
Java程式設計師從笨鳥到菜鳥之(一)開發環境搭建,基本語法,字串,陣列
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
本文來自:曹勝歡部落格專欄。轉載請註明出處:http://blog.csdn.net/csh624366188
今天進行第一塊的複習,首先是環境的搭建,
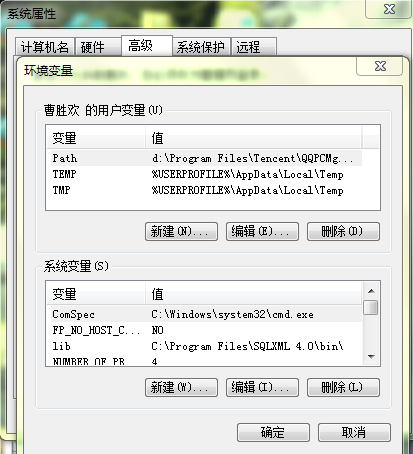
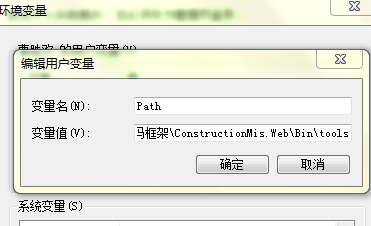
然後在dos命令裡面測試一下,如果有下面結果即為配置成功:
環境變數配置好之後,我們就可以進行我們的java開發之旅了,下面進行java基本語法的複習了:
一:首先說一下
1.java每行程式碼以;結尾。
2.Java中的註釋有:
(1)// 註釋一行
以“//”開始,終止於行尾,一般作單行註釋,可放在語句的後面
(2)/*……*/ 一行或多行註釋
以“/*”開始,最後以“*/”結束,中間可寫多行。
(3)/**……*/
以“/**”開始,最後以“*/”結束,中間可寫多行。這種註釋主要是為支援JDK 工具javadoc而採用的。
3.Java中的合法標示符要符合一下規則:1
1)要以大小寫字母或者美元符號或者下劃線開頭,不能以數字開頭
2)標示符命名不能用關鍵字,關鍵字是java內部所用到的標示符,為了避免混淆,所以不能用。
3)類,變數,方法名命名儘量有一定規則,不要隨便命名,雖然系統不會報錯,但是為了專案開發後期的維護,所以儘量起比較有意義的名字,並且命名要符合一定的規則,如駝峰規則。
二:java基本資料型別
Java資料型別被分為:基本資料型別和引用資料型別。
Java中有8中基本資料型別:
型別 位長/b 預設值 取值範圍
布林型 (boolean) 1 false true false
位元組型(byte ) 8 0 -128~127
字元型 (char) 16 ‘\u0000’ ‘\u0000’~’\uffff’即0~65535
短整型(short) 16 0 -32768~32767
整型(int) 32 0 -231~231-1
長整型(long) 64 0 -263~263-1
單精度(float) 32 0.0 +-1.4E-45 或+-3.4028235E+38
雙精度(double) 64 0.0 +-4.9E-324 或+-1.797693134862315E+308
注:String型別不是基本資料型別,它被定義為類,屬於引用資料型別。,由於字串是常用的資料型別。Java提供了對String型別特殊操作,直接引用,例如:String s="hello world";
三:引用型別
引用型別是一個物件型別的,它的值是指向記憶體空間的引用,就是地址,所指向的記憶體中儲存著變數所表示的一個值或一組值。很好理解吧,因為一個物件,比如說一個人,不可能是個數字也不可能是個字元啊,所以要想找它的話只能找它的地址了。
接下來看看基本型別和引用型別變數的不同處理吧。基本型別自然是簡單,宣告是自然系統就給它空間了。例如,
int baijq;
baijq=250; //宣告變數baijq的同時,系統給baijq分配了空間。
引用型別就不是了,只給變數分配了引用空間,資料空間沒有分配,因為誰都不知道資料是什麼啊,整數,字元?我們看一個錯誤的例子:
MyDate today;
today.day = 4; //發生錯誤,因為today物件的資料空間未分配。
那我們怎麼給它賦值啊?引用型別變數在聲明後必須通過例項化開闢資料空間,才能對變數所指向的物件進行訪問。舉個例子:
MyDate today; //將變數分配一個儲存引用的空間
today = new MyDate(); //這句話是2步,首先執行new MyDate(),給today變數開闢資料空間,然後再執行賦值操作。
四:定義變/常量和變數的初始化
Java定義變數結構:型別 變數名,這裡的變數名要符合標示符規則
1.變數的宣告
格式:型別 變數名[,變數名]=初值,… ;
賦值:[型別] 變數名=值
如:int a=5 , b=6 , c , d ;
說明:
(1)變數名必須在作用域中是唯一的,不同作用域中才允許相同名字的變量出現;
(2)只要在同一程式碼塊沒有同名的變數名,可以在程式中任何地方定義變數,一個程式碼塊就是兩個相對的“{ }”之間部分。
2.變數的使用範圍
每個變數的使用範圍只在定義它的程式碼塊中,包括這個程式碼塊中包含的程式碼塊。
在類開始處宣告的變數是成員變數,作用範圍在整個類;
在方法和塊中宣告的變數是區域性變數,作用範圍到它的“}”;
3.變數型別的轉換
Java 可以將低精度的數字賦值給高精度的數字型變數,反之則需要強制型別轉換。
強制轉換格式:(資料型別)資料表示式
位元組型 短整型 字元型 整型 長整型 單精度實型 雙精度實型
轉化規律:由低到高
變數與儲存器有著直接關係,定義一個變數就是要編譯器分配所需要的記憶體空間,分配多少空間,這就是根據我們所定義的變數型別所決定的。變數名實際上是代表所分配空間的記憶體首地址
常量
Java中的常量值是用文字串表示的,它區分為不同的型別,如整型常量123,實型常1.23,
字元常量‘a’,布林常量true、false以及字串常量“This is a constant string”。
Java 的常量用final 說明,約定常量名一般全部使用大寫字母,如果是多個單詞組合在一起的,單詞之間用下劃線連線,常量在程式執行時不可更改。
如:final int i=1;
i=i+1; //錯,i 是final(常量),不可更改值
例如:final double IP = 3.14159 D
說明:預設型別為64 位double 雙精度型別(D 或d),數字後面加F 或f 則是32 位float 單
精度(實數)型別
五:運算子
1、賦值運算子
賦值運算子用於把一個數賦予一個變數。賦值運算子兩邊的型別不一致時,那麼如果左側的資料型別的級別高,則右邊的資料將轉換成左邊的資料型別在賦予左邊的變數,否則需要強制型別轉換。
賦值運算子包括= 、+=、-=、*=、%=、/=等。
2、算術運算子
算數運算子用於對整型數或者浮點數進行運算,java語言中的算術運算子包括二元運算子和一元運算子。所謂的幾元運算子即參加運算的運算元的個數。
1) 二元運算子
Java的二元運算子有+(加)、-(減)、*(乘)、/(除)、%(取餘數)。
2) 一元運算子
Java的一元運算子有++(自加)、--(自減)
3、關係運算符
關係運算符用來比較兩個值,返回布林型別的值true或false。
等於 不等於 小於 小於等於 大於等於 大於
== != < <= >= >
4、條件運算子
條件運算子的作用是根據表示式的真假決定變數的值。
1> 格式:條件表示式 ? 表示式2 :表示式3
2> 功能:條件表示式為true,取“表示式2”值,為false,取“表示式3”的值
例: int a=0x10 , b=010 , max ;
max=a>b ? a : b ;
System.out.println(max) ; // 輸出16
5、 邏輯運算子
運算子 結果
~ 按位非(NOT)(一元運算)
& 按位與(AND)
| 按位或(OR)
^ 按位異或(XOR)
>> 右移
>>> 右移,左邊空出的位以0填充 ;無符號右移
<< 左移
&= 按位與賦值
|= 按位或賦值
^= 按位異或賦值
>>= 右移賦值
>>>= 右移賦值,左邊空出的位以0填充 ;無符號左移
<<= 左移賦值
按位非(NOT)
按位非也叫做補,一元運算子NOT“~”是對其運算數的每一位取反。例如,數字42,它的二進位制程式碼為: 00101010
經過按位非運算成為 11010101
六:流程控制語句
分支語句
1.簡單的if.....else語句
If(條件){
如果條件為真、、、、
}
Else{
如果條件為假、、、、、、
}
2、只有if的語句:
If(條件){
如果條件為真,執行。。。如果為假,不執行
}
3、switch語句是多分枝語句,基本語法:
Switch(expr){
Case value1:
Statements;
Break;
........
Case valueN:
Statements;
Break;
Default:
Statements;
Break;
}
注:1.expr必須是與int型別相容的型別,即為byte,short,char和int型別中的其中一種
2.Case valueN:中valueN也必須是int型別相容的型別,並且必須是常量
3.各個case子句的valueN表示式的值不同
4.Switch語句中只能有一個default子句。
迴圈語句
1.while語句2.do......while語句(此處省略三百字)
3.for語句
基本格式:for(初始化;迴圈條件;迭代部分)
功能:(1)第一次進入for 迴圈時,對迴圈控制變數賦初值;
(2) 根據判斷條件檢查是否要繼續執行迴圈。為真執行迴圈體內語句塊,為假則結束迴圈;
(3)執行完迴圈體內語句後,系統根據“迴圈控制變數增減方式”改變控制變數值,再回
(3) 到步驟(2)根據判斷條件檢查是否要繼續執行迴圈。
4.流程跳轉語句:break,continue和return語句用來控制流程的跳轉
1)break:從switch語句,迴圈語句或標號標識的程式碼塊中退出
2)continue:跳出本次迴圈,執行下次迴圈,或執行標號標識的迴圈體;
3)return:退出本方法,跳到上層呼叫方法。
4)Break語句和continue語句可以與標號聯合使用。標號用來標識程式中的語句,標號的名字可以是任意的合法識別符號。
帶有標號的迴圈體:
Loop:switch(expr){
}
七:字串
字串的幾種用法:
拼接 直接用“+”把兩個字串拼接起來
例如:String firstName = “li”;
String secondName = “ming”;
String fullName = firstName+secondName;
檢測字串是否相等 檢測兩個字串內容是否相等時使用“equals”;比較兩個字串的引用是否相等時用“==”
得到字串的長度 字串變數名.length();
String,StringBuffer,StringBuild區別
String 字串常量
StringBuffer 字串變數(執行緒安全)
StringBuilder 字串變數(非執行緒安全)
簡要的說, String 型別和 StringBuffer 型別的主要效能區別其實在於 String 是不可變的物件, 因此在每次對 String 型別進行改變的時候其實都等同於生成了一個新的 String 物件,然後將指標指向新的 String 物件,所以經常改變內容的字串最好不要用 String ,因為每次生成物件都會對系統性能產生影響,特別當記憶體中無引用物件多了以後, JVM 的 GC 就會開始工作,那速度是一定會相當慢的。
而如果是使用 StringBuffer 類則結果就不一樣了,每次結果都會對 StringBuffer 物件本身進行操作,而不是生成新的物件,再改變物件引用。所以在一般情況下我們推薦使用 StringBuffer ,特別是字串物件經常改變的情況下。而在某些特別情況下, String 物件的字串拼接其實是被 JVM 解釋成了 StringBuffer 物件的拼接,所以這些時候 String 物件的速度並不會比 StringBuffer 物件慢,而特別是以下的字串物件生成中, String 效率是遠要比 StringBuffer 快的:
String S1 = “This is only a” + “ simple” + “ test”;
StringBuffer Sb = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”);
你會很驚訝的發現,生成 String S1 物件的速度簡直太快了,而這個時候 StringBuffer 居然速度上根本一點都不佔優勢。其實這是 JVM 的一個把戲,在 JVM 眼裡,這個
String S1 = “This is only a” + “ simple” + “test”; 其實就是:
String S1 = “This is only a simple test”; 所以當然不需要太多的時間了。但大家這裡要注意的是,如果你的字串是來自另外的 String 物件的話,速度就沒那麼快了,譬如:
String S2 = “This is only a”;
String S3 = “ simple”;
String S4 = “ test”;
String S1 = S2 +S3 + S4;
這時候 JVM 會規規矩矩的按照原來的方式去做
在大部分情況下 StringBuffer > String
StringBuffer
Java.lang.StringBuffer執行緒安全的可變字元序列。一個類似於 String 的字串緩衝區,但不能修改。雖然在任意時間點上它都包含某種特定的字元序列,但通過某些方法呼叫可以改變該序列的長度和內容。
可將字串緩衝區安全地用於多個執行緒。可以在必要時對這些方法進行同步,因此任意特定例項上的所有操作就好像是以序列順序發生的,該順序與所涉及的每個執行緒進行的方法呼叫順序一致。
StringBuffer 上的主要操作是 append 和 insert 方法,可過載這些方法,以接受任意型別的資料。每個方法都能有效地將給定的資料轉換成字串,然後將該字串的字元追加或插入到字串緩衝區中。 append 方法始終將這些字元新增到緩衝區的末端;而 insert 方法則在指定的點新增字元。
例如,如果 z 引用一個當前內容是“start”的字串緩衝區物件,則此方法呼叫 z.append("le") 會使字串緩衝區包含“startle”,而 z.insert(4, "le") 將更改字串緩衝區,使之包含“starlet”。
在大部分情況下 StringBuilder > StringBufferjava.lang.StringBuilder
java.lang.StringBuilder 一個可變的字元序列是5.0新增的。此類提供一個與 StringBuffer 相容的 API,但不保證同步。該類被設計用作 StringBuffer 的一個簡易替換,用在字串緩衝區被單個執行緒使用的時候(這種情況很普遍)。如果可能,建議優先採用該類,因為在大多數實現中,它比 StringBuffer 要快。兩者的方法基本相同。
八、陣列
陣列是有序資料的集合,陣列中的每個元素具有相同的陣列名,根據陣列名和下標來唯一確定陣列中的元素。使用時要先聲明後建立
1、一位陣列
1) 一維陣列的宣告
格式: 資料型別 陣列名[ ] 或 資料型別 [ ]陣列名
例: int a[] ; String s[] ; char []c ;
說明:定義陣列,並不為資料元素分配記憶體,因此“[ ]”中不用指出陣列中元素個數。
2 )一維陣列的建立與賦值
建立陣列並不是定義陣列,而是在陣列定義後,為陣列分配儲存空間,同時對陣列元素進行初始化
(1)用運算子new 分配記憶體再賦值
格式:陣列名=new 資料型別[size]
例:int a[] ;
a=new int[3] ; // 產生a[0] , a[1] , a[2] 三個元素
a[0]=8 ; a[1]=8 ; a[2]=8 ;
3)直接賦初值並定義陣列的大小
例:int i[]={4,5,010,7,3,2,9} ;
String names[]={“張三”,”李四”,”王五”,”宋七”} ;
4)測試陣列長度(補充)
格式:陣列名.length
char c[]={‘a’,’b’,’c’,’北’,’京’} ;
System.out.print(c.length) ; // 輸出5
2、多維陣列
以二維陣列為例
例:int d[][] ; // 定義一個二維陣列
d=new int[3][4] ; // 分配3 行4 列陣列記憶體
int a[][]=new int[2][] ;
a[0]=new int[3] ; // 第二維第一個元素指向3 個整型數
a[1]=new int[5] ; // 第二維第一個元素指向5 個整型數
注意:Java 可以第二維不等長
int i[][]={{0},{1,4,5},{75,6},{8,50,4,7}} ; //定義和賦初值在一起
下面陣列定義正吳的判斷
int a[][]=new int[10,10] //錯
int a[10][10]=new int[][] //錯
int a[][]=new int[10][10] //對
int []a[]=new int[10][10] //對
int [][]a=new int[10][10] //對
注意:java中二維陣列分配空間是第二維可以為空,但是第一維必須分配記憶體。
最後以一個經典的helloworld程式碼結束本章的總結
public class HelloWorldApp{
public static void main(String[] args){
System.out.println(“hello world!”);
}
}
本文來自:曹勝歡部落格專欄。轉載請註明出處:http://blog.csdn.net/csh624366188
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
