").extract_first().strip() # 取href屬性 summary = item.xpath(".//div[@class='area-summary']/span/text()").extract_first() # print(1, title) # print(2, href) # print(3, summary) f.write(title + "\n" + href + "\n" + summary + "\n" + "------------" + "\n")
9、在終端輸入:
scrapy crawl chouti(會列印日誌) 或者 scrapy crawl chouti --nolog (不列印日誌)
執行爬蟲專案。