
Linux網路程式設計---深刻理解5種基本IO模型
Linux五種IO模型
理解這五種I/O模型之前,我們得先清楚一個IO事件發生,它會經歷哪些步驟:
對於一個網路IO(network IO) (這裡我們以read舉例),它會涉及到兩個系統物件,一個是呼叫這個IO的process (or thread),另一個就是系統核心(kernel)。當一個read操作發生時,它會經歷兩個階段:
1 等待資料準備 (Waiting for the data to be ready)
2 將資料從核心拷貝到程序中 (Copying the data from the kernel to the process)
記住這兩點很重要,因為這些IO Model的區別就是在兩個階段上各有不同的情況。
並且我們要知道,在Linux中,預設情況下所有的socket都是阻塞的。
1.阻塞IO( blocking IO)
當kernel沒有資料可讀時,IO呼叫一直阻塞,直到kernel有資料時,將資料從kernel拷貝到使用者空間,在此期間,等待資料的過程和拷貝資料的過程IO都是一直阻塞的,完成資料拷貝之後,才會解除阻塞,IO呼叫才返回。
舉個例子:
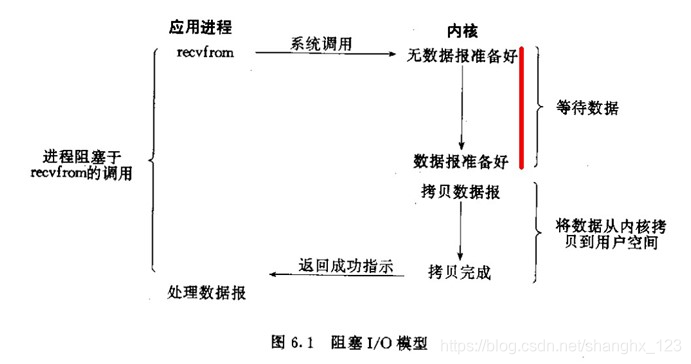
當用戶程序呼叫了recvfrom這個系統呼叫,kernel就開始了IO的第一個階段:準備資料。對於network io來說,很多時候資料在一開始還沒有到達(比如,還沒有收到一個完整的UDP包),這個時候kernel就要等待足夠的資料到來。而在使用者程序這邊,整個程序會被阻塞。當kernel一直等到資料準備好了,它就會將資料從kernel中拷貝到使用者記憶體,然後kernel返回結果,使用者程序才解除block的狀態,重新執行起來。
所以,blocking IO的特點就是在IO執行的兩個階段都被block了。
2.非阻塞IO
當kernel無資料可讀時,IO操作立即返回error,這時不會阻塞。並且一直輪詢,當有資料可讀時,將資料從kernel拷貝到使用者空間,返回成功(拷貝過程仍然阻塞)。但需要使用者程序輪詢核心,直到讀取到資料。
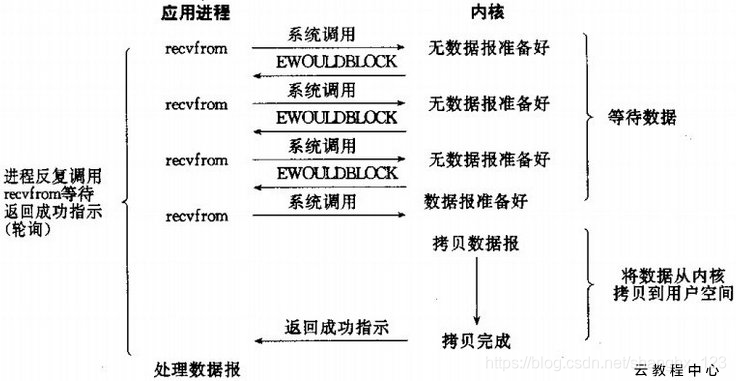
從圖中可以看出,當用戶程序發出read操作時,如果kernel中的資料還沒有準備好,那麼它並不會block使用者程序,而是立刻返回一個error。從使用者程序角度講 ,它發起一個read操作後,並不需要等待,而是馬上就得到了一個結果。使用者程序判斷結果是一個error時,它就知道資料還沒有準備好,於是它可以再次傳送read操作。一旦kernel中的資料準備好了,並且又再次收到了使用者程序的system call,那麼它馬上就將資料拷貝到了使用者記憶體,然後返回。
所以,使用者程序其實是需要不斷的主動詢問kernel資料好了沒有。並且在這個過程中,只有在資料拷貝到時候會阻塞,其他時間都不是阻塞。
3.IO多路複用 (IO multiplexing)
IO多路複用機制(有些地方也稱這種IO方式為event driven IO)有多種方式,分為select、poll、和epoll三種。但poll已經不常用了。它的作用是監控多個檔案描述符,將多個IO阻塞複用到一個select或epoll的阻塞上。select/epoll的好處就在於單個process就可以同時處理多個網路連線的IO。它的基本原理就是select/epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有資料到達了,就通知使用者程序。它的流程如圖:
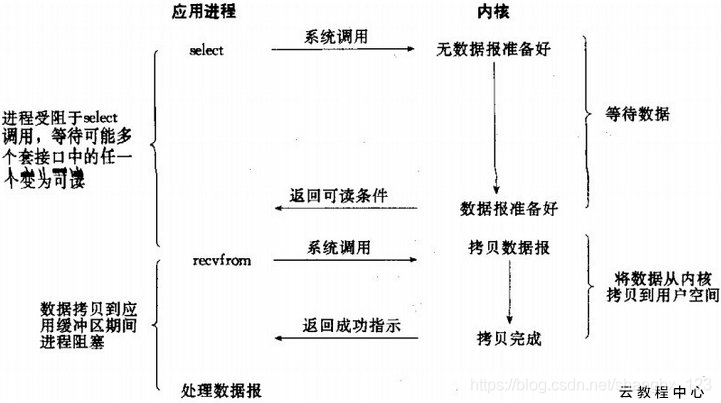
當用戶程序呼叫了select,那麼整個程序會被block,而同時,kernel會“監視”所有select負責的socket,當任何一個socket中的資料準備好了,select就會返回。這個時候使用者程序再呼叫read操作,將資料從kernel拷貝到使用者程序。
這個圖和blocking IO的圖其實並沒有太大的不同,事實上,還更差一些。因為這裡需要使用兩個system call (select 和 recvfrom),而blocking IO只調用了一個system call (recvfrom)。但是,用select的優勢在於它可以同時處理多個connection。(所以,如果處理的連線數不是很高的話,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server效能更好,可能延遲還更大。select/epoll的優勢並不是對於單個連線能處理得更快,而是在於能處理更多的連線。)
在IO 多路複用模型中,實際中,對於每一個socket,一般都設定成為non-blocking,但是,如上圖所示,整個使用者的process其實是一直被block的。只不過process是被select這個函式block,而不是被socket IO給block。
4.同步IO(synchronous IO)
同步,可以理解為在執行完一個函式或呼叫後,一直等待系統的返回值或訊息,這時程序是處於阻塞的,只有接收到返回的值或訊息程序才往下執行。說白了,就是如果程序沒有完成功能,程序就會一直阻塞,直到完成這個功能。 對於上面select來說,使用者程序呼叫select這個系統呼叫後,如果當前沒有準備好的資料報(不具備條件完成功能)則一直阻塞等待,直到有準備好的資料報,這時核心將成功資訊返回給select後才返回(完成功能後返回),程序這時才會解除阻塞。
5.非同步IO(Asynchronous IO)
發出非同步IO後,IO操作立即返回,使用者程序這時就可以去做別的事情了,之後的一切工作都又核心來完成。當kernel有資料可讀時,核心自動將資料拷貝到使用者空間 (不阻塞使用者程序),拷貝完成後向用戶程序傳送訊號。
linux下的asynchronous IO其實用得很少。先看一下它的流程:
舉例:
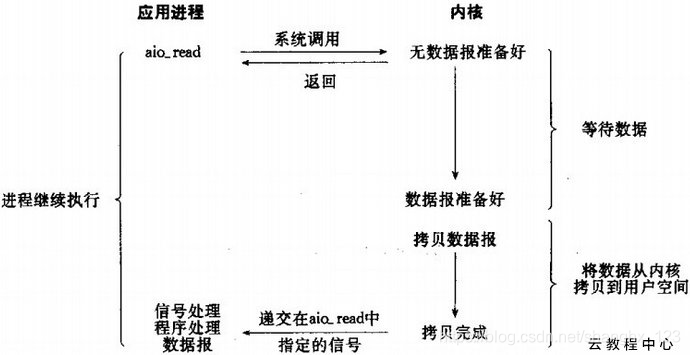
使用者程序發起read操作之後,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之後,首先它會立刻返回,所以不會對使用者程序產生任何block。然後,kernel會等待資料準備完成,然後將資料拷貝到使用者記憶體,當這一切都完成之後,kernel會給使用者程序傳送一個signal,告訴它read操作完成了。
6.訊號驅動IO(signal driven IO)
提前設定或註冊IO相關訊號,核心在描述符就緒時傳送SIGIO訊號,當前程序收到訊號的時候,就意味著當前已經具備IO條件,接下來直接發起呼叫,拷貝資料 。在實際應用中並不常用,所以不過多介紹。
Q:阻塞IO(blocking)和非阻塞IO(non-blocking)的區別在哪?
呼叫blocking IO會一直block住對應的程序直到操作完成,而non-blocking IO在kernel還準備資料的情況下會立刻返回。
阻塞與非阻塞說的是發起呼叫後是否能夠立即返回—返回的時間不同
同步IO(synchronous)和非同步IO(asynchronous)的區別在哪?
同步非同步說的是發起呼叫後是否能夠立即完成功能—完成功能的時間不同
兩者的區別就在於同步 IO做”IO操作”的時候會將process阻塞。而非同步不會。按照這個定義,之前所述的阻塞 IO,非阻塞 IO,IO 多路複用都屬於同步 IO。
有人可能會說,非阻塞 IO並沒有被block啊。這裡有個非常“狡猾”的地方,定義中所指的”IO operation”是指真實的IO操作,就是例子中的recvfrom這個system call。non-blocking IO在執行recvfrom這個system call的時候,如果kernel的資料沒有準備好,這時候不會block程序。但是,程序會一直輪詢,當kernel中資料準備好的時候,recvfrom會將資料從kernel拷貝到使用者記憶體中,在這段時間內,程序是被block的。也就是說,它會等到程序完成IO操作之後,才會徹底解除阻塞(這時就不需要再輪詢了);而非同步IO則不一樣,當程序發起IO 操作之後,就直接返回再也不理睬了,之後的事情就不用使用者程序管了,而之後等待描述符就緒,和拷貝資料是直接讓核心操作,直到kernel傳送一個訊號,告訴程序說IO完成。而在這整個過程中,程序完全沒有被block。
Q:非阻塞IO(non-blocking)和非同步IO(asynchronous IO)的區別。
在非阻塞 IO中,雖然程序大部分時間都不會被block,但是它仍然要求程序去主動的輪詢(check),並且當資料準備完成以後,也需要程序主動的再次呼叫recvfrom來將資料拷貝到使用者記憶體。
而非同步IO則完全不同。它就像是使用者程序將整個IO操作交給了他人(kernel)完成,然後他人做完後發訊號通知。在此期間,使用者程序不需要去檢查IO操作的狀態,也不需要主動的去拷貝資料。
資料參考:https://blog.csdn.net/historyasamirror/article/details/5778378