
ELK在大資料的應用
圈子裡關於大資料、雲端計算相關文章和討論是越來越多,愈演愈烈。行業內企業也爭前恐後,群雄逐鹿。而在大資料時代的運維挑站問題也就日漸突出,任重而道遠了。本文旨在針對複雜的大資料運維繫統推薦一把利器,達到拋磚引玉的效果,如果文中出現任何紕漏和錯誤的地方,懇請指正,歡迎討論,希望大家不吝賜教。
眾所周知,大資料平臺元件是很複雜的。筆者之前接觸的一個大資料平臺解決方案,僅平臺元件就達20多個,這還沒有加上物聯網系統各元件。而這龐大的系統整合問題,對於運維來說是很頭疼的。所以,在大資料時代下的運維問題是日漸尖銳。
有人把運維比作醫生給病人看病,那麼日誌則是病人對自己的陳述。所以只有在海量分散式日誌系統中有效的提取關鍵資訊,才能對症下藥。如果能把這些日誌集中管理,並提供全文檢索功能,不僅可以提高診斷的效率,同時可以起到實時系統監測、網路安全、事件管理和發現bug等功能。基於此,本文向大家推薦一款開源利器——ELK元件(Apache 2.0 License),提供分散式的實時日誌(資料)蒐集和分析的監控系統。
ELK多種架構及優劣
既然要談ELK在大資料運維繫統中的應用,那麼ELK架構就不得不談。本章節引出四種筆者曾經用過的ELK架構,並討論各種架構所適合的場景和優劣供大家參考。
先大致介紹ELK元件。ELK是Elasticsearch、Logstash、Kibana的簡稱,這三者是核心套件,但並非全部。後文的四種基本架構中將逐一介紹應用到的其它套件。
-
Elasticsearch是實時全文搜尋和分析引擎,提供蒐集、分析、儲存資料三大功能;是一套開放REST和JAVA API等結構提供高效搜尋功能,可擴充套件的分散式系統。它構建於Apache Lucene搜尋引擎庫之上。
-
Logstash是一個用來蒐集、分析、過濾日誌的工具。它支援幾乎任何型別的日誌,包括系統日誌、錯誤日誌和自定義應用程式日誌。它可以從許多來源接收日誌,這些來源包括 syslog、訊息傳遞(例如 RabbitMQ)和JMX,它能夠以多種方式輸出資料,包括電子郵件、websockets和Elasticsearch。
-
Kibana是一個基於Web的圖形介面,用於搜尋、分析和視覺化儲存在 Elasticsearch指標中的日誌資料。它利用Elasticsearch的REST介面來檢索資料,不僅允許使用者建立他們自己的資料的定製儀表板檢視,還允許他們以特殊的方式查詢和過濾資料。
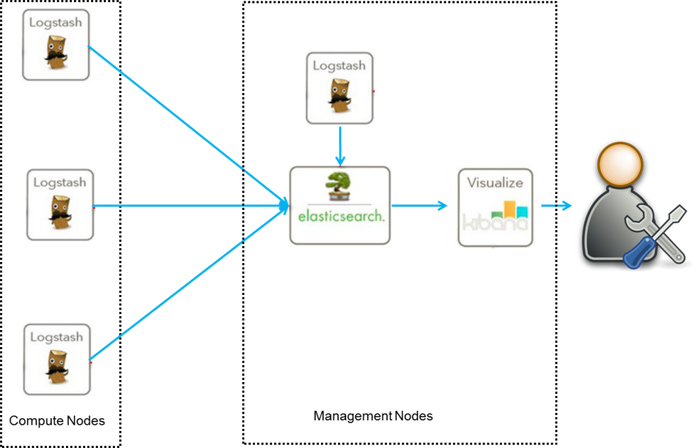
我們先談談第一種ELK架構,如圖1,這是最簡單的一種ELK架構方式。優點是搭建簡單,易於上手。缺點是Logstash耗資源較大,執行佔用CPU和記憶體高。另外沒有訊息佇列快取,存在資料丟失隱患。建議供學習者和小規模叢集使用。
此架構首先由Logstash分佈於各個節點上搜集相關日誌、資料,並經過分析、過濾後傳送給遠端伺服器上的Elasticsearch進行儲存。Elasticsearch將資料以分片的形式壓縮儲存並提供多種API供使用者查詢,操作。使用者亦可以更直觀的通過配置Kibana Web Portal方便的對日誌查詢,並根據資料生成報表(詳細過程和配置在此省略)。
第二種架構(圖2)引入了訊息佇列機制,位於各個節點上的Logstash Agent先將資料/日誌傳遞給Kafka(或者Redis),並將佇列中訊息或資料間接傳遞給Logstash,Logstash過濾、分析後將資料傳遞給Elasticsearch儲存。最後由Kibana將日誌和資料呈現給使用者。因為引入了Kafka(或者Redis),所以即使遠端Logstash server因故障停止執行,資料將會先被儲存下來,從而避免資料丟失。
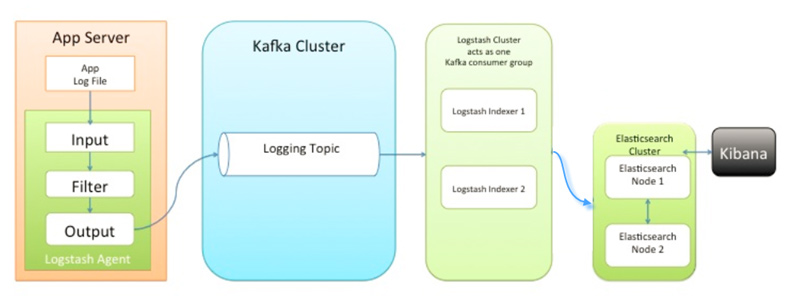
這種架構適合於較大叢集的解決方案,但由於Logstash中心節點和Elasticsearch的負荷會比較重,可將他們配置為叢集模式,以分擔負荷,這種架構的優點在於引入了訊息佇列機制,均衡了網路傳輸,從而降低了網路閉塞尤其是丟失資料的可能性,但依然存在Logstash佔用系統資源過多的問題。
第三種架構(圖3)引入了Logstash-forwarder。首先,Logstash-forwarder將日誌資料蒐集並統一發送給主節點上的Logstash,Logstash分析、過濾日誌資料後傳送至Elasticsearch儲存,並由Kibana最終將資料呈現給使用者。
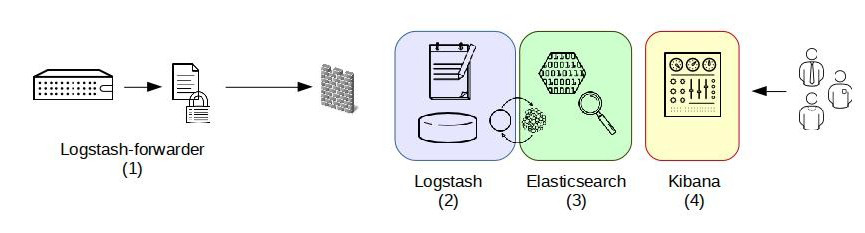
這種架構解決了Logstash在各計算機點上佔用系統資源較高的問題。經測試得出,相比Logstash,Logstash-forwarder所佔用系統CPU和MEM幾乎可以忽略不計。另外,Logstash-forwarder和Logstash間的通訊是通過SSL加密傳輸,起到了安全保障。如果是較大叢集,使用者亦可以如結構三那樣配置logstash叢集和Elasticsearch叢集,引入High Available機制,提高資料傳輸和儲存安全。更主要的配置多個Elasticsearch服務,有助於搜尋和資料儲存效率。但在此種架構下發現Logstash-forwarder和Logstash間通訊必須由SSL加密傳輸,這樣便有了一定的限制性。
第四種架構(圖4),將Logstash-forwarder替換為Beats。經測試,Beats滿負荷狀態所耗系統資源和Logstash-forwarder相當,但其擴充套件性和靈活性有很大提高。Beats platform目前包含有Packagebeat、Topbeat和Filebeat三個產品,均為Apache 2.0 License。同時使用者可根據需要進行二次開發。
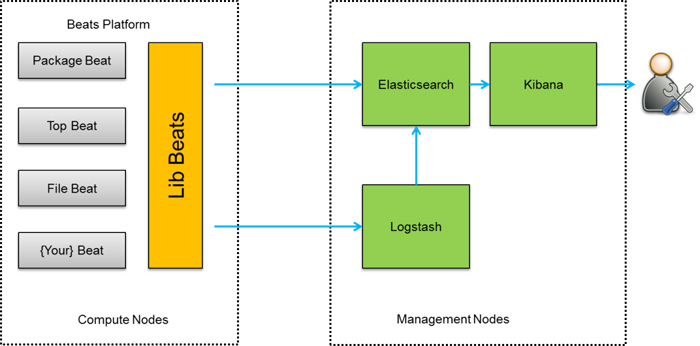
這種架構原理基於第三種架構,但是更靈活,擴充套件性更強。同時可配置Logstash 和Elasticsearch 叢集用於支援大集群系統的運維日誌資料監控和查詢。
不管採用上面哪種ELK架構,都包含了其核心元件,即:Logstash、Elasticsearch 和Kibana。當然這三個元件並非不能被替換,只是就效能和功能性而言,這三個元件已經配合的很完美,是密不可分的。各系統運維中究竟該採用哪種架構,可根據現實情況和架構優劣而定。
ELK在大資料運維繫統中的應用
在海量日誌系統的運維中,以下幾個方面是必不可少的:
-
分散式日誌資料集中式查詢和管理
-
系統監控,包含系統硬體和應用各個元件的監控
-
故障排查
-
安全資訊和事件管理
-
報表功能
ELK元件各個功能模組如圖5所示,它運行於分散式系統之上,通過蒐集、過濾、傳輸、儲存,對海量系統和元件日誌進行集中管理和準實時搜尋、分析,使用搜索、監控、事件訊息和報表等簡單易用的功能,幫助運維人員進行線上業務的準實時監控、業務異常時及時定位原因、排除故障、程式研發時跟蹤分析Bug、業務趨勢分析、安全與合規審計,深度挖掘日誌的大資料價值。同時Elasticsearch提供多種API(REST JAVA PYTHON等API)供使用者擴充套件開發,以滿足其不同需求。
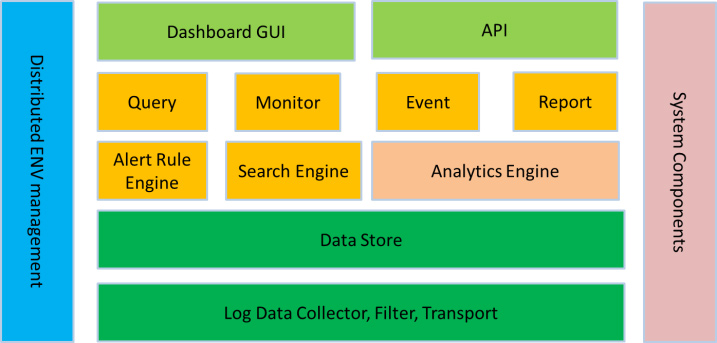
彙總ELK元件在大資料運維繫統中,主要可解決的問題如下:
-
日誌查詢,問題排查,上線檢查
-
伺服器監控,應用監控,錯誤報警,Bug管理
-
效能分析,使用者行為分析,安全漏洞分析,時間管理
綜上,ELK元件在大資料運維中的應用是一套必不可少的且方便、易用的開源解決方案。
ELK實戰舉例
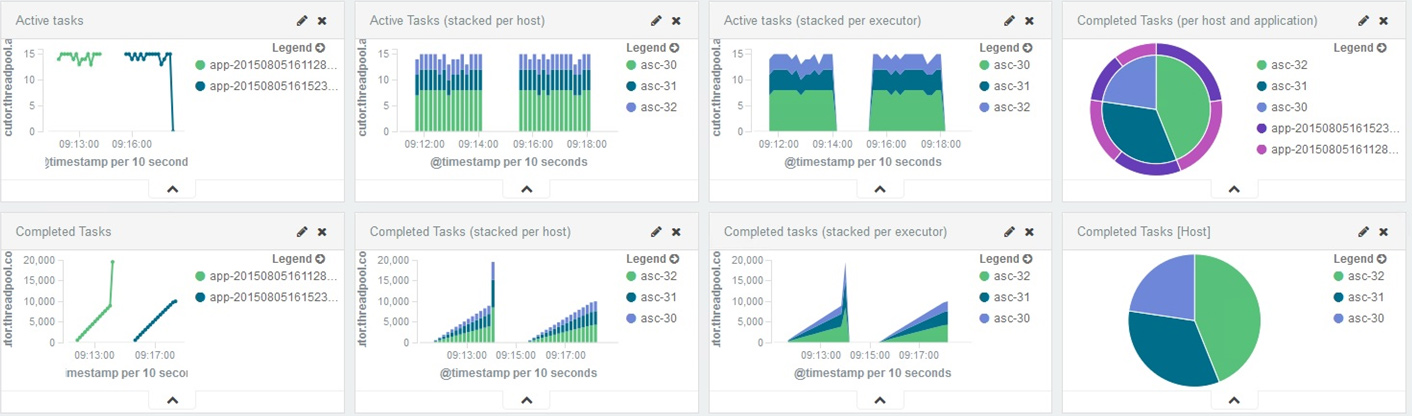
ELK實戰舉例一,通過ELK元件對Spark作業執行狀態監控,蒐集Spark環境下執行的日誌。經過篩選、過濾並存儲可用資訊,從而完成對Spark作業執行和完成狀態進行監控,實時掌握叢集狀態,瞭解作業完成情況,並生成報表,方便運維人員監控和檢視。
資料來源可以是各式各樣的日誌,Logstash配置檔案有三個主要模組:input()輸入或者說收集資料,定義資料來源;filter()對資料進行過濾,分析等操作;output()輸出。input plugin目前支援將近50種,如下表所示:
| Beats | couchdb_changes | Xmpp | eventlog | exec | s3 | file | ganglia | gelf |
|---|---|---|---|---|---|---|---|---|
| Github | Heartbeat | Heroku | http | Sqs | Irc | imap | jdbc | JMX |
| lumberjack | varnishlog | Pipe | snmptrap | generator | Rss | rackspace | RabbitMQ | Redis |
| Sqlite | Elasticsearch | http_poller | Stomp | syslog | TCP | unix | UDP | |
| websocket | drupal_dblog | Zenoss | ZeroMQ | Graphite | Log4j | stdin | wmi | relp |
| Kafka | puppet_facter | Meetup |
資料來源蒐集到後,然後通過filter過濾形成固定的資料格式。目前支援過濾的類JSON、grep、grok、geoip等,最後output到資料庫,比如Redis、Kafka或者直接傳送給Elasticsearch。當資料被儲存於Elasticsearch之後,使用者可以使用Elasticsearch所提供API來檢索資訊資料了,如通過REST API執行CURL GET請求搜尋指定資料。使用者也可以使用Kibana進行視覺化的資料瀏覽。另外Kibana有時間過濾功能,運維人員可對某一時間段內資料查詢並檢視報表,方便快捷。
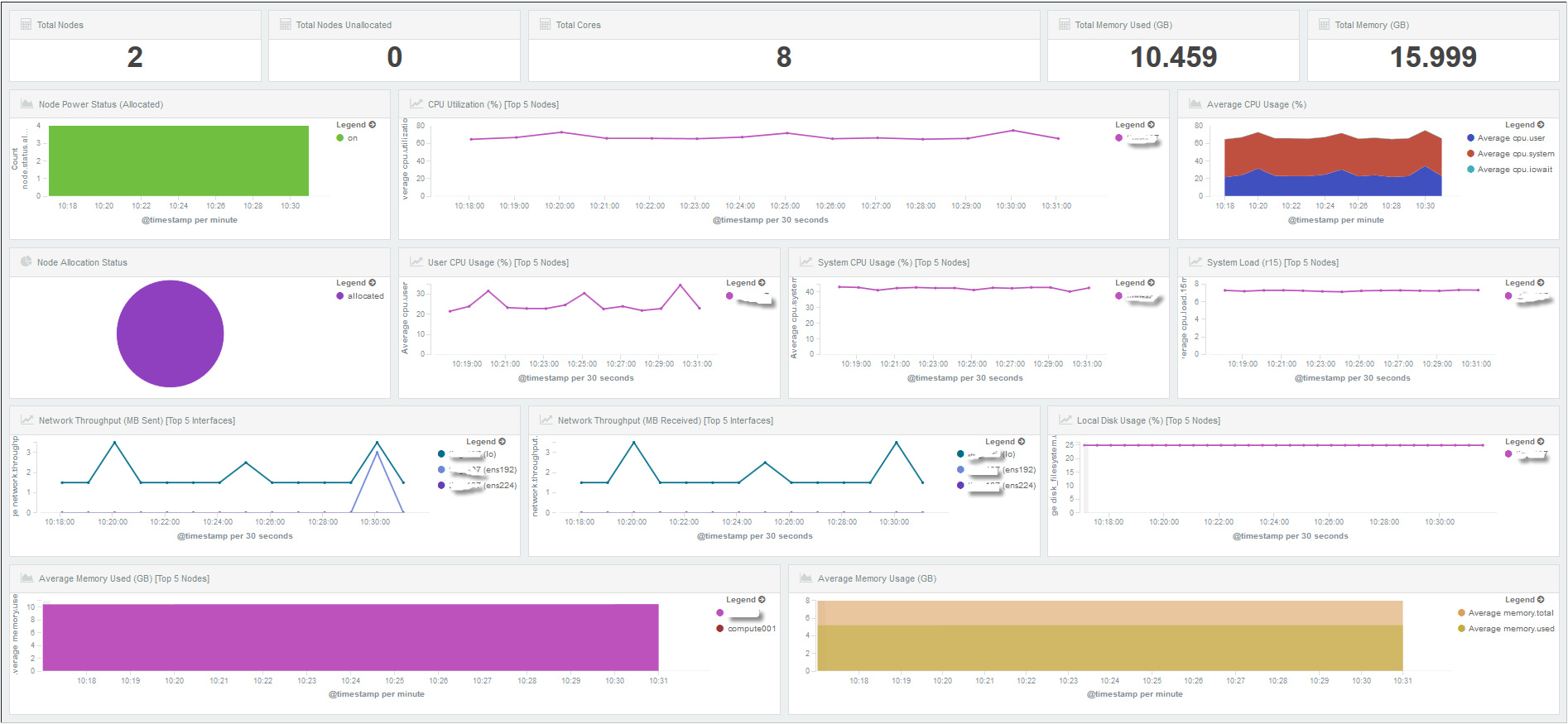
ELK實戰舉例二,通過ELK元件對系統資源狀態監控,如圖7、圖8所示,是筆者前段時間使用ELK元件為叢集提供日誌查詢和系統資源監控的例子。通過各類日誌蒐集,分析,過濾,儲存並通過Kibana展現給使用者,供使用者實時監控系統資源、節點狀態、磁碟、CPU、MEM,以及錯誤、警告資訊等。

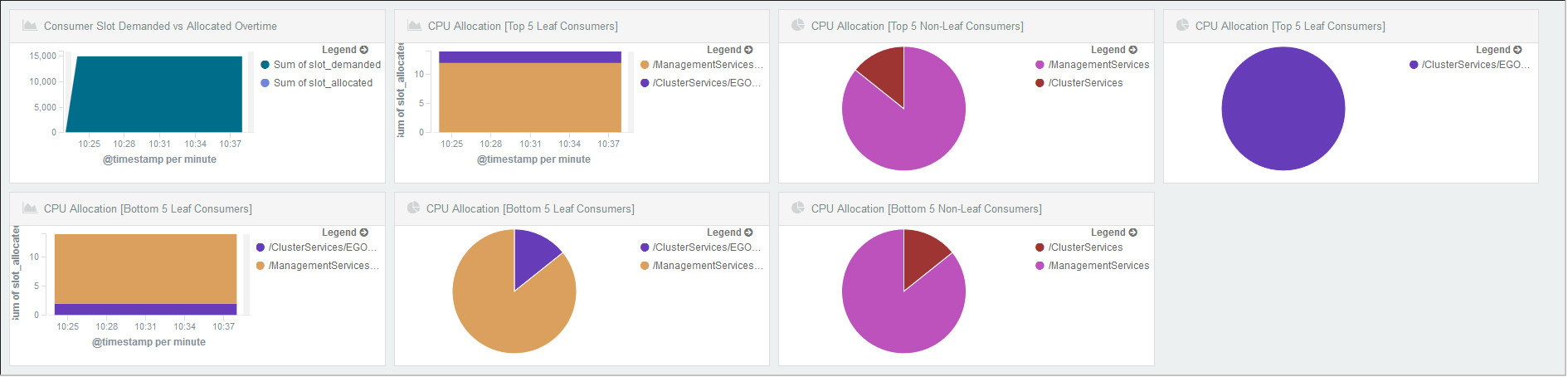
ELK實戰舉例三,通過ELK元件對系統負載狀態監控,如圖9所示。
ELK實戰舉例四,通過ELK元件對系統日誌管理和故障排查,如圖10所示。使用者可根據故障發生時間段集中查詢相關日誌,可通過搜尋、篩選、過濾等功能,快速定位問題,從而排查故障。另外,通過對各個應用元件的日誌過濾,可快速列舉出各個應用對應節點上的Error或Warning日誌,從而對故障排查或者對發現產品bug提供快捷途徑。
結束語
除ELK套件以外,業界關於運維監控產品還有很多,如Splunk、Nagios等。
Splunk是在語句裡生成圖表。而ELK則是使用者在Kibana Web Portal上滑鼠選擇的方式來點出來,相比Splunk來說要簡單得多,使用者不用記住那些語法即可繪製多種Chart。易用性有很大提高。另外,Splunk屬於入庫後對內容的即使處理,比如rex函式等等,而ES是儘量在入庫前,即在Logstash端已經將資料來源實時過濾、分析。提高了資料處理能力。最重要一點,ELK是免費的,Splunk則需要昂貴的費用。
Nagios最大的特點是其強大的管理中心,但看不到歷史資料,很難追查故障原因,而且配置複雜,這些恰恰是ELK元件的優勢所在。
本文所述案例和架構來自於IBM Platform團隊在使用ELK套件中的實戰經歷和工作總結,IBM Platform衝出了ELK套件僅對日誌蒐集的約束,除Logstash所支援input plugin外,還充分利用了Elasticsearch本身所支援多種資料來源輸入,從而增強了資料來源的輸入條件,提高了系統監控範圍,大大提高了ELK的擴充套件性和實用性。
ELK本身對POWER系統,還有IBM JAVA支援有一定侷限性,不過IBM Platform團隊已經將這些問題一一解決,使之可以完美地集成於多個平臺。除此之外,IBM Platform將ELK和IBM Platform Cluster Manager、IBM Platform EGO集成於一體。用於ELK自動部署和管理,有效提高了ELK的部署和管理效率。並對IBM Platform Converge、IBM Platform Conductor(包括Spark)提供監控和Dashboard等功能。
作者簡介
李峰,供職於IBM Platform 多年,從事分散式計算、高效能運算、大資料相關工作,傾向於日誌分析、資料監控等研究。
王佔偉,資深研發工程師,供職於IBM多年,專注於大資料、雲端計算、高效能運算等平臺的日誌分析、資料監控等方面的研發工作。
何金池,畢業於西安郵電大學,目前供職於IBM,工作方向為大資料日誌處理、高效能運算等領域。
李婷,研發工程師,供職於IBM Platform,從事分散式計算、高效能運算、大資料相關工作,對前端開發有較深研究。