
爬蟲爬取抖音熱門音樂
阿新 • • 發佈:2018-11-09
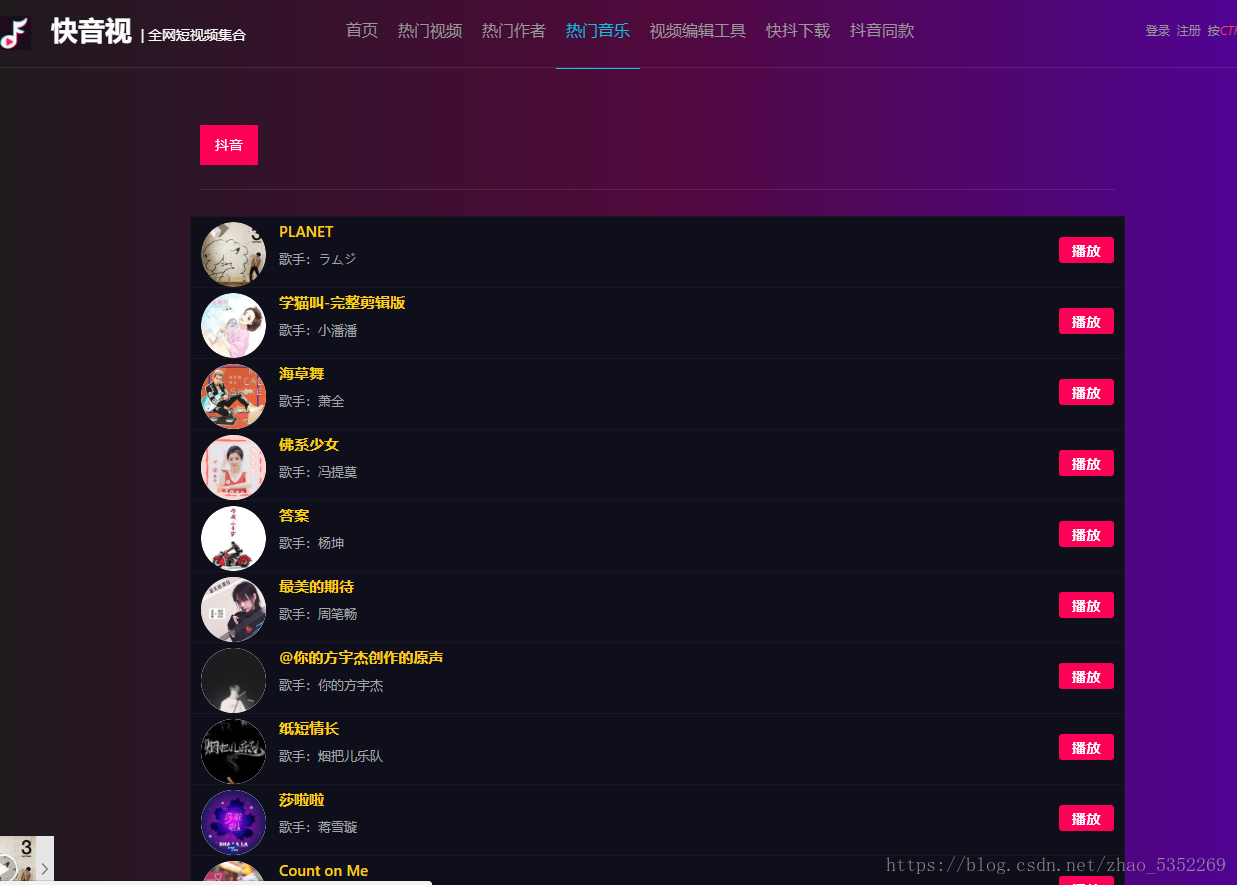
爬取抖音的熱門 音樂

詳細程式碼在下面
響應體內容工作流
預設情況下,當你進行網路請求後,響應體會立即被下載。你可以通過 stream 引數覆蓋這個行為,推遲下載響應體直到訪問 Response.content 屬性:
tarball_url = 'https://github.com/kennethreitz/requests/tarball/master' r = requests.get(tarball_url, stream=True)
此時僅有響應頭被下載下來了,連線保持開啟狀態,因此允許我們根據條件獲取內容:
if int(r.headers['content-length']) < TOO_LONG: content = r.content ...
你可以進一步使用 Response.iter_content 和 Response.iter_lines 方法來控制工作流,或者以 Response.raw 從底層 urllib3 的 urllib3.HTTPResponse <urllib3.response.HTTPResponse讀取。
如果你在請求中把 stream 設為 True,Requests 無法將連線釋放回連線池,除非你 消耗了所有的資料,或者呼叫了 Response.close。 這樣會帶來連線效率低下的問題。如果你發現你在使用stream=True
contextlib.closing (文件), 如下所示:
from contextlib import closing
with closing(requests.get('http://httpbin.org/get', stream=True)) as r:
# 在此處理響應。
保持活動狀態(持久連線)
好訊息——歸功於 urllib3,同一會話內的持久連線是完全自動處理的!同一會話內你發出的任何請求都會自動複用恰當的連線!
注意:只有所有的響應體資料被讀取完畢連線才會被釋放為連線池;所以確保將 stream
False 或讀取 Response 物件的 content 屬性。
流式上傳
Requests支援流式上傳,這允許你傳送大的資料流或檔案而無需先把它們讀入記憶體。要使用流式上傳,僅需為你的請求體提供一個類檔案物件即可:
with open('massive-body') as f:
requests.post('http://some.url/streamed', data=f)
警告
我們強烈建議你用二進位制模式(binary mode)開啟檔案。這是因為 requests 可能會為你提供 header 中的 Content-Length,在這種情況下該值會被設為檔案的位元組數。如果你用文字模式開啟檔案,就可能碰到錯誤。

#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/10/9 9:07
# @Author : jia.zhao
# @Desc :
# @File : douyintest.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
import time
"""
下載檔案引數url和檔案的全路徑
"""
def download_file(src, file_path):
# 響應體工作流
r = requests.get(src, stream=True)
# 開啟檔案
f = open(file_path, "wb")
# for chunk in r.iter_content(chunk_size=512):
# if chunk:
# f.write(chunk)
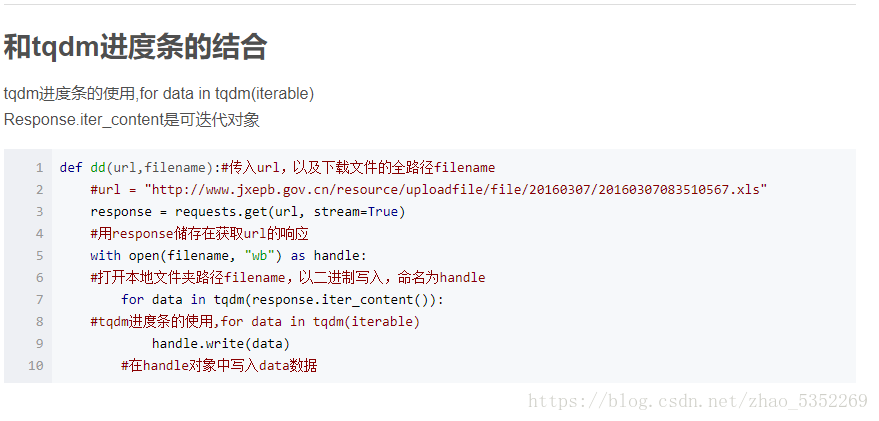
for data in tqdm(r.iter_content(chunk_size=512)):
#tqdm進度條的使用,for data in tqdm(iterable)
f.write(data)
return file_path
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 儲存路徑
save_path = "G:\\Music\\douyin\\"
url = "https://kuaiyinshi.com/hot/music/?source=dou-yin&page=1"
# 獲取響應
res = requests.get(url, headers=headers)
# 使用beautifulsoup解析
soup = BeautifulSoup(res.text, 'lxml')
# 選擇標籤獲取最大頁數
max_page = soup.select('li.page-item > a')[-2].text
# 迴圈請求
for page in range(int(max_page)):
page_url = "https://kuaiyinshi.com/hot/music/?source=dou-yin&page={}".format(page + 1)
page_res = requests.get(page_url, headers=headers)
soup = BeautifulSoup(page_res.text, 'lxml')
lis = soup.select('li.rankbox-item')
singers = soup.select('div.meta')
music_names = soup.select('h2.tit > a')
for i in range(len(lis)):
music_url = "http:" + lis[i].get('data-audio')
print("歌名:" + music_names[i].text, singers[i].text, "連結:" + music_url)
try:
download_file(music_url,
save_path + music_names[i].text + ' - ' + singers[i].text.replace('/', ' ') + ".mp3")
except:
pass
print("第{}頁完成~~~".format(page + 1))
time.sleep(1)