
自己用 python 實現 base64 編碼
自己用 python 實現 base64 編碼
base64 編碼原理
二進位制檔案中包含有很多無法顯示和列印的字元,二進位制的資料一般以 ASCII 碼形式(8 bit,即一個位元組)儲存,8 bit 可以表示 128 個不同的編碼,而 ASCII 碼中有 33 個編碼表示的不是顯示或列印的字元:
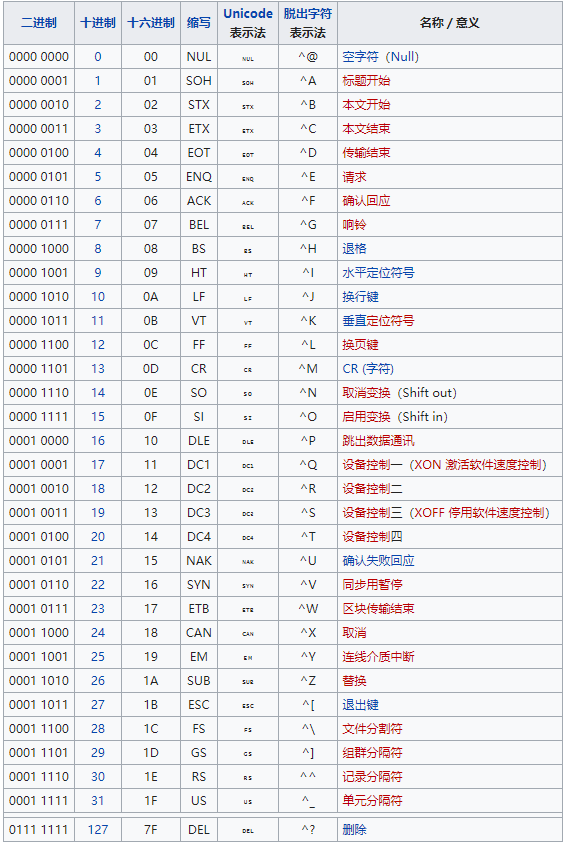
圖片來自維基百科
剩下的編碼表示的是可以列印的字元:

圖片來自維基百科
當處理二進位制檔案中的資料時,就需要將無法顯示或列印的字元進行轉換,Base64 編碼的原理就是將這 128 個不同的編碼(可以列印或不可列印的字元)對映到 64 個可以列印的字符集中。
準備字元陣列/字串
首先準備 64 個可以顯示/列印的字元陣列(字串),可以用 chr 將十進位制資料轉換成相應的字元,然後構造成字元陣列:
def constructTable(): array = [] for i in range( 65, 91 ): array.append( chr( i ) ) for i in range( 97, 123 ): array.append( chr( i ) ) for i in range( 0, 10 ): array.append( str( i ) ) array.append( '+' ) array.append( '-' ) # print( array ) return array
也可以用 string 提供的常量構造出一個字串:
def constructTable2():
str = string.ascii_uppercase + string.ascii_lowercase + string.digits
return str + '+' + '-'兩者取出相應位置的字元都可以用陣列的形式,比如用 table 儲存字元陣列/字串,table[2] 就是 C。
處理資料
接下來對二進位制資料進行處理,每 3 個位元組一組進行處理即可:
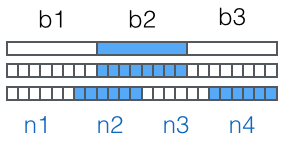
圖片來自廖雪峰的官方教程
只考慮資料位元組數為 3 的情況,將其重新編碼:
def _b64encode_str( s0, s1, s2 ): """ s0、s1、s2 依次為第一、二、三個字元 """ d = s2 & 63 d = array[ d ] c1 = ( s1 & 15 ) << 2 c2 = ( s2 & 192 ) >> 6 c = c1 + c2 c = array[ c ] b1 = ( s0 & 3 ) << 4 b2 = ( s1 & 240 ) >> 4 b = b1 + b2 b = array[ b ] a = ( s0 & 252 ) >> 2 a = array[ a ] return ''.join( [ a, b, c, d ] )
這裡的思路是從右往左,依次計算出 d、c、b、a,也就是對應著上圖的 n4、n3、n2、n1。當要編碼的資料不是 3 的倍數時,需要在資料末尾用 \x00 補足成 3 的倍數,最後根據補 \x00 的次數在編碼後的字串中新增相應個數的 =。
# input is str
length = len( str )
remainder = length % 3
# fill with zero
if( remainder == 1 ):
str = str + b'\x00\x00' # add twice
length += 2
elif( remainder == 2 ):
str = str + b'\x00' # add once
length += 1之後,再將原始資料進行編碼,先考慮簡單的 remainder == 0 的情況,每 3 個字元一組進行編碼即可:
i = 0
buf = StringIO()
while i < length:
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en )
i += 3如果 remainder != 0,那麼最後的三個字元中有新增的 =,這三個字元需要特殊處理,前面的字元和上面的處理方式一樣,在最後返回的時候呼叫字串的 encode 方法將其轉為二進位制:
while i < length - 3:
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en )
i += 3
# print( remainder, i, buf.getvalue() )
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en[ 0 ] )
buf.write( en[ 1 ] )
if( remainder == 2 ):
buf.write( en[ 2 ] ) # add once
buf.write( '=' )
elif( remainder == 1 ):
buf.write( '==' ) # add twice然後編寫一個簡單的測試檔案,簡單驗證下自己編寫的 b64encode 方法是否正確:
def randomString():
# print( chars )
size = random.randint( 70, 100 )
rstr = ''.join( random.SystemRandom().choices( _CHARS, k = size ) )
return rstr.encode()
def compare():
rstr = randomString()
exp = base64.b64encode( rstr )
act = mybase64.b64encode( rstr )
if( exp != act ):
print( rstr )
print( exp )
print( act )
raise ValueError
loops = 10000
print( 'encode comp: ', timeit.timeit( stmt = compare, number = loops ) )按照標準的 Base64 編碼編寫的程式碼沒有問題。
效能比較
最後將 Python 自帶的 base64 編碼和自己編寫的編碼函式進行比較:
def encode1():
rstr = randomString()
base64.b64encode( rstr )
def encode2():
rstr = randomString()
mybase64.b64encode( rstr )
loops = 10000
print( sys.version )
print( 'random: ', timeit.timeit( randomString, number = loops ) )
print( 'encode1: ', timeit.timeit( stmt = encode1, number = loops ) )
print( 'encode2: ', timeit.timeit( stmt = encode2, number = loops ) )輸出結果如下:

小結
可以看到,自己編寫的編碼方法用時大約 0.447 seconds, base64 庫提供的方法的用時約為 0.030 seconds,效能差距約 15 倍。所以一般沒有必要自己實現 base64 編碼。
另外測試中相應的 decode 方法是沒有實現的,實現起來也比較簡單,按照編碼的方式反過來做就好了。
程式碼地址:github
Notable
- python 中 str 物件執行 encode 方法後字串將會以二進位制形式儲存
- chr( 1 ) 返回值是
'\x01',對應的是不可列印的字元,str( 1 ) 返回值是'1',是可以列印的字元。