MapReduce 統計手機使用者的上行流量,下行流量,總流量,並對輸出的結果進行倒序排序。(二),劃分省份,輸出到不同的檔案
阿新 • • 發佈:2018-11-10
在(一)的基礎上,寫一個自己的partitioner就好了。
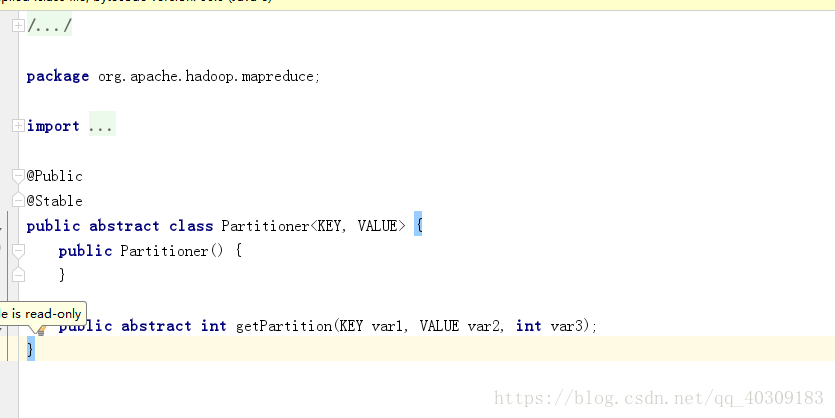
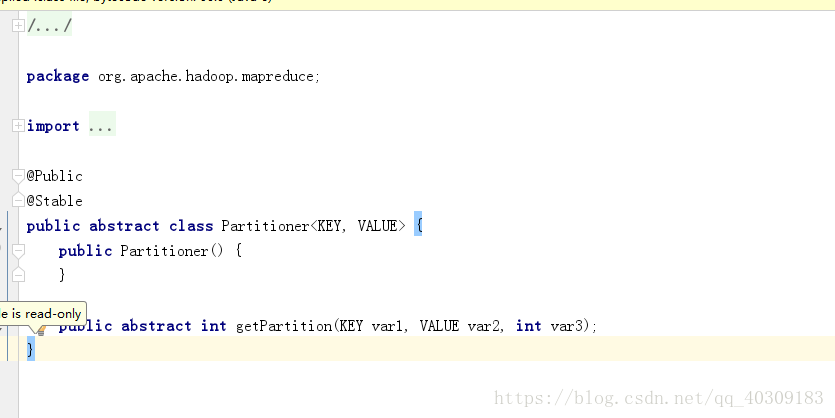
分割槽的預設實現HashPartitioner,它根據key的hashcode和Interger.
在Reduce過程中,可以根據實際需求(比如按某個維度進行歸檔,類似於資料庫的分組),把Map完的資料Reduce到不同的檔案中。分割槽的設定需要與ReduceTaskNum配合使用。比如想要得到5個分割槽的資料結果。那麼就得設定5個ReduceTask。
在進行MapReduce計算時,有時候需要把最終的輸出資料分到不同的檔案中,按照手機號碼段劃分的話,需要把同一手機號碼段的資料放到一個檔案中;按照省份劃分的話,需要把同一省份的資料放到一個檔案中;按照性別劃分的話,需要把同一性別的資料放到一個檔案中。我們知道最終的輸出資料是來自於Reducer任務。那麼,如果要得到多個檔案,意味著有同樣數量的Reducer任務在執行。Reducer任務的資料來自於Mapper任務,也就說Mapper任務要劃分資料,對於不同的資料分配給不同的Reducer任務執行。Mapper任務劃分資料的過程就稱作Partition。負責實現劃分資料的類稱作Partitioner。
我們這裡設定了四個數字,所以在後面設定的時候,要設定4個。
code:
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * @Decription: 通過號碼某個部分數字的區分,輸出到不同的檔案 */ import java.util.HashMap; public class ProvincePartitioner extends Partitioner<FlowBean, Text> { //HashMap 集合 public static HashMap<String, Integer> provinceMap = new HashMap<String, Integer>(); static { provinceMap.put("3", 0); provinceMap.put("4", 1); provinceMap.put("5", 2); provinceMap.put("8", 3); } public int getPartition (FlowBean key, Text value,int numPartitions) throws IndexOutOfBoundsException { String st = value.toString().substring(1, 2); int num = provinceMap.get(st); return num; } }
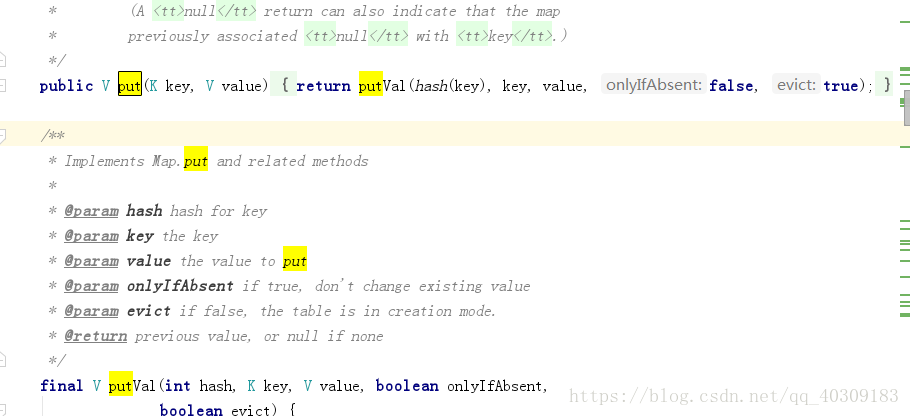
HashMap put方法
Partitoner原始碼