
機器學習(七)白化whitening
轉自:https://blog.csdn.net/hjimce/article/details/50864602
原文地址:http://blog.csdn.net/hjimce/article/details/50864602
作者:hjimce
一、相關理論
白化這個詞,可能在深度學習領域比較常遇到,挺起來就是高大上的名詞,然而其實白化是一個比PCA稍微高階一點的演算法而已,所以如果熟悉PCA,那麼其實會發現這是一個非常簡單的演算法。
白化的目的是去除輸入資料的冗餘資訊。假設訓練資料是影象,由於影象中相鄰畫素之間具有很強的相關性,所以用於訓練時輸入是冗餘的;白化的目的就是降低輸入的冗餘性。
輸入資料集X,經過白化處理後,新的資料X'滿足兩個性質:
(1)特徵之間相關性較低;
(2)所有特徵具有相同的方差。
其實我們之前學的PCA演算法中,可能PCA給我們的印象是一般用於降維操作。然而其實PCA如果不降維,而是僅僅使用PCA求出特徵向量,然後把資料X對映到新的特徵空間,這樣的一個對映過程,其實就是滿足了我們白化的第一個性質:除去特徵之間的相關性。因此白化演算法的實現過程,第一步操作就是PCA,求出新特徵空間中X的新座標,然後再對新的座標進行方差歸一化操作。
二、演算法概述
白化分為PCA白化、ZCA白化,下面主要講解演算法實現。這部分主要是學了UFLDL的深度學習《白化》教程:http://ufldl.stanford.edu/wiki/index.php/%E7%99%BD%E5%8C%96。自己的一點概括總結,演算法實現步驟如下:
1、首先是PCA預處理
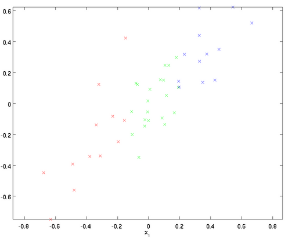
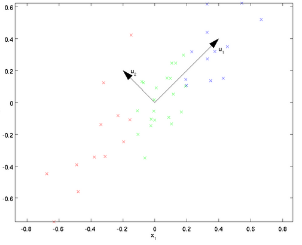
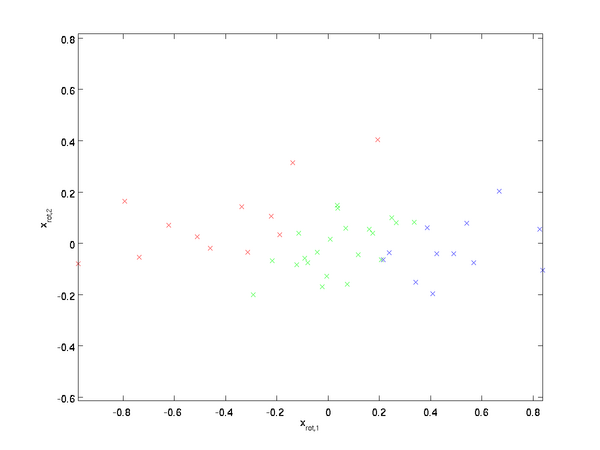
這就是所謂的pca處理。
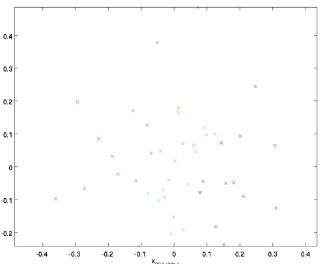
2、PCA白化 所謂的pca白化是指對上面的pca的新座標X’,每一維的特徵做一個標準差歸一化處理。因為從上面我們看到在新的座標空間中,(x1,x2)兩個座標軸方向的資料明顯標準差不同,因此我們接著要對新的每一維座標做一個標註差歸一化處理:
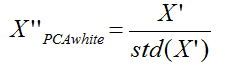
當然你也可以採用下面的公式:
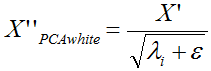
X'為經過PCA處理的新PCA座標空間,然後λi就是第i維特徵對應的特徵值(前面pca得到的特徵值),ε是為了避免除數為0。
3、ZCA白化
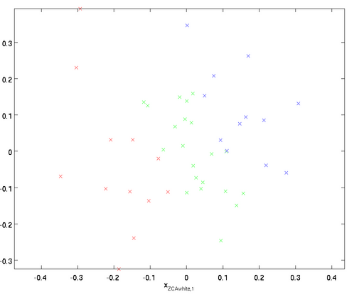
ZCA白虎是在PCA白化的基礎上,又進行處理的一個操作。具體的實現是把上面PCA白化的結果,又變換到原來座標系下的座標:
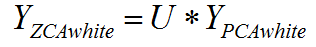
給人的感覺就像是在PCA空間做了處理完後,然後又把它變換到原始的資料空間。
具體原始碼實現如下: -
def zca_whitening(inputs):
sigma = np.dot(inputs, inputs.T)/inputs.shape[1] #inputs是經過歸一化處理的,所以這邊就相當於計算協方差矩陣
U,S,V = np.linalg.svd(sigma) #奇異分解
epsilon = 0.1 #白化的時候,防止除數為0
ZCAMatrix = np.dot(np.dot(U, np.diag(1.0/np.sqrt(np.diag(S) + epsilon))), U.T) #計算zca白化矩陣
return np.dot(ZCAMatrix, inputs) #白化變換
參考文獻: 1、http://ufldl.stanford.edu/wiki/index.php/%E7%99%BD%E5%8C%96 -