
深度學習框架的比較 MXNet Caffe TensorFlow Torch Theano
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
1. 基本概念
1.1 MXNet相關概念
深度學習目標:如何方便的表述神經網路,以及如何快速訓練得到模型
CNN(卷積層):表達空間相關性(學表示)
RNN/LSTM:表達時間連續性(建模時序訊號)
指令式程式設計(imperative programming):嵌入的較淺,其中每個語句都按原來的意思執行,如numpy和Torch就是屬於這種
宣告式語言(declarative programing):嵌入的很深,提供一整套針對具體應用的迷你語言。即使用者只需要宣告要做什麼,而具體執行則由系統完成。這類系統包括Caffe,Theano和TensorFlow。指令式程式設計顯然更容易懂一些,更直觀一些,但是宣告式的更利於做優化,以及更利於做自動求導,所以都保留。
| 淺嵌入,指令式程式設計 | 深嵌入,宣告式程式設計 | |
| 如何執行a=b+1 | 需要b已經被賦值。立即執行加法,將結果儲存在a中。 | 返回對應的計算圖(computation graph),我們可以之後對b進行賦值,然後再執行加法運算 |
| 優點 | 語義上容易理解,靈活,可以精確控制行為。通常可以無縫的和主語言互動,方便的利用主語言的各類演算法,工具包,bug和效能偵錯程式。 | 在真正開始計算的時候已經拿到了整個計算圖,所以我們可以做一系列優化來提升效能。實現輔助函式也容易,例如對任何計算圖都提供forward和backward函式,對計算圖進行視覺化,將圖儲存到硬碟和從硬碟讀取。 |
| 缺點 | 實現統一的輔助函式和提供整體優化都很困難。 | 很多主語言的特性都用不上。某些在主語言中實現簡單,但在這裡卻經常麻煩,例如if-else語句 。debug也不容易,例如監視一個複雜的計算圖中的某個節點的中間結果並不簡單。 |
1.2 深度學習的關鍵特點
(1)層級抽象
(2)端到端學習
2. 比較表
| 比較項 | Caffe | Torch | Theano | TensorFlow | MXNet |
| 主語言 | C++/cuda | C++/Lua/cuda | Python/c++/cuda | C++/cuda | C++/cuda |
| 從語言 | Python/Matlab | - | - | Python | Python/R/Julia/Go |
| 硬體 | CPU/GPU | CPU/GPU/FPGA | CPU/GPU | CPU/GPU/Mobile | CPU/GPU/Mobile |
| 分散式 | N | N | N | Y(未開源) | Y |
| 速度 | 快 | 快 | 中等 | 中等 | 快 |
| 靈活性 | 一般 | 好 | 好 | 好 | 好 |
| 文件 | 全面 | 全面 | 中等 | 中等 | 全面 |
| 適合模型 | CNN | CNN/RNN | CNN/RNN | CNN/RNN | CNN/RNN? |
| 作業系統 | 所有系統 | Linux, OSX | 所有系統 | Linux, OSX | 所有系統 |
| 命令式 | N | Y | N | N | Y |
| 宣告式 | Y | N | Y | Y | Y |
| 介面 | protobuf | Lua | Python | C++/Python | Python/R/Julia/Go |
| 網路結構 | 分層方法 | 分層方法 | 符號張量圖 | 符號張量圖 | ? |
注:1)使用符號張量圖描述模型,增加新的層更加方便;而分層方法增加新的層需要自己實現(forward,backward和gradient更新函式)。
3.詳細描述
3.1 MXNet
MXNet的系統架構如下圖所示:
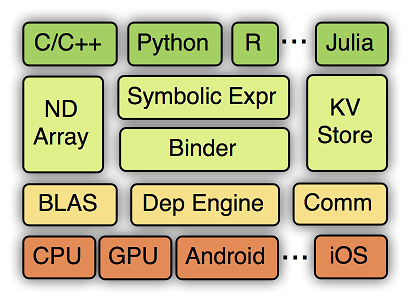
從上到下分別為各種主語言的嵌入,程式設計介面(矩陣運算,符號表達式,分散式通訊),兩種程式設計模式的統一系統實現,以及各硬體的支援。
MXNet的設計細節包括:符號執行和自動求導;執行依賴引擎;記憶體節省。
3.2 Caffe
優點:
1)第一個主流的工業級深度學習工具。
2)它開始於2013年底,由UC Berkely的Yangqing Jia老師編寫和維護的具有出色的卷積神經網路實現。在計算機視覺領域Caffe依然是最流行的工具包。
3)專精於影象處理
缺點:
1)它有很多擴充套件,但是由於一些遺留的架構問題,不夠靈活且對遞迴網路和語言建模的支援很差。
2)基於層的網路結構,其擴充套件性不好,對於新增加的層,需要自己實現(forward, backward and gradient update)
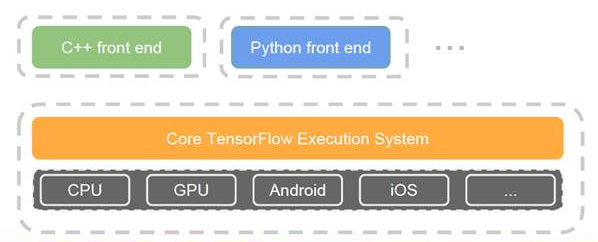
3.3 TensorFlow
優點:
1) Google開源的其第二代深度學習技術——被使用在Google搜尋、影象識別以及郵箱的深度學習框架。
2)是一個理想的RNN(遞迴神經網路)API和實現,TensorFlow使用了向量運算的符號圖方法,使得新網路的指定變得相當容易,支援快速開發。
3)TF支援使用ARM/NEON指令實現model decoding
4)TensorBoard是一個非常好用的網路結構視覺化工具,對於分析訓練網路非常有用
5)編譯過程比Theano快,它簡單地把符號張量操作對映到已經編譯好的函式呼叫
缺點:
1) 缺點是速度慢,記憶體佔用較大。(比如相對於Torch)
2)支援的層沒有Torch和Theano豐富,特別是沒有時間序列的卷積,且卷積也不支援動態輸入尺寸,這些功能在NLP中非常有用。
3.4 Torch
優點:
1)Facebook力推的深度學習框架,主要開發語言是C和Lua
2)有較好的靈活性和速度
3)它實現並且優化了基本的計算單元,使用者可以很簡單地在此基礎上實現自己的演算法,不用浪費精力在計算優化上面。核心的計算單元使用C或者cuda做了很好的優化。在此基礎之上,使用lua構建了常見的模型
4)速度最快,見convnet-benchmarks
5)支援全面的卷積操作:
- 時間卷積:輸入長度可變,而TF和Theano都不支援,對NLP非常有用;
- 3D卷積:Theano支援,TF不支援,對視訊識別很有用
缺點
1)是介面為lua語言,需要一點時間來學習。
2)沒有Python介面
3)與Caffe一樣,基於層的網路結構,其擴充套件性不好,對於新增加的層,需要自己實現(forward, backward and gradient update)
4)RNN沒有官方支援
3.5 Theano
優點:
1)2008年誕生於蒙特利爾理工學院,主要開發語言是Python
2)Theano派生出了大量深度學習Python軟體包,最著名的包括Blocks和Keras
3)Theano的最大特點是非常的靈活,適合做學術研究的實驗,且對遞迴網路和語言建模有較好的支援
4)是第一個使用符號張量圖描述模型的架構
5)支援更多的平臺
6)在其上有可用的高階工具:Blocks, Keras等
缺點:
1)編譯過程慢,但同樣採用符號張量圖的TF無此問題
2)import theano也很慢,它匯入時有很多事要做
3)作為開發者,很難進行改進,因為code base是Python,而C/CUDA程式碼被打包在Python字串中
參考資料:
2)Evaluation of Deep Learning Toolkits
3)TensorFlow vs. Theano vs. Torch comparison
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
