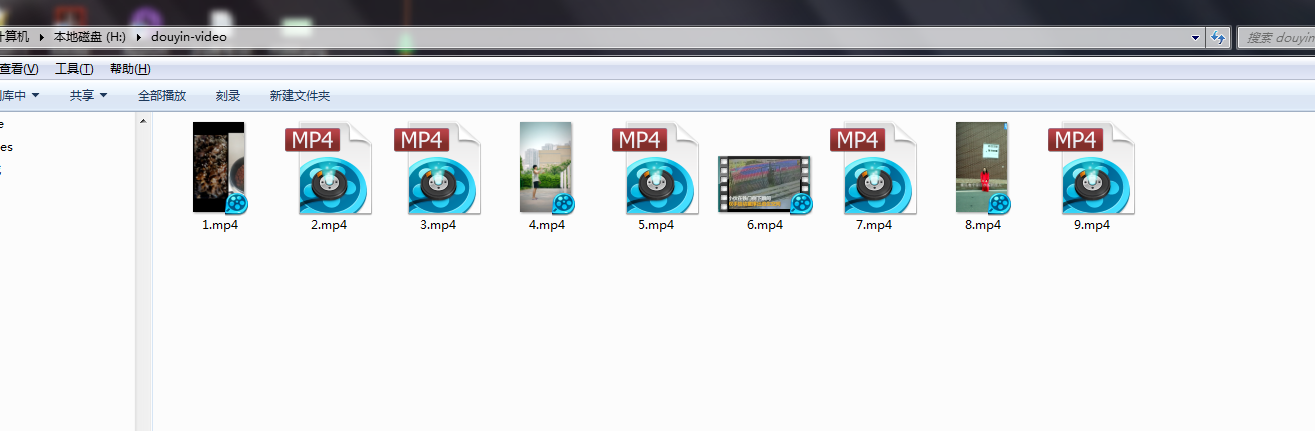
使用python-requests+Fiddler4+appium爬蟲,批量爬取抖音小視訊
抖音很火,大家都知道,樓主決定使用python爬取抖音小視訊,人家都說天下沒有爬不到的資料,so,樓主決定試試水,純屬技術愛好,分享給大家。。
1.樓主首先使用Fiddler4來抓取手機抖音app這個包,具體配置的操作,網上有很多教程供大家參考。
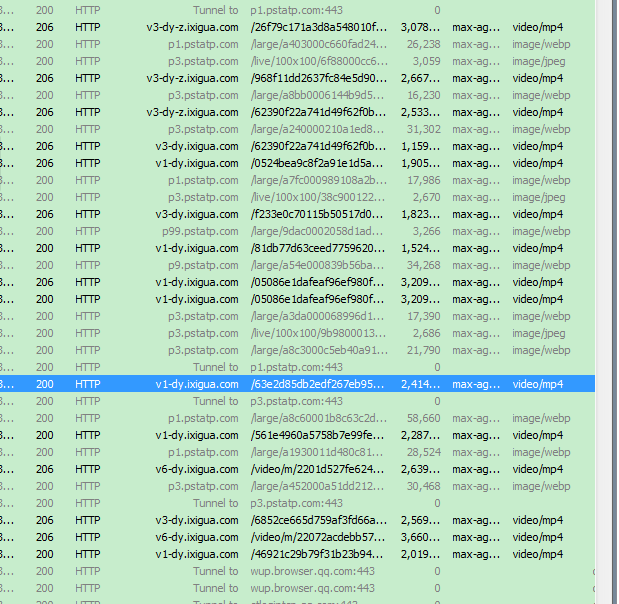
上面得出抖音的視訊的url,這些url均能在網頁中開啟,樓主數了數,這些url的字首有些不同,一共有這4種類型:
v1-dy.ixigua.com
v3-dy.ixigua.com
v6-dy.ixigua.com
v9-dy.ixigua.com
樓主檢視這四種類型得知,v6-dy.ixigua.com 這個字首後面的引數其中有一個是Expires(中文含義過期的意思)
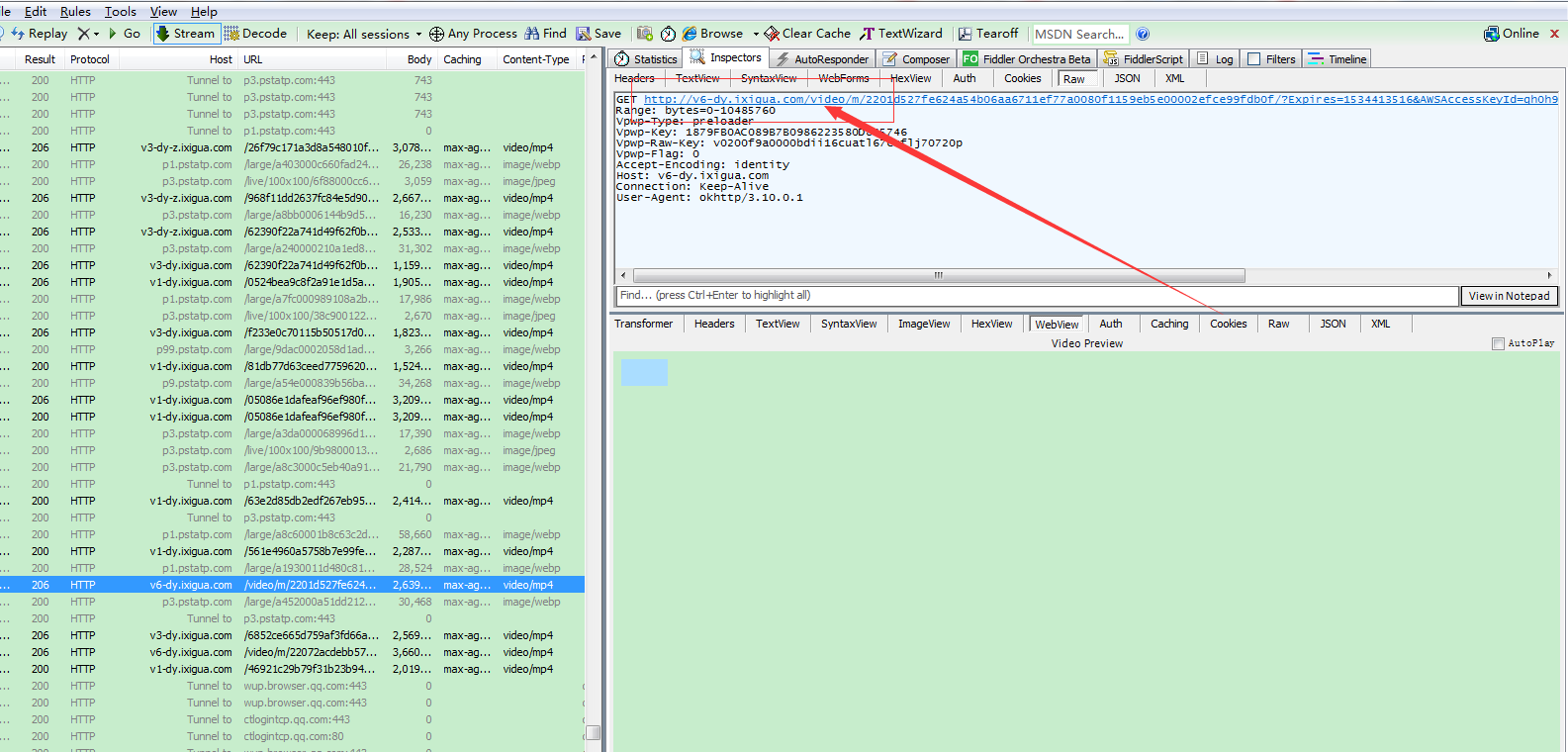
Expires=1536737310,這個是時間戳,標記的是過期的時間如下圖所示,過了15:28分30秒,則表示url不能使用,樓主算了一下,url有效期是一個小時。

看到這些url,樓主不能手動一個一個貼上,so樓主使用如下程式碼,自動儲存到一個txt文件中。
//儲存到本地新增開始 //這是抖音的地址||"v1-dy.ixigua.com"||"v3-dy.ixigua.com"||"v6-dy.ixigua.com"||"v9-dy.ixigua.com"|| if (oSession.fullUrl.Contains("v1-dy.ixigua.com")|| oSession.fullUrl.Contains("v3-dy.ixigua.com")|| oSession.fullUrl.Contains("v6-dy.ixigua.com")|| oSession.fullUrl.Contains("v9-dy.ixigua.com")){ var fso; var file; fso = new ActiveXObject("Scripting.FileSystemObject"); //檔案儲存路徑,可自定義 file = fso.OpenTextFile("H:\\Request.txt",8 ,true); //file.writeLine("Request-url:" + oSession.url); file.writeLine("http://"+oSession.url) //file.writeLine("Request-host:" + oSession.host); //file.writeLine("Request-header:" + "\n" + oSession.oRequest.headers); //file.writeLine("Request-body:" + oSession.GetRequestBodyAsString()); //file.writeLine("\n"); file.close(); } //儲存到本地新增結束
把上邊的程式碼插入到如下圖所示的地方即可。
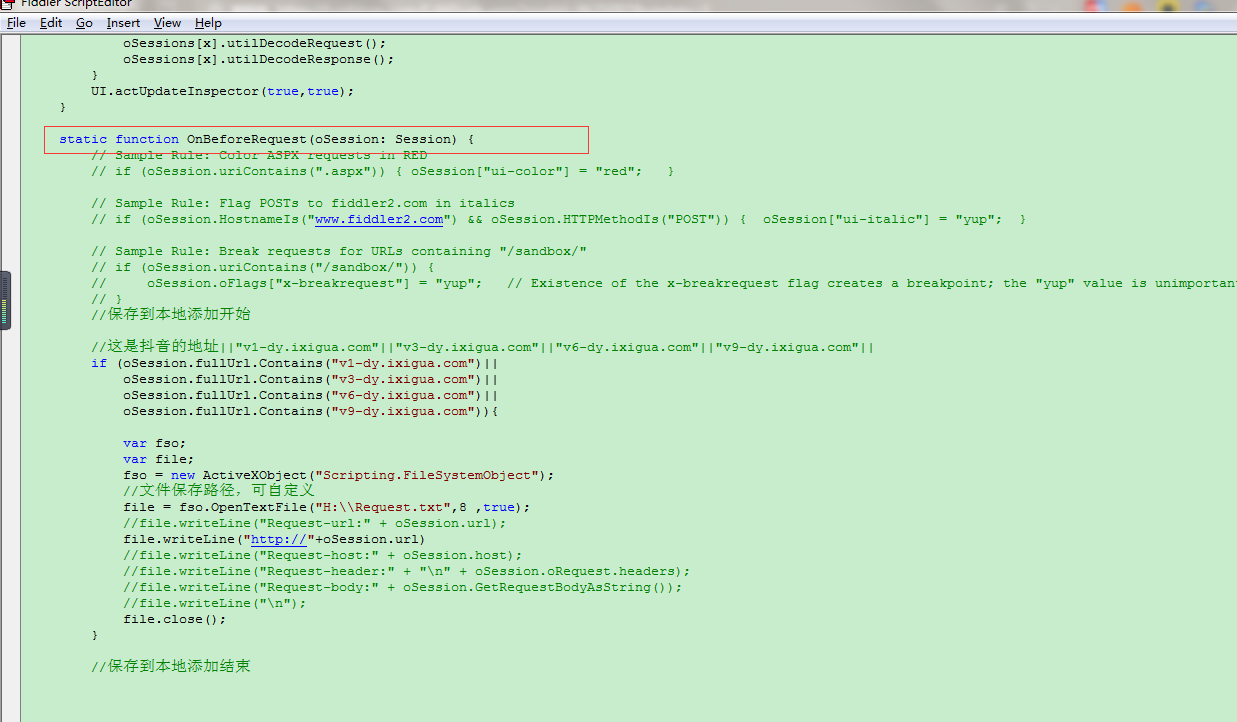
2.上面的url是樓主手動點選一個個重新整理抖音app出現的,so樓主使用appium來自動重新整理抖音app,自動獲得url,自動儲存到txt文件中。
首先需要在appium中得到抖音這個app包的一些用的資訊,如下圖所示

樓主使用的是紅米手機,至於appium怎麼安裝配置,大家可參考網上相關教程,appium客戶端連線上手機(需要資料線連線)後,在控制檯打印出log日誌檔案,在日誌檔案中找到這四個引數即可,然後儲存
到appium客戶端中即可,就能在appium客戶端中操作抖音app。
{ "platformName": "Android", "deviceName": "Redmi Note5", "appPackage": "com.ss.android.ugc.aweme", "appActivity": ".main.MainActivity"}
appPackage這一項com.ss.android.ugc.aweme 則表示抖音短視訊。

![]()
樓主使用如下程式碼來實現無限重新整理抖音app,前提是需要手機連著資料線連在電腦上。
from appium import webdriver from time import sleep ##以下程式碼可以操控手機app class Action(): def __init__(self): # 初始化配置,設定Desired Capabilities引數 self.desired_caps = { "platformName": "Android", "deviceName": "Mi_Note_3", "appPackage": "com.ss.android.ugc.aweme", "appActivity": ".main.MainActivity" } # 指定Appium Server self.server = 'http://localhost:4723/wd/hub' # 新建一個Session self.driver = webdriver.Remote(self.server, self.desired_caps) # 設定滑動初始座標和滑動距離 self.start_x = 500 self.start_y = 1500 self.distance = 1300 def comments(self): sleep(3) # app開啟之後點選一次螢幕,確保頁面的展示 self.driver.tap([(500, 1200)], 500) def scroll(self): # 無限滑動 while True: # 模擬滑動 self.driver.swipe(self.start_x, self.start_y, self.start_x, self.start_y - self.distance) # 設定延時等待 sleep(5) def main(self): self.comments() self.scroll() if __name__ == '__main__': action = Action() action.main()
樓主執行次程式碼就能在Fiddler4中得到無限量的url。3.樓主拿到url後,會發現有些url會重複,so樓主加入了去重的功能,為了好看樓主也加入了進度條花裡花哨的功能,執行程式碼最終會下載下來。
# _*_ coding: utf-8 _*_ import requests import sys headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36" } ##去重方法 def distinct_data(): ##讀取txt中文件的url列表 datalist_blank=[] pathtxt='H:/Request.txt' with open(pathtxt) as f: f_data_list=f.readlines()#d得到的是一個list型別 for a in f_data_list: datalist_blank.append(a.strip())#去掉\n strip去掉頭尾預設空格或換行符 # print(datalist) data_dict={} for data in datalist_blank: #print(type(data),data,'\n') #print(data.split('/'),'\n',data.split('/').index('m'),'\n') #url中以/為切分,在以m為切分 ##把m後面的值放進字典key的位置,利用字典特性去重 if int(data.split('/').index('m'))==4 :#此處為v6開頭的url #print(data,44,data.split('/')[5]) data_key1=data.split("/")[5] data_dict[data_key1]=data elif int(data.split('/').index('m'))==6: #此處為v1或者v3或者v9開頭的url #print(data,66,data.split('/')[7],type(data.split('/')[7])) data_key2=data.split("/")[7] data_dict[data_key2] =data #print(len(data_dict),data_dict) data_new=[] for x,y in data_dict.items(): data_new.append(y) return data_new def responsedouyin(): data_url=distinct_data() # 使用request獲取視訊url的內容 # stream=True作用是推遲下載響應體直到訪問Response.content屬性 # 將視訊寫入資料夾 num = 1 for url in data_url: res = requests.get(url,stream=True,headers=headers) #res = requests.get(url=url, stream=True, headers=headers) #定義視訊存放的路徑 pathinfo = 'H:/douyin-video/%d.mp4' % num #%d 用於整數輸出 %s用於字串輸出 # 實現下載進度條顯示,這一步需要得到總視訊大小 total_size = int(res.headers['Content-Length']) #print('這是視訊的總大小:',total_size) #設定流的起始值為0 temp_size = 0 if res.status_code == 200: with open(pathinfo, 'wb') as file: #file.write(res.content) #print(pathinfo + '下載完成啦啦啦啦啦') num += 1 #當流下載時,下面是優先推薦的獲取內容方式,iter_content()函式就是得到檔案的內容,指定chunk_size=1024,大小可以自己設定喲,設定的意思就是下載一點流寫一點流到磁碟中 for chunk in res.iter_content(chunk_size=1024): if chunk: temp_size += len(chunk) file.write(chunk) file.flush() #重新整理快取 #############下載進度條部分start############### done = int(50 * temp_size / total_size) #print('百分比:',done) sys.stdout.write("\r[%s%s] %d % %" % ('█' * done, ' ' * (50 - done), 100 * temp_size / total_size)+" 下載資訊:"+pathinfo + "下載完成啦啦啦啦啦") sys.stdout.flush()#重新整理快取 #############下載進度條部分end############### print('\n')#每一條列印在螢幕上換行輸出 if __name__ == '__main__': responsedouyin()
執行程式碼,效果圖如下

視訊最終儲存到資料夾中