
深度學習框架比較(Caffe, TensorFlow, MXNet, Torch, Theano)
在這裡,我將會介紹當前比較主流的5種深度學習框架,包括 Caffe, TensorFlow, MXNet, Torch, Theano,並對這些框架進行分析。
首先對這些框架進行總覽。
 接下來將對這些框架進行分別介紹。
接下來將對這些框架進行分別介紹。
Caffe
第一個主流的工業級深度學習工具。
它開始於2013年底,由UC Berkely的Yangqing Jia老師編寫和維護的具有出色的卷積神經網路實現。在計算機視覺領域Caffe依然是最流行的工具包。
它有很多擴充套件,但是由於一些遺留的架構問題,不夠靈活且對遞迴網路和語言建模的支援很差。
TensorFlow
Google開源的其第二代深度學習技術——被使用在Google搜尋、影象識別以及郵箱的深度學習框架。
是一個理想的RNN(遞迴神經網路)API和實現,TensorFlow使用了向量運算的符號圖方法,使得新網路的指定變得相當容易,支援快速開發。
缺點是速度慢,記憶體佔用較大。(比如相對於Torch)
MXNet
是李沐和陳天奇等各路英雄豪傑打造的開源深度學習框架,是分散式機器學習通用工具包DMLC 的重要組成部分。
它注重靈活性和效率,文件也非常的詳細,同時強調提高記憶體使用的效率,甚至能在智慧手機上執行諸如影象識別等任務。
Torch
Facebook力推的深度學習框架,主要開發語言是C和Lua。
有較好的靈活性和速度。
它實現並且優化了基本的計算單元,使用者可以很簡單地在此基礎上實現自己的演算法,不用浪費精力在計算優化上面。核心的計算單元使用C或者cuda做了很好的優化。在此基礎之上,使用lua構建了常見的模型。
缺點是介面為lua語言,需要一點時間來學習。
Theano
2008年誕生於蒙特利爾理工學院,主要開發語言是Python。
Theano派生出了大量深度學習Python軟體包,最著名的包括Blocks和Keras。
Theano的最大特點是非常的靈活,適合做學術研究的實驗,且對遞迴網路和語言建模有較好的支援,缺點是速度較慢。
Google 近日釋出了 TensorFlow 1.0 候選版,這第一個穩定版將是深度學習框架發展中的里程碑的一步。自 TensorFlow 於 2015 年底正式開源,距今已有一年多,這期間 TensorFlow 不斷給人以驚喜。在這一年多時間,TensorFlow 已從初入深度學習框架大戰的新星,成為了幾近壟斷的行業事實標準。
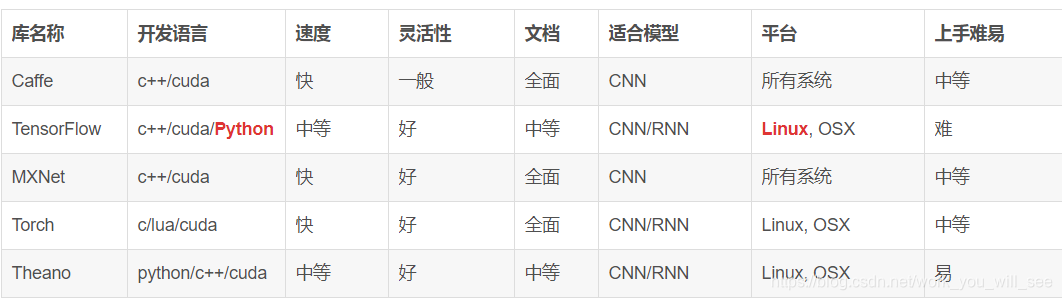
主流深度學習框架對比
深度學習研究的熱潮持續高漲,各種開源深度學習框架也層出不窮,其中包括 TensorFlow、Caffe、Keras、CNTK、Torch7、MXNet、Leaf、Theano、DeepLearning4、Lasagne、Neon 等等。然而 TensorFlow 卻殺出重圍,在關注度和使用者數上都佔據絕對優勢,大有一統江湖之勢。表 2-1 所示為各個開源框架在GitHub上的資料統計(資料統計於 2017 年 1 月 3 日),可以看到 TensorFlow 在 star 數量、fork 數量、contributor 數量這三個資料上都完勝其他對手。
究其原因,主要是 Google 在業界的號召力確實強大,之前也有許多成功的開源專案,以及 Google 強大的人工智慧研發水平,都讓大家對 Google 的深度學習框架充滿信心,以至於 TensorFlow 在 2015 年 11 月剛開源的第一個月就積累了 10000+ 的 star 。其次,TensorFlow 確實在很多方面擁有優異的表現,比如設計神經網路結構的程式碼的簡潔度,分散式深度學習演算法的執行效率,還有部署的便利性,都是其得以勝出的亮點。如果一直關注著 TensorFlow 的開發進度,就會發現基本上每星期 TensorFlow 都會有1萬行以上的程式碼更新,多則數萬行。產品本身優異的質量、快速的迭代更新、活躍的社群和積極的反饋,形成了良性迴圈,可以想見 TensorFlow 未來將繼續在各種深度學習框架中獨佔鰲頭。
觀察表2-1還可以發現,Google、Microsoft、Facebook 等巨頭都參與了這場深度學習框架大戰,此外,還有畢業於伯克利大學的賈揚清主導開發的 Caffe,蒙特利爾大學 Lisa Lab 團隊開發的 Theano,以及其他個人或商業組織貢獻的框架。另外,可以看到各大主流框架基本都支援 Python,目前 Python 在科學計算和資料探勘領域可以說是獨領風騷。雖然有來自 R、Julia 等語言的競爭壓力,但是 Python 的各種庫實在是太完善了,Web 開發、資料視覺化、資料預處理、資料庫連線、爬蟲等無所不能,有一個完美的生態環境。僅在資料挖據工具鏈上,Python 就有 NumPy、SciPy、Pandas、Scikit-learn、XGBoost 等元件,做資料採集和預處理都非常方便,並且之後的模型訓練階段可以和 TensorFlow 等基於 Python 的深度學習框架完美銜接。
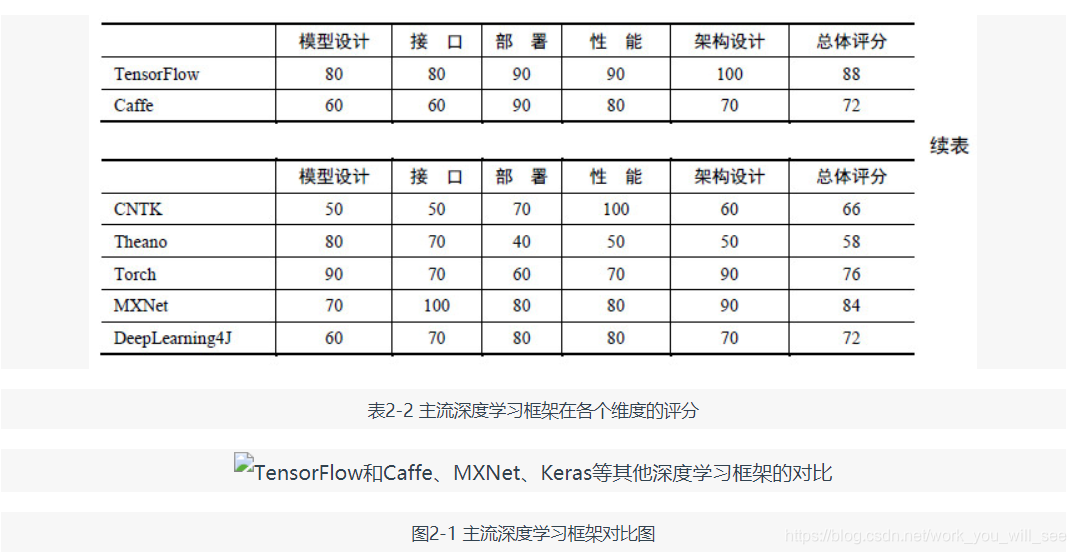
表 2-1 和圖 2-1 所示為對主流的深度學習框架 TensorFlow、Caffe、CNTK、Theano、Torch 在各個維度的評分,本書 2.2 節會對各個深度學習框架進行比較詳細的介紹。
 各深度學習框架簡介
各深度學習框架簡介
在本節,我們先來看看目前各流行框架的異同,以及各自的特點和優勢。
TensorFlow
TensorFlow 是相對高階的機器學習庫,使用者可以方便地用它設計神經網路結構,而不必為了追求高效率的實現親自寫 C++或 CUDA 程式碼。它和 Theano 一樣都支援自動求導,使用者不需要再通過反向傳播求解梯度。其核心程式碼和 Caffe 一樣是用 C++編寫的,使用 C++簡化了線上部署的複雜度,並讓手機這種記憶體和CPU資源都緊張的裝置可以運行復雜模型(Python 則會比較消耗資源,並且執行效率不高)。除了核心程式碼的 C++介面,TensorFlow 還有官方的 Python、Go 和 Java 介面,是通過 SWIG(Simplified Wrapper and Interface Generator)實現的,這樣使用者就可以在一個硬體配置較好的機器中用 Python進行實驗,並在資源比較緊張的嵌入式環境或需要低延遲的環境中用 C++部署模型。SWIG 支援給 C/C++程式碼提供各種語言的介面,因此其他指令碼語言的介面未來也可以通過 SWIG 方便地新增。不過使用 Python 時有一個影響效率的問題是,每一個 mini-batch 要從 Python 中 feed 到網路中,這個過程在 mini-batch 的資料量很小或者運算時間很短時,可能會帶來影響比較大的延遲。現在 TensorFlow 還有非官方的 Julia、Node.js、R 的介面支援,地址如下。
Julia: http://github.com/malmaud/TensorFlow.jl
Node.js: http://github.com/node-tensorflow/node-tensorflow
R: http://github.com/rstudio/tensorflow
TensorFlow 也有內建的 TF.Learn 和 TF.Slim 等上層元件可以幫助快速地設計新網路,並且相容 Scikit-learn estimator 介面,可以方便地實現 evaluate、grid search、cross validation 等功能。同時 TensorFlow 不只侷限於神經網路,其資料流式圖支援非常自由的演算法表達,當然也可以輕鬆實現深度學習以外的機器學習演算法。事實上,只要可以將計算表示成計算圖的形式,就可以使用 TensorFlow 。使用者可以寫內層迴圈程式碼控制計算圖分支的計算,TensorFlow 會自動將相關的分支轉為子圖並執行迭代運算。TensorFlow 也可以將計算圖中的各個節點分配到不同的裝置執行,充分利用硬體資源。定義新的節點只需要寫一個 Python 函式,如果沒有對應的底層運算核,那麼可能需要寫 C++或者 CUDA 程式碼實現運算操作。
在資料並行模式上,TensorFlow 和 Parameter Server 很像,但 TensorFlow 有獨立的 Variable node,不像其他框架有一個全域性統一的引數伺服器,因此引數同步更自由。TensorFlow 和 Spark 的核心都是一個數據計算的流式圖,Spark 面向的是大規模的資料,支援 SQL 等操作,而 TensorFlow 主要面向記憶體足以裝載模型引數的環境,這樣可以最大化計算效率。
TensorFlow 的另外一個重要特點是它靈活的移植性,可以將同一份程式碼幾乎不經過修改就輕鬆地部署到有任意數量 CPU 或 GPU 的 PC、伺服器或者移動裝置上。相比於 Theano,TensorFlow 還有一個優勢就是它極快的編譯速度,在定義新網路結構時,Theano 通常需要長時間的編譯,因此嘗試新模型需要比較大的代價,而 TensorFlow 完全沒有這個問題。TensorFlow 還有功能強大的視覺化元件 TensorBoard,能視覺化網路結構和訓練過程,對於觀察複雜的網路結構和監控長時間、大規模的訓練很有幫助。TensorFlow 針對生產環境高度優化,它產品級的高質量程式碼和設計都可以保證在生產環境中穩定執行,同時一旦 TensorFlow 廣泛地被工業界使用,將產生良性迴圈,成為深度學習領域的事實標準。
除了支援常見的網路結構(卷積神經網路(Convolutional Neural Network,CNN)、迴圈神經網路(Recurent Neural Network,RNN))外,TensorFlow 還支援深度強化學習乃至其他計算密集的科學計算(如偏微分方程求解等)。TensorFlow 此前不支援 symbolic loop,需要使用 Python 迴圈而無法進行圖編譯優化,但最近新加入的 XLA 已經開始支援 JIT 和 AOT,另外它使用 bucketing trick 也可以比較高效地實現迴圈神經網路。TensorFlow 的一個薄弱地方可能在於計算圖必須構建為靜態圖,這讓很多計算變得難以實現,尤其是序列預測中經常使用的 beam search。
TensorFlow 的使用者能夠將訓練好的模型方便地部署到多種硬體、作業系統平臺上,支援 Intel 和 AMD 的 CPU,通過 CUDA 支援 NVIDIA 的 GPU (最近也開始通過 OpenCL 支援 AMD 的 GPU,但沒有 CUDA 成熟),支援 Linux 和 Mac,最近在 0.12 版本中也開始嘗試支援 Windows。在工業生產環境中,硬體裝置有些是最新款的,有些是用了幾年的老機型,來源可能比較複雜,TensorFlow 的異構性讓它能夠全面地支援各種硬體和作業系統。同時,其在 CPU 上的矩陣運算庫使用了 Eigen 而不是 BLAS 庫,能夠基於 ARM 架構編譯和優化,因此在移動裝置(Android 和 iOS)上表現得很好。
TensorFlow 在最開始釋出時只支援單機,而且只支援 CUDA 6.5 和 cuDNN v2,並且沒有官方和其他深度學習框架的對比結果。在 2015 年年底,許多其他框架做了各種效能對比評測,每次 TensorFlow 都會作為較差的對照組出現。那個時期的 TensorFlow 真的不快,效能上僅和普遍認為很慢的 Theano 比肩,在各個框架中可以算是墊底。但是憑藉 Google 強大的開發實力,很快支援了新版的 cuDNN (目前支援cuDNN v5.1),在單 GPU 上的效能追上了其他框架。表 2-3 所示為 https://github.com/soumith/convnet-benchmarks 給出的各個框架在 AlexNet 上單 GPU 的效能評測。
表2-3 各深度學習框架在 AlexNet 上的效能對比
目前在單 GPU 的條件下,絕大多數深度學習框架都依賴於 cuDNN,因此只要硬體計算能力或者記憶體分配差異不大,最終訓練速度不會相差太大。但是對於大規模深度學習來說,巨大的資料量使得單機很難在有限的時間完成訓練。這時需要分散式計算使 GPU 叢集乃至 TPU 叢集平行計算,共同訓練出一個模型,所以框架的分散式效能是至關重要的。TensorFlow 在 2016 年 4 月開源了分散式版本,使用 16 塊 GPU 可達單 GPU 的 15 倍提速,在 50 塊 GPU 時可達到 40 倍提速,分散式的效率很高。目前原生支援的分散式深度學習框架不多,只有 TensorFlow、CNTK、DeepLearning4J、MXNet 等。不過目前 TensorFlow 的設計對不同裝置間的通訊優化得不是很好,其單機的 reduction 只能用 CPU 處理,分散式的通訊使用基於 socket 的 RPC,而不是速度更快的 RDMA,所以其分散式效能可能還沒有達到最優。
Google 在 2016 年 2 月開源了 TensorFlow Serving,這個元件可以將 TensorFlow 訓練好的模型匯出,並部署成可以對外提供預測服務的 RESTful 介面,如圖 2-2 所示。有了這個元件,TensorFlow 就可以實現應用機器學習的全流程:從訓練模型、除錯引數,到打包模型,最後部署服務,名副其實是一個從研究到生產整條流水線都齊備的框架。這裡引用 TensorFlow 內部開發人員的描述:“ TensorFlow Serving 是一個為生產環境而設計的高效能的機器學習服務系統。它可以同時執行多個大規模深度學習模型,支援模型生命週期管理、演算法實驗,並可以高效地利用 GPU 資源,讓 TensorFlow 訓練好的模型更快捷方便地投入到實際生產環境”。除了 TensorFlow 以外的其他框架都缺少為生產環境部署的考慮,而 Google 作為廣泛在實際產品中應用深度學習的巨頭可能也意識到了這個機會,因此開發了這個部署服務的平臺。TensorFlow Serving 可以說是一副王牌,將會幫 TensorFlow 成為行業標準做出巨大貢獻。
圖2-2 TensorFlow Serving 架構
TensorBoard 是 TensorFlow 的一組 Web 應用,用來監控 TensorFlow 執行過程,或視覺化 Computation Graph。TensorBoard 目前支援五種視覺化:標量(scalars)、圖片(images)、音訊(audio)、直方圖(histograms)和計算圖(Computation Graph)。TensorBoard 的 Events Dashboard 可以用來持續地監控執行時的關鍵指標,比如 loss、學習速率(learning rate)或是驗證集上的準確率(accuracy);Image Dashboard 則可以展示訓練過程中使用者設定儲存的圖片,比如某個訓練中間結果用 Matplotlib 等繪製(plot)出來的圖片;Graph Explorer 則可以完全展示一個 TensorFlow 的計算圖,並且支援縮放拖曳和檢視節點屬性。TensorBoard 的視覺化效果如圖 2-3 和圖 2-4 所示。
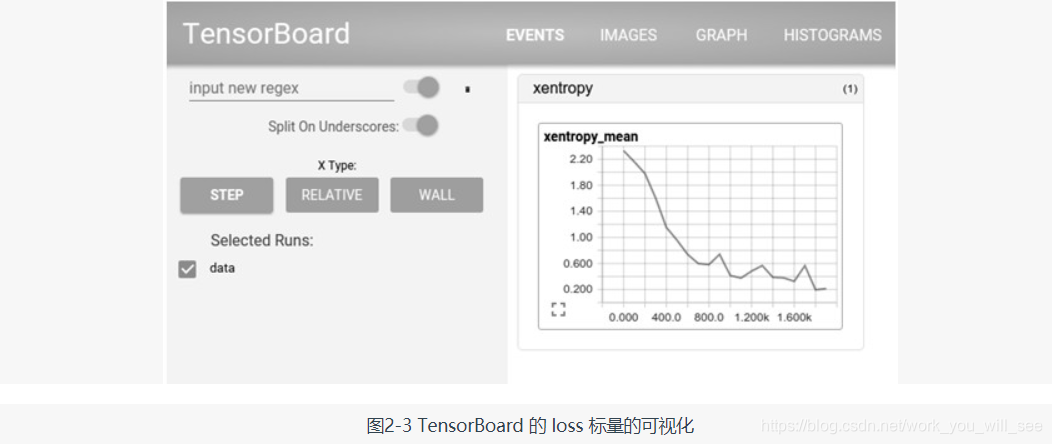
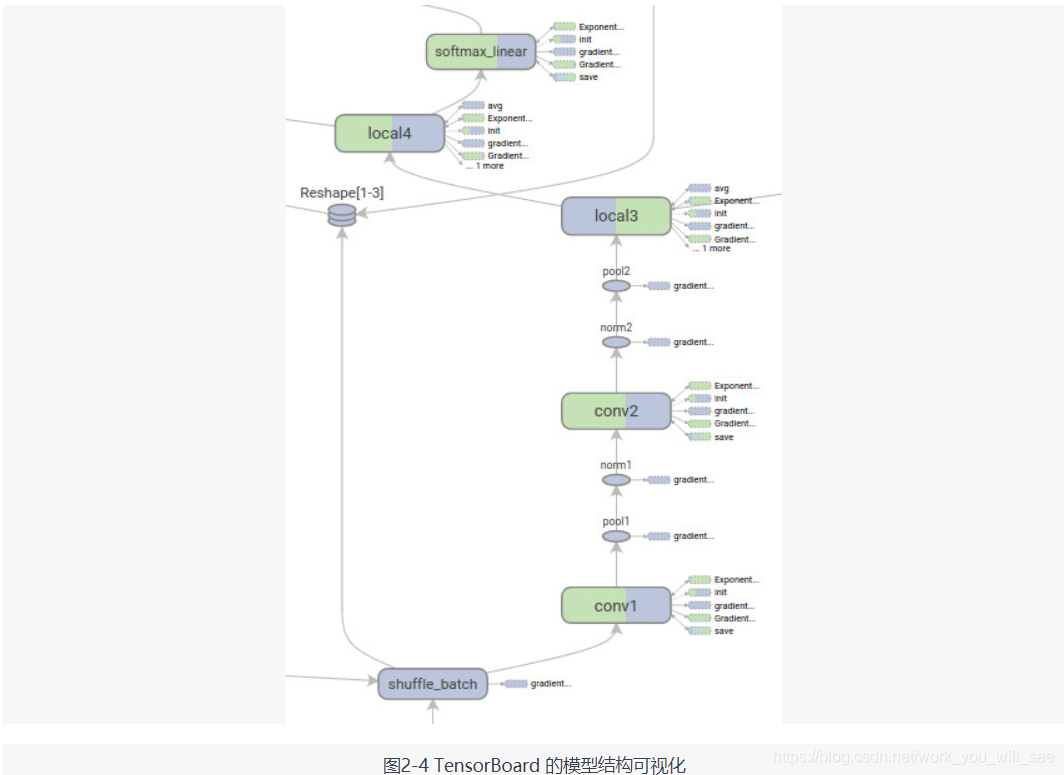 TensorFlow 擁有產品級的高質量程式碼,有 Google 強大的開發、維護能力的加持,整體架構設計也非常優秀。相比於同樣基於 Python 的老牌對手 Theano,TensorFlow 更成熟、更完善,同時 Theano 的很多主要開發者都去了 Google 開發 TensorFlow(例如書籍 Deep Learning 的作者 Ian Goodfellow,他後來去了 OpenAI)。Google 作為巨頭公司有比高校或者個人開發者多得多的資源投入到 TensorFlow 的研發,可以預見,TensorFlow 未來的發展將會是飛速的,可能會把大學或者個人維護的深度學習框架遠遠甩在身後。
TensorFlow 擁有產品級的高質量程式碼,有 Google 強大的開發、維護能力的加持,整體架構設計也非常優秀。相比於同樣基於 Python 的老牌對手 Theano,TensorFlow 更成熟、更完善,同時 Theano 的很多主要開發者都去了 Google 開發 TensorFlow(例如書籍 Deep Learning 的作者 Ian Goodfellow,他後來去了 OpenAI)。Google 作為巨頭公司有比高校或者個人開發者多得多的資源投入到 TensorFlow 的研發,可以預見,TensorFlow 未來的發展將會是飛速的,可能會把大學或者個人維護的深度學習框架遠遠甩在身後。
Caffe
官方網址:http://caffe.berkeleyvision.org/
GitHub:http://github.com/BVLC/caffe
Caffe 全稱為 Convolutional Architecture for Fast Feature Embedding,是一個被廣泛使用的開源深度學習框架(在 TensorFlow 出現之前一直是深度學習領域 GitHub star 最多的專案),目前由伯克利視覺學中心(Berkeley Vision and Learning Center,BVLC)進行維護。Caffe 的創始人是加州大學伯克利的 Ph.D.賈揚清,他同時也是TensorFlow的作者之一,曾工作於 MSRA、NEC 和 Google Brain,目前就職於 Facebook FAIR 實驗室。Caffe 的主要優勢包括如下幾點。
容易上手,網路結構都是以配置檔案形式定義,不需要用程式碼設計網路。
訓練速度快,能夠訓練 state-of-the-art 的模型與大規模的資料。
元件模組化,可以方便地拓展到新的模型和學習任務上。
Caffe 的核心概念是 Layer,每一個神經網路的模組都是一個 Layer。Layer 接收輸入資料,同時經過內部計算產生輸出資料。設計網路結構時,只需要把各個 Layer 拼接在一起構成完整的網路(通過寫 protobuf 配置檔案定義)。比如卷積的 Layer,它的輸入就是圖片的全部畫素點,內部進行的操作是各種畫素值與 Layer 引數的 convolution 操作,最後輸出的是所有卷積核 filter 的結果。每一個 Layer 需要定義兩種運算,一種是正向(forward)的運算,即從輸入資料計算輸出結果,也就是模型的預測過程;另一種是反向(backward)的運算,從輸出端的 gradient 求解相對於輸入的 gradient,即反向傳播演算法,這部分也就是模型的訓練過程。實現新 Layer 時,需要將正向和反向兩種計算過程的函式都實現,這部分計算需要使用者自己寫 C++或者 CUDA (當需要執行在 GPU 時)程式碼,對普通使用者來說還是非常難上手的。正如它的名字 Convolutional Architecture for Fast Feature Embedding 所描述的,Caffe 最開始設計時的目標只針對於影象,沒有考慮文字、語音或者時間序列的資料,因此 Caffe 對卷積神經網路的支援非常好,但對時間序列 RNN、LSTM 等支援得不是特別充分。同時,基於 Layer 的模式也對 RNN 不是非常友好,定義 RNN 結構時比較麻煩。在模型結構非常複雜時,可能需要寫非常冗長的配置檔案才能設計好網路,而且閱讀時也比較費力。
Caffe 的一大優勢是擁有大量的訓練好的經典模型(AlexNet、VGG、Inception)乃至其他 state-of-the-art (ResNet等)的模型,收藏在它的 Model Zoo (http://github.com/BVLC/ caffe/wiki/Model-Zoo)。因為知名度較高,Caffe 被廣泛地應用於前沿的工業界和學術界,許多提供原始碼的深度學習的論文都是使用 Caffe 來實現其模型的。在計算機視覺領域 Caffe 應用尤其多,可以用來做人臉識別、圖片分類、位置檢測、目標追蹤等。雖然 Caffe 主要是面向學術圈和研究者的,但它的程式執行非常穩定,程式碼質量比較高,所以也很適合對穩定性要求嚴格的生產環境,可以算是第一個主流的工業級深度學習框架。因為 Caffe 的底層是基於 C++的,因此可以在各種硬體環境編譯並具有良好的移植性,支援 Linux、Mac 和 Windows 系統,也可以編譯部署到移動裝置系統如 Android 和 iOS 上。和其他主流深度學習庫類似,Caffe 也提供了 Python 語言介面 pycaffe,在接觸新任務,設計新網路時可以使用其 Python 介面簡化操作。不過,通常使用者還是使用 Protobuf 配置檔案定義神經網路結構,再使用 command line 進行訓練或者預測。Caffe 的配置檔案是一個 JSON 型別的 .prototxt 檔案,其中使用許多順序連線的 Layer 來描述神經網路結構。Caffe 的二進位制可執行程式會提取這些 .prototxt 檔案並按其定義來訓練神經網路。理論上,Caffe 的使用者可以完全不寫程式碼,只是定義網路結構就可以完成模型訓練了。Caffe 完成訓練之後,使用者可以把模型檔案打包製作成簡單易用的介面,比如可以封裝成 Python 或 MATLAB 的 API 。不過在 .prototxt 檔案內部設計網路節構可能會比較受限,沒有像 TensorFlow 或者 Keras 那樣在 Python 中設計網路結構方便、自由。更重要的是,Caffe 的配置檔案不能用程式設計的方式調整超引數,也沒有提供像 Scikit-learn 那樣好用的 estimator 可以方便地進行交叉驗證、超引數的 Grid Search 等操作。Caffe 在 GPU 上訓練的效能很好(使用單塊 GTX 1080 訓練 AlexNet 時一天可以訓練上百萬張圖片),但是目前僅支援單機多 GPU 的訓練,沒有原生支援分散式的訓練。慶幸的是,現在有很多第三方的支援,比如雅虎開源的 CaffeOnSpark,可以藉助 Spark 的分散式框架實現 Caffe 的大規模分散式訓練。
Theano
官方網址:http://www.deeplearning.net/software/theano/
GitHub:http://github.com/Theano/Theano
Theano 誕生於2008年,由蒙特利爾大學 Lisa Lab 團隊開發並維護,是一個高效能的符號計算及深度學習庫。因其出現時間早,可以算是這類庫的始祖之一,也一度被認為是深度學習研究和應用的重要標準之一。Theano 的核心是一個數學表示式的編譯器,專門為處理大規模神經網路訓練的計算而設計。它可以將使用者定義的各種計算編譯為高效的底層程式碼,並連結各種可以加速的庫,比如 BLAS、CUDA 等。Theano 允許使用者定義、優化和評估包含多維陣列的數學表示式,它支援將計算裝載到 GPU (Theano 在 GPU 上效能不錯,但是 CPU 上較差)。與 Scikit-learn 一樣,Theano 也很好地整合了 NumPy,對 GPU 的透明讓 Theano 可以較為方便地進行神經網路設計,而不必直接寫 CUDA 程式碼。Theano 的主要優勢如下。
整合 NumPy,可以直接使用 NumPy 的 ndarray,API 介面學習成本低。
計算穩定性好,比如可以精準地計算輸出值很小的函式(像 log(1+x))。
動態地生成 C 或者 CUDA 程式碼,用以編譯成高效的機器程式碼。
因為 Theano 非常流行,有許多人為它編寫了高質量的文件和教程,使用者可以方便地查詢 Theano 的各種 FAQ,比如如何儲存模型、如何執行模型等。不過 Theano 更多地被當作一個研究工具,而不是當作產品來使用。雖然 Theano 支援 Linux、Mac 和 Windows,但是沒有底層 C++的介面,因此模型的部署非常不方便,依賴於各種 Python 庫,並且不支援各種移動裝置,所以幾乎沒有在工業生產環境的應用。Theano 在除錯時輸出的錯誤資訊非常難以看懂,因此 DEBUG 時非常痛苦。同時,Theano 在生產環境使用訓練好的模型進行預測時效能比較差,因為預測通常使用伺服器 CPU(生產環境伺服器一般沒有 GPU,而且 GPU 預測單條樣本延遲高反而不如 CPU),但是 Theano 在 CPU 上的執行效能比較差。
Theano 在單 GPU 上執行效率不錯,效能和其他框架類似。但是運算時需要將使用者的 Python 程式碼轉換成 CUDA 程式碼,再編譯為二進位制可執行檔案,編譯複雜模型的時間非常久。此外,Theano 在匯入時也比較慢,而且一旦設定了選擇某塊 GPU,就無法切換到其他裝置。目前,Theano 在 CUDA 和 cuDNN 上不支援多 GPU,只在 OpenCL 和 Theano 自己的 gpuarray 庫上支援多 GPU 訓練,速度暫時還比不上 CUDA 的版本,並且 Theano 目前還沒有分散式的實現。不過,Theano 在訓練簡單網路(比如很淺的 MLP)時效能可能比 TensorFlow 好,因為全部程式碼都是執行時編譯,不需要像 TensorFlow 那樣每次 feed mini-batch 資料時都得通過低效的 Python 迴圈來實現。
Theano 是一個完全基於 Python (C++/CUDA 程式碼也是打包為 Python 字串)的符號計算庫。使用者定義的各種運算,Theano 可以自動求導,省去了完全手工寫神經網路反向傳播演算法的麻煩,也不需要像 Caffe 一樣為 Layer 寫 C++或 CUDA 程式碼。Theano 對卷積神經網路的支援很好,同時它的符號計算 API 支援迴圈控制(內部名scan),讓 RNN 的實現非常簡單並且高效能,其全面的功能也讓 Theano 可以支援大部分 state-of-the-art 的網路。Theano 派生出了大量基於它的深度學習庫,包括一系列的上層封裝,其中有大名鼎鼎的 Keras,Keras 對神經網路抽象得非常合適,以至於可以隨意切換執行計算的後端(目前同時支援 Theano 和 TensorFlow)。Keras 比較適合在探索階段快速地嘗試各種網路結構,元件都是可插拔的模組,只需要將一個個元件(比如卷積層、啟用函式等)連線起來,但是設計新模組或者新的 Layer 就不太方便了。除 Keras 外,還有學術界非常喜愛的 Lasagne,同樣也是 Theano 的上層封裝,它對神經內網路的每一層的定義都非常嚴謹。另外,還有 scikit-neuralnetwork、nolearn 這兩個基於 Lasagne 的上層封裝,它們將神經網路抽象為相容 Scikit-learn 介面的 classifier 和 regressor,這樣就可以方便地使用 Scikit-learn 中經典的 fit、transform、score 等操作。除此之外,Theano 的上層封裝庫還有 blocks、deepy、pylearn2 和 Scikit-theano,可謂是一個龐大的家族。如果沒有 Theano,可能根本不會出現這麼多好用的 Python 深度學習庫。同樣,如果沒有 Python 科學計算的基石 NumPy,就不會有 SciPy、Scikit-learn 和 Scikit-image,可以說 Theano 就是深度學習界的 NumPy,是其他各類 Python 深度學習庫的基石。雖然 Theano 非常重要,但是直接使用 Theano 設計大型的神經網路還是太煩瑣了,用 Theano 實現 Google Inception 就像用 NumPy 實現一個支援向量機(SVM)。且不說很多使用者做不到用 Theano 實現一個 Inception 網路,即使能做到但是否有必要花這個時間呢?畢竟不是所有人都是基礎科學工作者,大部分使用場景還是在工業應用中。所以簡單易用是一個很重要的特性,這也就是其他上層封裝庫的價值所在:不需要總是從最基礎的 tensor 粒度開始設計網路,而是從更上層的 Layer 粒度設計網路。
Torch
官方網址:http://torch.ch/
GitHub:http://github.com/torch/torch7
Torch 給自己的定位是 LuaJIT 上的一個高效的科學計算庫,支援大量的機器學習演算法,同時以 GPU 上的計算優先。Torch 的歷史非常悠久,但真正得到發揚光大是在 Facebook 開源了其深度學習的元件之後,此後包括 Google、Twitter、NYU、IDIAP、Purdue 等組織都大量使用 Torch。Torch 的目標是讓設計科學計算演算法變得便捷,它包含了大量的機器學習、計算機視覺、訊號處理、並行運算、影象、視訊、音訊、網路處理的庫,同時和 Caffe 類似,Torch 擁有大量的訓練好的深度學習模型。它可以支援設計非常複雜的神經網路的拓撲圖結構,再並行化到 CPU 和 GPU 上,在 Torch 上設計新的 Layer 是相對簡單的。它和 TensorFlow 一樣使用了底層 C++加上層指令碼語言呼叫的方式,只不過 Torch 使用的是 Lua。Lua 的效能是非常優秀的(該語言經常被用來開發遊戲),常見的程式碼可以通過透明的 JIT 優化達到 C 的效能的80%;在便利性上,Lua 的語法也非常簡單易讀,擁有漂亮和統一的結構,易於掌握,比寫 C/C++簡潔很多;同時,Lua 擁有一個非常直接的呼叫 C 程式的介面,可以簡便地使用大量基於 C 的庫,因為底層核心是 C 寫的,因此也可以方便地移植到各種環境。Lua 支援 Linux、Mac,還支援各種嵌入式系統(iOS、Android、FPGA 等),只不過執行時還是必須有 LuaJIT 的環境,所以工業生產環境的使用相對較少,沒有 Caffe 和 TensorFlow 那麼多。
為什麼不簡單地使用 Python 而是使用 LuaJIT 呢?官方給出了以下幾點理由。
LuaJIT 的通用計算效能遠勝於 Python,而且可以直接在 LuaJIT 中操作 C 的 pointers。
Torch 的框架,包含 Lua 是自洽的,而完全基於 Python 的程式對不同平臺、系統移植性較差,依賴的外部庫較多。
LuaJIT 的 FFI 拓展介面非常易學,可以方便地連結其他庫到 Torch 中。Torch 中還專門設計了 N-Dimension array type 的物件 Tensor,Torch 中的 Tensor 是一塊記憶體的檢視,同時一塊記憶體可能有許多檢視(Tensor)指向它,這樣的設計同時兼顧了效能(直接面向記憶體)和便利性。同時,Torch 還提供了不少相關的庫,包括線性代數、卷積、傅立葉變換、繪圖和統計等,如圖 2-5 所示。

Torch 的 nn 庫支援神經網路、自編碼器、線性迴歸、卷積網路、迴圈神經網路等,同時支援定製的損失函式及梯度計算。Torc h因為使用了 LuaJIT,因此使用者在 Lua 中做資料預處理等操作可以隨意使用迴圈等操作,而不必像在 Python 中那樣擔心效能問題,也不需要學習 Python 中各種加速運算的庫。不過,Lua 相比 Python 還不是那麼主流,對大多數使用者有學習成本。Torch 在 CPU 上的計算會使用 OpenMP、SSE 進行優化,GPU 上使用 CUDA、cutorch、cunn、cuDNN 進行優化,同時還有 cuda-convnet 的 wrapper。Torch 有很多第三方的擴充套件可以支援 RNN,使得 Torch 基本支援所有主流的網路。和 Caffe 類似的是,Torch 也是主要基於 Layer 的連線來定義網路的。Torch 中新的 Layer 依然需要使用者自己實現,不過定義新 Layer 和定義網路的方式很相似,非常簡便,不像 Caffe 那麼麻煩,使用者需要使用 C++或者 CUDA 定義新 Layer。同時,Torch 屬於指令式程式設計模式,不像 Theano、TensorFlow 屬於宣告性程式設計(計算圖是預定義的靜態的結構),所以用它實現某些複雜操作(比如 beam search)比 Theano 和 TensorFlow 方便很多。
Lasagne
官網網址:http://lasagne.readthedocs.io/
GitHub:http://github.com/Lasagne/Lasagne
Lasagne 是一個基於 Theano 的輕量級的神經網路庫。它支援前饋神經網路,比如卷積網路、迴圈神經網路、LSTM 等,以及它們的組合;支援許多優化方法,比如 Nesterov momentum、RMSprop、ADAM 等;它是 Theano 的上層封裝,但又不像 Keras 那樣進行了重度的封裝,Keras 隱藏了 Theano 中所有的方法和物件,而 Lasagne 則是借用了 Theano 中很多的類,算是介於基礎的 Theano 和高度抽象的 Keras 之間的一個輕度封裝,簡化了操作同時支援比較底層的操作。Lasagne 設計的六個原則是簡潔、透明、模組化、實用、聚焦和專注。
Keras
官方網址:http://keras.io
GitHub:http://github.com/fchollet/keras
Keras 是一個崇尚極簡、高度模組化的神經網路庫,使用 Python 實現,並可以同時執行在 TensorFlow 和 Theano 上。它旨在讓使用者進行最快速的原型實驗,讓想法變為結果的這個過程最短。Theano 和 TensorFlow 的計算圖支援更通用的計算,而 Keras 則專精於深度學習。Theano 和 TensorFlow 更像是深度學習領域的 NumPy,而 Keras 則是這個領域的 Scikit-learn。它提供了目前為止最方便的 API,使用者只需要將高階的模組拼在一起,就可以設計神經網路,它大大降低了程式設計開銷(code overhead)和閱讀別人程式碼時的理解開銷(cognitive overhead)。它同時支援卷積網路和迴圈網路,支援級聯的模型或任意的圖結構的模型(可以讓某些資料跳過某些 Layer 和後面的 Layer 對接,使得建立 Inception 等複雜網路變得容易),從 CPU 上計算切換到 GPU 加速無須任何程式碼的改動。因為底層使用 Theano 或 TensorFlow,用 Keras 訓練模型相比於前兩者基本沒有什麼效能損耗(還可以享受前兩者持續開發帶來的效能提升),只是簡化了程式設計的複雜度,節約了嘗試新網路結構的時間。可以說模型越複雜,使用 Keras 的收益就越大,尤其是在高度依賴權值共享、多模型組合、多工學習等模型上,Keras 表現得非常突出。Keras 所有的模組都是簡潔、易懂、完全可配置、可隨意插拔的,並且基本上沒有任何使用限制,神經網路、損失函式、優化器、初始化方法、啟用函式和正則化等模組都是可以自由組合的。Keras 也包括絕大部分 state-of-the-art 的 Trick,包括 Adam、RMSProp、Batch Normalization、PReLU、ELU、LeakyReLU 等。同時,新的模組也很容易新增,這讓 Keras 非常適合最前沿的研究。Keras 中的模型也都是在 Python 中定義的,不像 Caffe、CNTK 等需要額外的檔案來定義模型,這樣就可以通過程式設計的方式除錯模型結構和各種超引數。在 Keras 中,只需要幾行程式碼就能實現一個 MLP,或者十幾行程式碼實現一個 AlexNet,這在其他深度學習框架中基本是不可能完成的任務。Keras 最大的問題可能是目前無法直接使用多 GPU,所以對大規模的資料處理速度沒有其他支援多 GPU 和分散式的框架快。Keras 的程式設計模型設計和 Torch 很像,但是相比 Torch,Keras 構建在 Python 上,有一套完整的科學計算工具鏈,而 Torch 的程式語言 Lua 並沒有這樣一條科學計算工具鏈。無論從社群人數,還是活躍度來看,Keras 目前的增長速度都已經遠遠超過了 Torch。
MXNet
官網網址:http://mxnet.io
GitHub:http://github.com/dmlc/mxnet
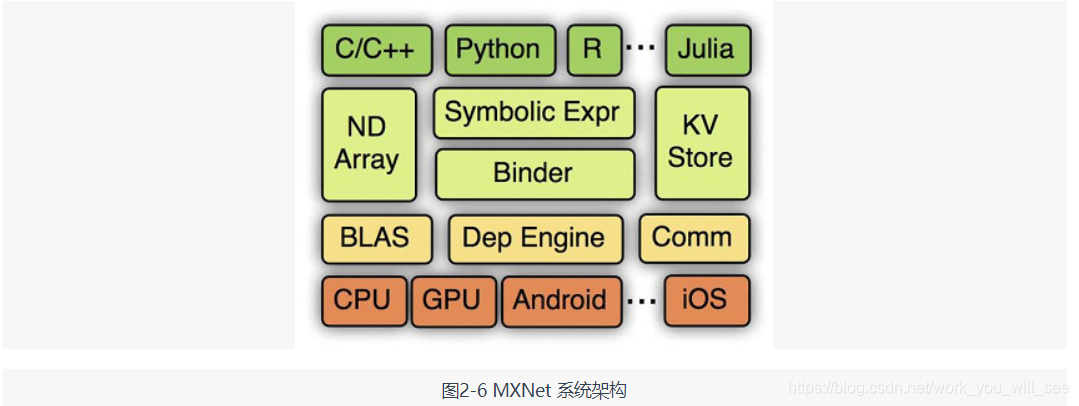
MXNet 是 DMLC(Distributed Machine Learning Community)開發的一款開源的、輕量級、可移植的、靈活的深度學習庫,它讓使用者可以混合使用符號程式設計模式和指令式程式設計模式來最大化效率和靈活性,目前已經是 AWS 官方推薦的深度學習框架。MXNet 的很多作者都是中國人,其最大的貢獻組織為百度,同時很多作者來自 cxxnet、minerva 和 purine2 等深度學習專案,可謂博採眾家之長。它是各個框架中率先支援多 GPU 和分散式的,同時其分散式效能也非常高。MXNet 的核心是一個動態的依賴排程器,支援自動將計算任務並行化到多個 GPU 或分散式叢集(支援 AWS、Azure、Yarn 等)。它上層的計算圖優化演算法可以讓符號計算執行得非常快,而且節約記憶體,開啟 mirror 模式會更加省記憶體,甚至可以在某些小記憶體 GPU 上訓練其他框架因視訊記憶體不夠而訓練不了的深度學習模型,也可以在移動裝置(Android、iOS)上執行基於深度學習的影象識別等任務。此外,MXNet 的一個很大的優點是支援非常多的語言封裝,比如 C++、Python、R、Julia、Scala、Go、MATLAB 和 JavaScript 等,可謂非常全面,基本主流的指令碼語言全部都支援了。在 MXNet 中構建一個網路需要的時間可能比 Keras、Torch 這類高度封裝的框架要長,但是比直接用 Theano 等要快。MXNet 的各級系統架構(下面為硬體及作業系統底層,逐層向上為越來越抽象的介面)如圖2-6所示。
 DIGITS
DIGITS
官方網址:http://developer.nvidia.com/digits
GitHub: http://github.com/NVIDIA/DIGITS
DIGITS(Deep Learning GPU Training System)不是一個標準的深度學習庫,它可以算是一個 Caffe 的高階封裝(或者 Caffe 的 Web 版培訓系統)。因為封裝得非常重,以至於你不需要(也不能)在 DIGITS 中寫程式碼,即可實現一個深度學習的圖片識別模型。在 Caffe 中,定義模型結構、預處理資料、進行訓練並監控訓練過程是相對比較煩瑣的,DIGITS 把所有這些操作都簡化為在瀏覽器中執行。它可以算作 Caffe 在圖片分類上的一個漂亮的使用者視覺化介面(GUI),計算機視覺的研究者或者工程師可以非常方便地設計深度學習模型、測試準確率,以及除錯各種超引數。同時使用它也可以生成資料和訓練結果的視覺化統計報表,甚至是網路的視覺化結構圖。訓練好的 Caffe 模型可以被 DIGITS 直接使用,上傳圖片到伺服器或者輸入 url 即可對圖片進行分類。
CNTK
官方網址:http://cntk.ai
GitHub:http://github.com/Microsoft/CNTK
CNTK(Computational Network Toolkit)是微軟研究院(MSR)開源的深度學習框架。它最早由 start the deep learning craze 的演講人建立,目前已經發展成一個通用的、跨平臺的深度學習系統,在語音識別領域的使用尤其廣泛。CNTK 通過一個有向圖將神經網路描述為一系列的運算操作,這個有向圖中子節點代表輸入或網路引數,其他節點代表各種矩陣運算。CNTK 支援各種前饋網路,包括 MLP、CNN、RNN、LSTM、Sequence-to-Sequence 模型等,也支援自動求解梯度。CNTK 有豐富的細粒度的神經網路元件,使得使用者不需要寫底層的 C++或 CUDA,就能通過組合這些元件設計新的複雜的 Layer。CNTK 擁有產品級的程式碼質量,支援多機、多 GPU 的分散式訓練。
CNTK 設計是效能導向的,在 CPU、單 GPU、多 GPU,以及 GPU 叢集上都有非常優異的表現。同時微軟最近推出的 1-bit compression 技術大大降低了通訊代價,讓大規模並行訓練擁有了很高的效率。CNTK 同時宣稱擁有很高的靈活度,它和 Caffe 一樣通過配置檔案定義網路結構,再通過命令列程式執行訓練,支援構建任意的計算圖,支援 AdaGrad、RmsProp 等優化方法。它的另一個重要特性就是拓展性,CNTK 除了內建的大量運算核,還允許使用者定義他們自己的計算節點,支援高度的定製化。CNTK 在 2016 年 9 月釋出了對強化學習的支援,同時,除了通過寫配置檔案的方式定義網路結構,CNTK 還將支援其他語言的繫結,包括 Python、C++和 C#,這樣使用者就可以用程式設計的方式設計網路結構。CNTK 與 Caffe一樣也基於 C++並且跨平臺,大部分情況下,它的部署非常簡單。PC 上支援 Linux、Mac 和 Windows,但是它目前不支援 ARM 架構,限制了其在移動裝置上的發揮。圖 2-7 所示為 CNTK 目前的總體架構圖。
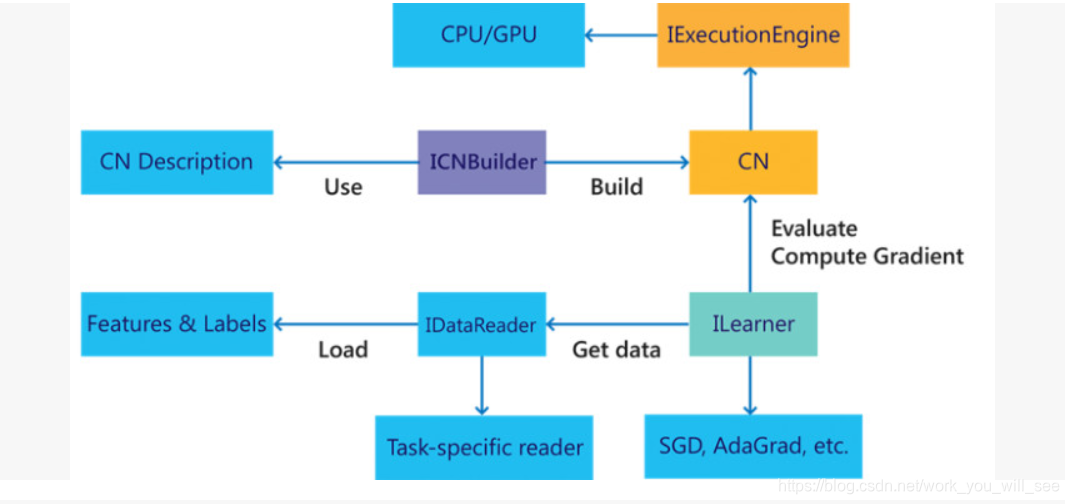
圖2-7 CNTK的總體架構圖
CNTK 原生支援多 GPU 和分散式,從官網公佈的對比評測來看,效能非常不錯。在多 GPU 方面,CNTK 相對於其他的深度學習庫表現得更突出,它實現了 1-bit SGD 和自適應的 mini-batching。圖 2-8 所示為 CNTK 官網公佈的在 2015 年 12 月的各個框架的效能對比。在當時,CNTK 是唯一支援單機 8 塊 GPU 的框架,並且在分散式系統中可以超越 8 塊 GPU 的效能。
圖2-8 CNTK與各個框架的效能對比
Deeplearning4J
官方網址:http://deeplearning4j.org/
GitHub: http://github.com/deeplearning4j/deeplearning4j
Deeplearning4J(簡稱DL4J)是一個基於 Java 和 Scala 的開源的分散式深度學習庫,由 Skymind 於 2014 年 6 月釋出,其核心目標是建立一個即插即用的解決方案原型。埃森哲、雪弗蘭、博斯諮詢和 IBM 等都是 DL4J 的客戶。DL4J 擁有一個多用途的 n-dimensional array 的類,可以方便地對資料進行各種操作;擁有多種後端計算核心,用以支援 CPU 及 GPU 加速,在影象識別等訓練任務上的效能與 Caffe 相當;可以與 Hadoop 及 Spark 自動整合,同時可以方便地在現有叢集(包括但不限於AWS,Azure等)上進行擴充套件,同時 DL4J 的並行化是根據叢集的節點和連線自動優化,不像其他深度學習庫那樣可能需要使用者手動調整。DL4J 選擇 Java 作為其主要語言的原因是,目前基於 Java 的分散式計算、雲端計算、大資料的生態非常龐大。使用者可能擁有大量的基於 Hadoop 和 Spark 的叢集,因此在這類叢集上搭建深度學習平臺的需求便很容易被 DL4J 滿足。同時 JVM 的生態圈內還有數不勝數的 Library 的支援,而 DL4J 也建立了 ND4J,可以說是 JVM 中的 NumPy,支援大規模的矩陣運算。此外,DL4J 還有商業版的支援,付費使用者在出現問題時可以通過電話諮詢尋求支援。
Chainer
官方網址:http://chainer.org
GitHub:http://github.com/pfnet/chainer
Chainer 是由日本公司 Preferred Networks 於 2015 年 6 月釋出的深度學習框架。Chainer 對自己的特性描述如下。
Powerful:支援 CUDA 計算,只需要幾行程式碼就可以使用 GPU 加速,同時只需少許改動就可以執行在多 GPU 上。
Flexible:支援多種前饋神經網路,包括卷積網路、迴圈網路、遞迴網路,支援執行中動態定義的網路(Define-by-Run)。
Intuitive:前饋計算可以引入 Python 的各種控制流,同時反向傳播時不受干擾,簡化了除錯錯誤的難度。
絕大多數的深度學習框架是基於“Define-and-Run”的,也就是說,需要首先定義一個網路,再向網路中 feed 資料(mini-batch)。因為網路是預先靜態定義的,所有的控制邏輯都需要以 data 的形式插入網路中,包括像 Caffe 那樣定義好網路結構檔案,或者像 Theano、Torch、TensorFlow 等使用程式語言定義網路。而 Chainer 則相反,網路是在實際執行中定義的,Chainer 儲存歷史執行的計算結果,而不是網路的結構邏輯,這樣就可以方便地使用 Python 中的控制流,所以無須其他工作就可以直接在網路中使用條件控制和迴圈。
Leaf
官方網址:http://autumnai.com/leaf/book
GitHub:http://github.com/autumnai/leaf
Leaf 是一個基於 Rust 語言的直觀的跨平臺的深度學習乃至機器智慧框架,它擁有一個清晰的架構,除了同屬 Autumn AI 的底層計算庫 Collenchyma,Leaf 沒有其他依賴庫。它易於維護和使用,並且擁有非常高的效能。Leaf 自身宣傳的特點是為 Hackers 定製的,這裡的 Hackers 是指希望用最短的時間和最少的精力實現機器學習演算法的技術極客。它的可移植性非常好,可以執行在 CPU、GPU 和 FPGA 等裝置上,可以支援有任何作業系統的 PC、伺服器,甚至是沒有作業系統的嵌入式裝置,並且同時支援 OpenCL 和 CUDA。Leaf 是 Autumn AI 計劃的一個重要元件,後者的目標是讓人工智慧演算法的效率提高 100 倍。憑藉其優秀的設計,Leaf 可以用來建立各種獨立的模組,比如深度強化學習、視覺化監控、網路部署、自動化預處理和大規模產品部署等。
Leaf 擁有最簡單的 API,希望可以最簡化使用者需要掌握的技術棧。雖然才剛誕生不久,Leaf 就已經躋身最快的深度學習框架之一了。圖 2-9 所示為 Leaf 官網公佈的各個框架在單 GPU 上訓練 VGG 網路的計算時間(越小越好)的對比(這是和早期的 TensorFlow 對比,最新版的 TensorFlow 效能已經非常好了)。
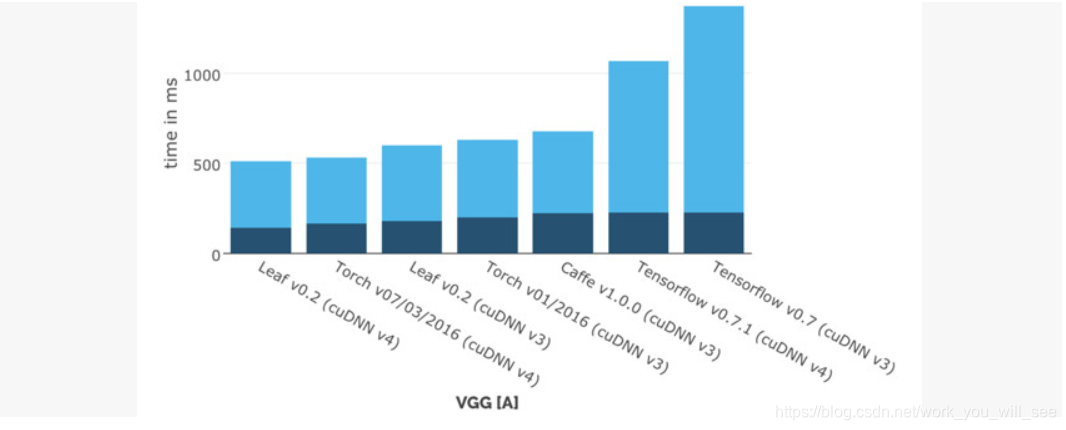
圖2-9 Leaf 和各深度學習框架的效能對比(深色為 forawrd,淺色為 backward)
DSSTNE
GitHub:http://github.com/amznlabs/amazon-dsstne
DSSTNE(Deep Scalable Sparse Tensor Network Engine)是亞馬遜開源的稀疏神經網路框架,在訓練非常稀疏的資料時具有很大的優勢。DSSTNE 目前只支援全連線的神經網路,不支援卷積網路等。和 Caffe 類似,它也是通過寫一個 JSON 型別的檔案定義模型結構,但是支援非常大的 Layer(輸入和輸出節點都非常多);在啟用函式、初始化方式及優化器方面基本都支援了 state-of-the-art 的方法,比較全面;支援大規模分散式的 GPU 訓練,不像其他框架一樣主要依賴資料並行,DSSTNE 支援自動的模型並行(使用資料並行需要在訓練速度和模型準確度上做一定的 trade-off,模型並行沒有這個問題)。
在處理特徵非常多(上億維)的稀疏訓練資料時(經常在推薦、廣告、自然語言處理任務中出現),即使一個簡單的三個隱層的 MLP(Multi-Layer Perceptron)也會變成一個有非常多引數的模型(可能高達上萬億)。以傳統的稠密矩陣的方式訓練方法很難處理這麼多的模型引數,更不必提超大規模的資料量,而 DSSTNE 有整套的針對稀疏資料的優化,率先實現了對超大稀疏資料訓練的支援,同時在效能上做了非常大的改進。
在 DSSTNE 官方公佈的測試中,DSSTNE 在 MovieLens 的稀疏資料上,在單 M40 GPU 上取得了比 TensorFlow 快 14.8 倍的效能提升(注意是和老版的 TensorFlow 比較),如圖 2-10 所示。一方面是因為 DSSTNE 對稀疏資料的優化;另一方面是 TensorFlow 在資料傳輸到 GPU 上時花費了大量時間,而 DSSTNE 則優化了資料在GPU內的保留;同時 DSSTNE 還擁有自動模型並行功能,而 TensorFlow 中則需要手動優化,沒有自動支援。
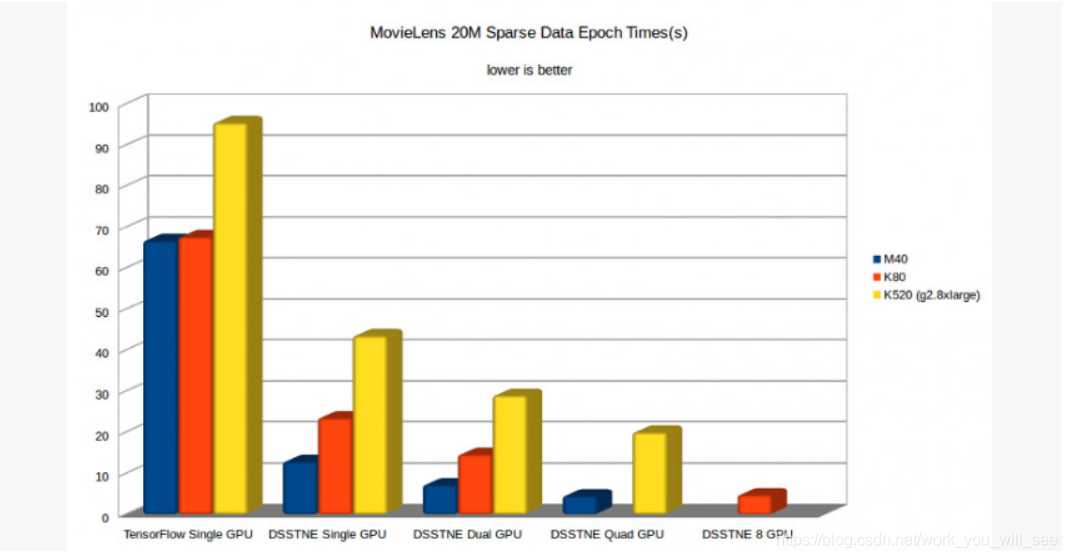
圖2-10 DSSTNE 在稀疏資料上與 TensorFlow 的效能對比
參考
深度學習框架的評估與比較
http://www.infoq.com/cn/news/2016/01/evaluation-comparison-deep-learn
Caffe、TensorFlow、MXnet三個開源庫對比
http://chenrudan.github.io/blog/2015/11/18/comparethreeopenlib.html
CVPR 2015深度學習回顧:ConvNet、Caffe、Torch及其他
http://www.csdn.net/article/1970-01-01/2825395
torch7怎麼樣?和theano和caffe相比如何?順便問下實現cnn麻煩嗎?
https://www.zhihu.com/question/34789475
深度學習簡析,TensorFlow,Torch,Theano,Mxn
http://lchiffon.github.io/2015/11/16/long.html