
爬蟲資料的獲取
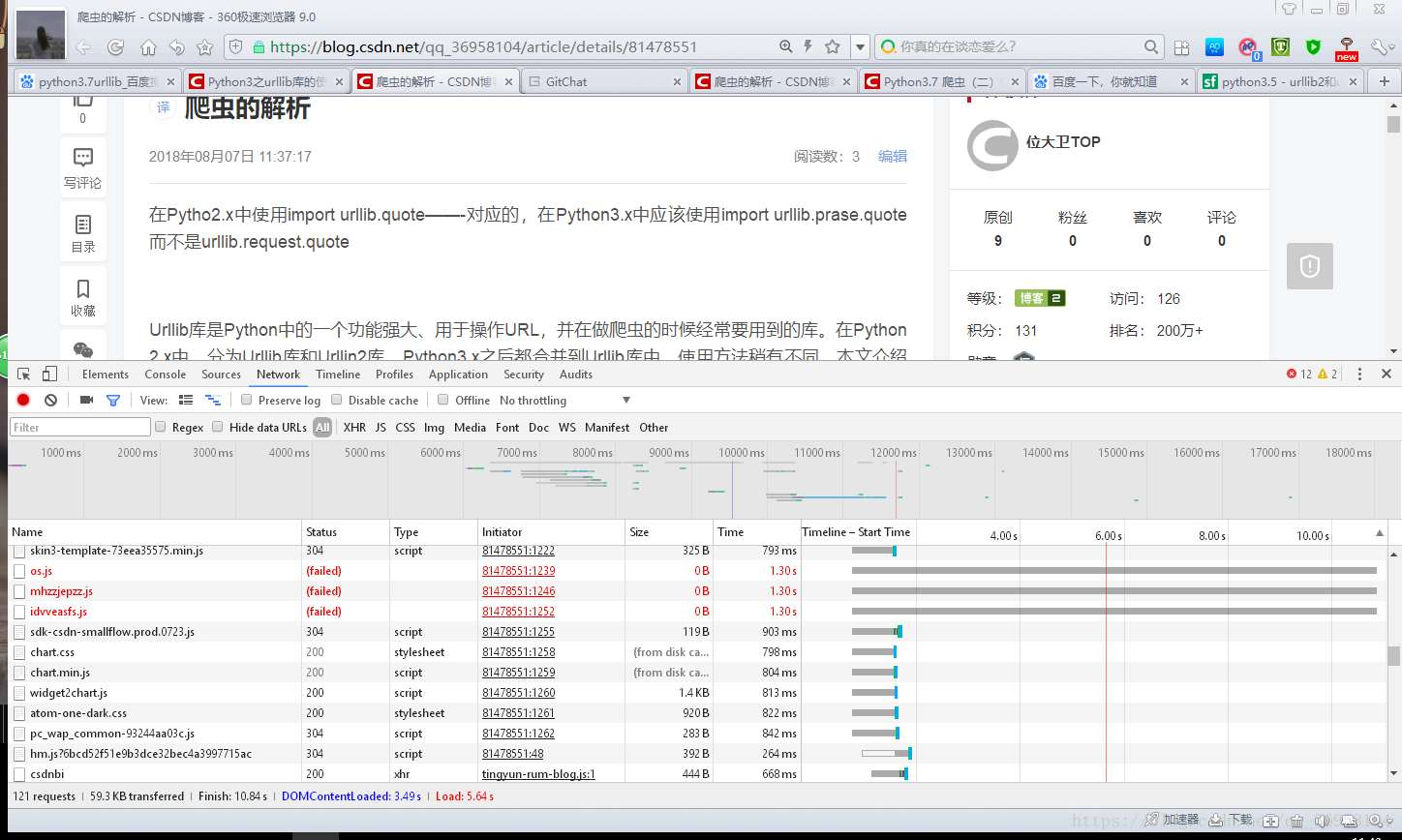
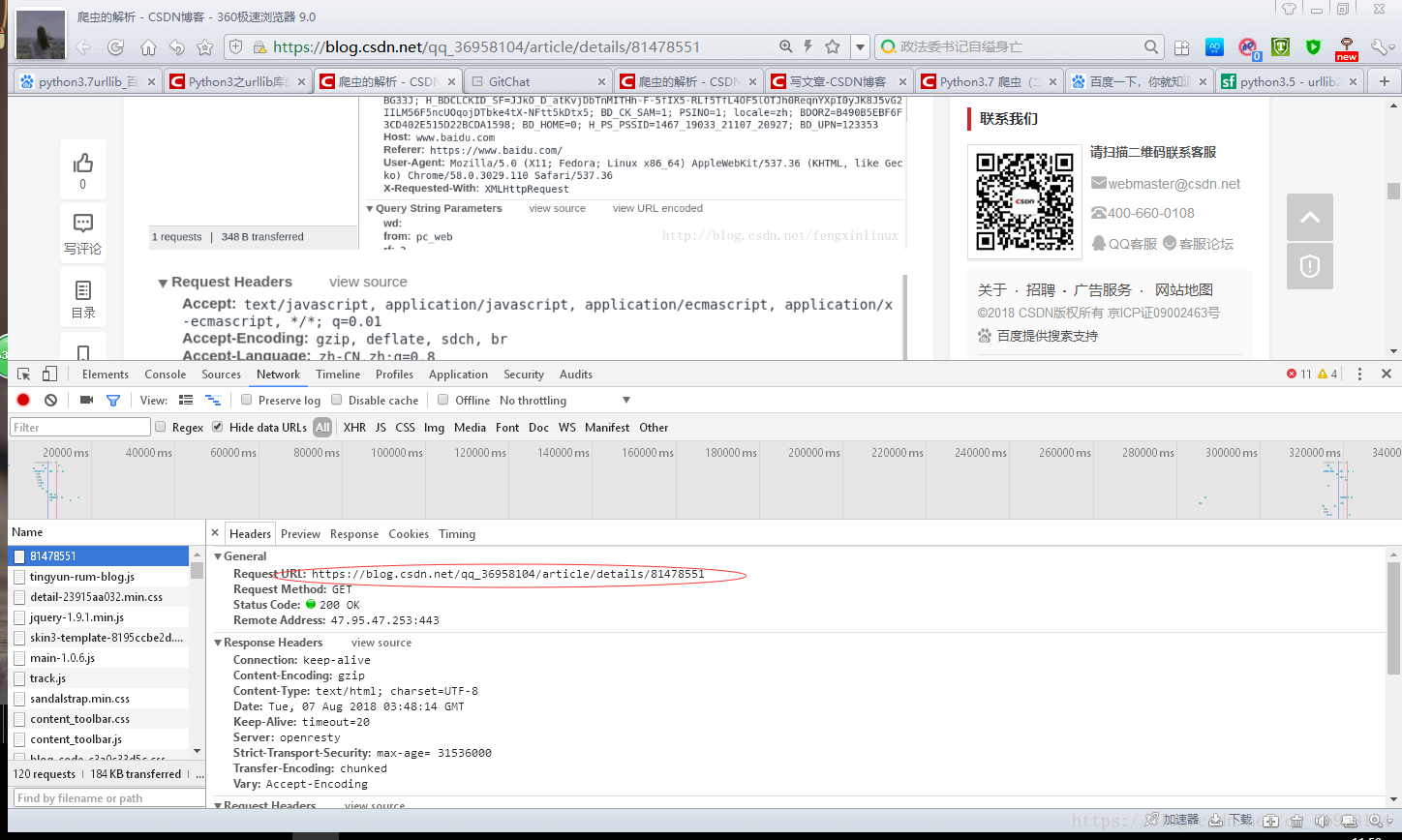
我們學會了使用爬蟲當然少不了網頁的解析,首先我們開啟一個瀏覽器輸入你選好的網站,按下F12可以檢視網頁的內容和我們想要的報頭,但是很不幸的是你開啟之後發現沒有資料,如下所示
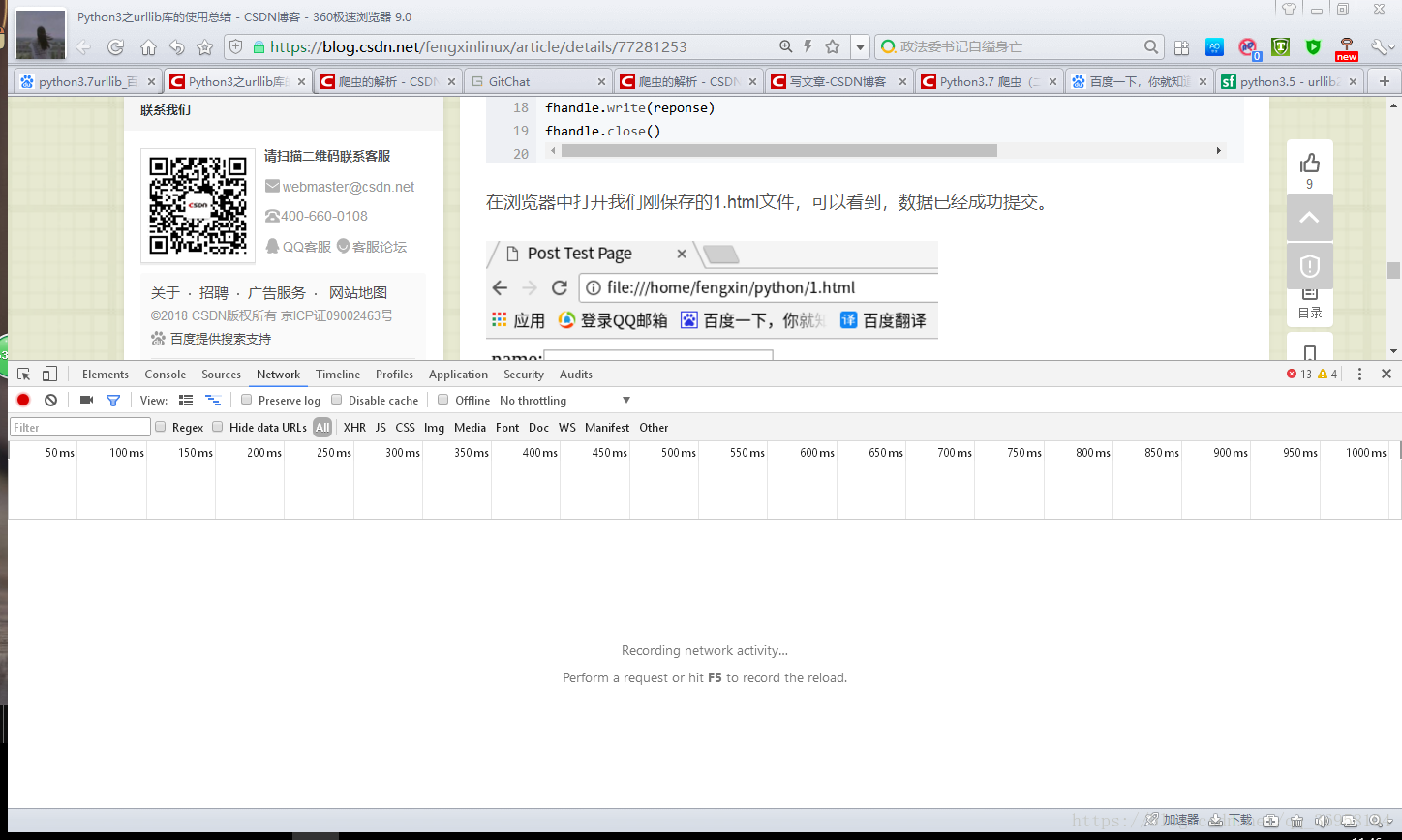
這是由於你沒有重新整理,你點選重新整理之後就出現了資料

相關推薦
爬蟲資料的獲取
我們學會了使用爬蟲當然少不了網頁的解析,首先我們開啟一個瀏覽器輸入你選好的網站,按下F12可以檢視網頁的內容和我們想要的報頭,但是很不幸的是你開啟之後發現沒有資料,如下所示 這是由於你沒有重新整理,你點選重新整理之後就出現了資料
爬蟲 網頁 資料獲取規則
python 正則中re 模組有兩種方式 pattern = re.compile(r"\d") m = pattern.match() 從起始位置開始查詢 返回第一個符合規則的物件 pattern.search() 從任何位置向後查詢 返回第一個符合規則的物件
[Python爬蟲] 爬蟲例項:獲取政府網站公示資料並儲存到MongoDB資料庫
前言 在上一篇文章 https://blog.csdn.net/xHibiki/article/details/84134554 中,我們介紹了Mongo資料庫以及管理工具Studio3T和admin
【ML專案】基於網路爬蟲和資料探勘演算法的web招聘資料分析(一)——資料獲取與處理
前言 這個專案是在學校做的,主要是想對各大招聘網站的招聘資料進行分析,沒準能從中發現什麼,這個專案週期有些長,以至於在專案快要結束時發現網上已經有了一些相關的專案,我後續會把相關的專案材料放在我的GitHub上面,連結為:https://github.com/
python爬蟲--自動獲取seebug的poc
nowait 位數 完成 再次 問題 reading use odi html 簡單的寫了一個爬取www.seebug.org上poc的小玩意兒~ 首先我們進行一定的抓包分析 我們遇到的第一個問題就是seebug需要登錄才能進行下載,這個很好處理,只需要抓取返回值200
量化交易入門筆記-資料獲取函式 二
gt_fundamentals() 函式 該函式可查詢一隻股票或多隻股票的財務資料,其語法如下: get_fundamentals(query_object, date=None, statDate=None) 引數解析: query_object : 這是
量化交易入門筆記-資料獲取函式 一
history()函式 history()獲取歷史資料,可查詢多個標的單個數據欄位,返回資料格式為 DataFrame 或 Dict(字典),其語法格式如下: history(count, unit='1d', field='avg',
爬蟲資料儲存為csv檔案時,表格中間隔有空行問題
問題描述:將爬取的資料儲存的csv檔案,遇到幾個問題,原始碼如下: with open('F:\\Pythontest1\\douban.csv','w') as f: writer = csv.writer(f,dialect='excel') writer.writero
基於HTTP協議的幾種實時資料獲取技術(轉)
轉載自五月的倉頡 HTTP協議 HTTP協議是建立在TCP協議上的應用層協議,協議的本質是請求----應答: 即對於HTTP協議來說,服務端給一次響應後整個請求就結束了,這是HTTP請求最大的特點,也是由於這個特點,HTTP請求無法做到的是服務端向客戶端主動推送資料。 但由於H
python 12306 車次資料獲取
ssl._create_default_https_context = ssl._create_default_https_context train_data = '2018-10-20' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.
python 爬蟲資料存入csv格式方法
python 爬蟲資料存入csv格式方法 命令儲存方式:scrapy crawl ju -o ju.csv 第一種方法:with open("F:/book_top250.csv","w") as f: f.write("{},{},{},{},{}\n".format(book_name
[Python] [爬蟲] 8.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲——資料推送模組
目錄 1.Intro 2.Source (1)dataPusher (2)dataPusher_HTML 1.Intro 檔名:dataPusher.py、dataPusher_HTML.py 模組名:資料推送模組 引用庫: smtpl
[Python] [爬蟲] 7.批量政府網站的招投標、中標資訊爬取和推送的自動化爬蟲——資料處理器
目錄 1.Intro 2.Source 1.Intro 檔名:dataDisposer.py 模組名:資料處理器 引用庫: pymongo datetime time sys
GreenDao網路網路資料獲取存貯本地
GreenDao 3.2.2 的使用 1、在專案的build下新增 classpath 'org.greenrobot:greendao-gradle-plugin:3.2.2' 2、在ap
python爬蟲資料處理
資料處理的兩種方式 re正則表示式:通過對資料文字進行匹配,來得到所需的資料 BeautifulSoup:通過該類建立一個物件,通過對類裡面封裝的方法進行呼叫,來提取資料。 bs4 對標籤進行查詢 獲取標籤的內容 import re fr
Hadoop實現MR程式模擬實現天氣資料獲取兩次最高溫度
資料 1949-10-01 14:21:02 34c 1949-10-01 19:21:02 38c 1949-10-02 14:01:02 36c 1950-01-01 11:21:02 32c 1950-10-01 12:21:02 37c 1951-12-01 12:21:02
React中Form表單資料獲取
const { getFieldDecorator } = this.props.form; this.getFieldsValue = this.props.form.getFieldsValue;//獲得表單所有控制元件的值 this.props.form.getFieldsValue(
Python elasticsearch 匯入json檔案資料 + 將scrapy爬蟲資料直接存入elasticsearch
1、json檔案資料存入elasticsearch json檔案是從網上爬下來的資料 scrapy 儲存的json格式資料預設Unicode格式編碼,轉utf-8 格式需要在settings裡面加入一條: FEED_EXPORT_ENCODING
爬蟲資料節點操所-----XML、LXML、xpath
目錄 前言 什麼是XML XML 和 HTML 的區別 XML文件示例 XML的節點關係 什麼是XPath? XPath 開發工具 選取節點 謂語(Predicates) 選取未知節點 選取若干路徑 什麼是lxml? 初步使用 檔案讀取:
爬蟲資料的儲存
1,Json class JsonWithEncodingPipeline(object): #自定義json檔案的匯出 def __init__(self): self.file = codecs.open('article.json', 'w', e