演算法導論 第十一章:散列表 筆記(直接定址表、散列表、通過連結法解決碰撞、雜湊函式、開放定址法、完全雜湊)
前面討論的各種資料結構中,記錄在各種結構中的相對位置是隨機的,和在記錄的關鍵字之間不存在有確定的關係,因此在查詢記錄是需要進行一系列和關鍵字的比較。而理想的情況是不希望進行任何的比較,一次存取便能得到所查記錄。那就必須在記錄的儲存位置和它的關鍵字之間建立一種確定的關係f,使每個關鍵字和結構中有一個唯一的儲存位置與之相對應。我們稱這個對應關係f為雜湊函式,而按這個思想建立的表為雜湊表。
在很多應用中,都要用到一種動態集合結構,它僅支援INSERT, SEARCH和DELETE字典操作。
實現字典的一種有效資料結構為散列表(hash table) 。在最壞情況下,在散列表中,查詢一個元素的時間與在連結串列中查詢一個元素的時間相同,在最壞情況下都是Θ(n)。但在實踐中,雜湊技術的效率是很高的。
直接定址表:
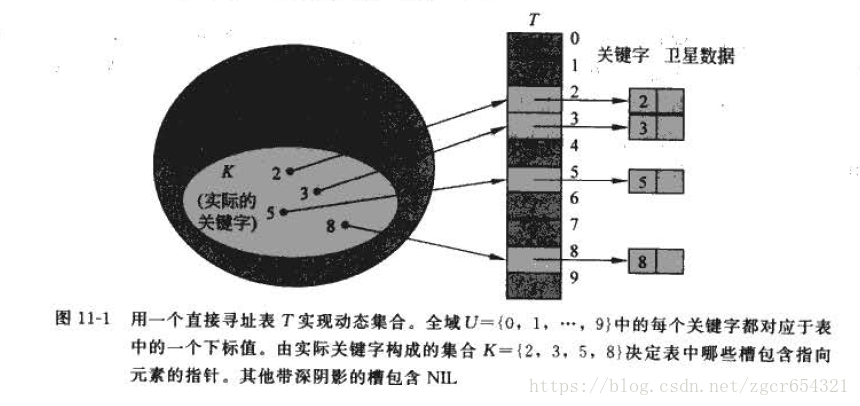
直接定址表就是陣列。當關鍵字的全域U比較小時,直接定址是一種簡單而有效的技術。如,如果全域為U={0,1,…,m-1}。則可以使用長度為m的陣列。
如:
散列表:
直接定址技術的缺點很明顯:如果全域U很大,則儲存大小為|U|的陣列是不切實際的,而且如果實際儲存的關鍵字集合K相對於全域U來說很小的時候,會造成巨大的浪費。此時採用散列表。
在直接定址方式下,具有關鍵字k 的元素被存放在槽k中。在雜湊方式下,該元素處於h(k)中,即利用雜湊函式h, 根據關鍵字k計算出槽的位置。函式h將關鍵字域U 對映到散列表T[0...m-1]的槽位上:
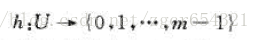
採用雜湊函式的目的就在於縮小需要處理的下標範圍,即我們要處理的值就從IUI降到m了,從而相應地降低了空間開銷。
如:
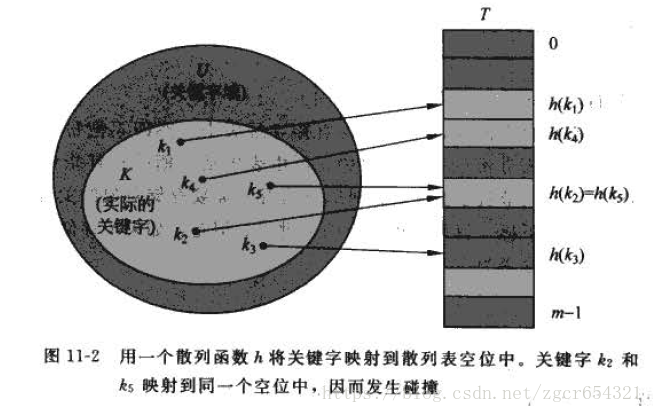
這裡會存在所謂“衝突”的問題:兩個關鍵字可能被對映到同一個槽位中。由於全域|U|>M,所以衝突是無法避免的,所以一方面需要精心設計雜湊函式來儘量減少衝突的次數,另一方面是需要解決衝突的方法。
通過連結法解決碰撞:
在連結法中,把雜湊到同一槽中的所有元素都放在一個連結串列中,如下圖所示。槽j中有一個指標, 它指向由所有雜湊到j的元素構成的連結串列的頭;如果不存在這樣的元素,則j中為NIL。
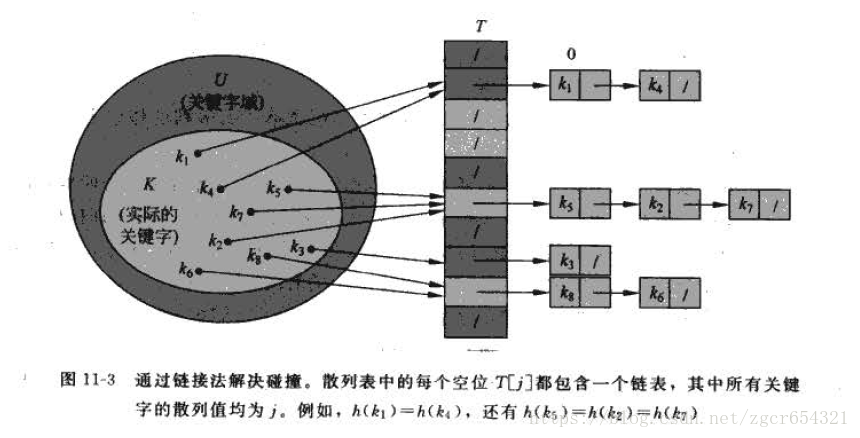
在採用連結法解決碰撞後,散列表T上的字典操作就很容易實現。
虛擬碼:
CHAINED-HASH-INSERT(T,x)
insert x at the head of list T[h(key[x])]
CHAINED-HASH-SEARCH(T,k)
search for an element with key k in list T[h(k)]
CHAINED-HASH-DELETE(T,x)
delete x from the list T[h(key[x])]插入操作的最壞情況執行時間為O(1) 。插入過程要快一些,因為假設要插入的元素x沒有出現在表中;如果需要,在插入前執行搜尋,可以檢查這個假設(付出額外代價) 。查詢操作的最壞情況執行時間與表的長度成正比。
對用連結法雜湊的分析:
給定一個具有m個槽位,儲存了n個元素的散列表T,定義T的裝載因子α為n/m,即,一個連結串列中的平均元素數目。α可能小於,等於,或大於1。
雜湊方法的平均效能依賴於所選取的雜湊函式h,將所有的關鍵字集合分佈到m個槽位上的均勻程度。假定對於任何一個給定的元素,等可能的雜湊到m個槽位中的任何一個,且與其他元素被雜湊到什麼位置上無關,稱這個假設為簡單均勻雜湊。
在簡單均勻雜湊的情況下,對於採用連結法的散列表,一次不成功查詢和一次成功查詢所需的平均時間都為Θ(1+α)。
因此,若散列表的槽位數正比於其中的元素個數,我們有n = O(m),於是,α = n/m = O(m)/m = O(1)。因此,查詢時間平均為常數。由於插入操作首先需要呼叫CHAINED-HASH-SEARCH確認元素x的關鍵值未曾出現在表中,然後用O(1)時間將x插入到連結串列T[h(key[x])]中,所以期望的時間是O(1)。相仿地,刪除操作對雙向拉鍊表平均情形時間也是O(1),所以所有的字典操作可以在O(1)的平均時間內得到支援。
雜湊函式:
一個好的雜湊函式應(近似的)滿足簡單均勻雜湊假設:每個關鍵字都等可能的被雜湊到m個槽位中的任何一個,並與其它關鍵字已雜湊到哪個槽位無關。遺憾的是一般無法檢查這一條件是否成立,因為很少能知道關鍵字的概率分佈,而且各個關鍵字可能不是完全獨立的。
如果知道關鍵字的概率分佈,比如關鍵字都是隨機的k,它們獨立均勻分佈在區間[0…1]中,那麼雜湊函式h(k) = km就能滿足簡單均勻雜湊的條件。
將關鍵字解釋為自然數:
多數雜湊函式都假定關鍵字域為自然數集N={0, 1, 2,··· } 。如果所給關鍵字不是自然數,則必須有一種方法來將它們解釋為自然數。例如, 一個字串關鍵字可以被解釋為按適當的基數記號表示的整數。
除法雜湊法:
h(k) = k mod m
其中m為散列表的槽位數,使用除數雜湊法的時候,對於m的選擇要慎重。比如m不應該是2的冪。否則如果m=2的p次方,則h(k)就是k的p個最低位數字(二進位制)。除非已經知道關鍵字的最低p位數的排列是等可能的,否則在設計雜湊函式時,應該考慮關鍵字的所有位。
一個不太接近2的整數冪的素數是m個一個比較好的選擇。
乘法雜湊法:
h(k) = m(kA mod 1),其中"kA mod 1" 即kA的小數部分。
乘法方法的一個優點是對m的選擇沒有什麼特別的要求, 一般選擇它為2的某個冪次(m =2的p次方, p為某個整數),最佳的選擇為A。

直接定址法:
h(k) = k或 h(k) = ak + b
其中a和b為常數。實際中能使用這種雜湊函式的情況很少。
數字分析法:
假設關鍵字是以r為基的數(比如以10為基的十進位制數),並且雜湊表中可能出現的關鍵字都是事先知道的,則可取關鍵字的若干位組成雜湊地址。
全域雜湊法:
全域雜湊的基本思想是在執行開始時,就從一族仔細設計的函式中、隨機地選擇一個作為雜湊函式。就像在快速排序中一樣,隨機化保證了沒有哪一種輸人會始終導致最壞情況性態。同時,隨機化使得即使是對同一個輸入,演算法在每一次執行時的性態也都不一樣。這樣就可以確保對於任何輸人,演算法都具有較好的平均情況性態。

開放定址法:
在開放定址法(open addressing) 中,所有的元素都存放在散列表裡。即每個表項或包含動態集合的一個元素,或包含NIL。當查詢一個元素時,要檢查所有的表項,直到找到所需的元素,或者最終發現該元素不在表中。
在開放定址法中,散列表有可能會被填滿,因而裝載因子α <= 1。
在開放定址法中,字典操作需要找到一個”槽序列”,比如要插入元素,需要按照某個槽序列探查散列表,直到找到一個空槽。探查的序列不一定是0,1…m-1。而是要依賴於待插入的關鍵字。對於每一個關鍵字k,探查序列為:h(k,i) (0 <= i <= m-1)。
虛擬碼:
HASH_INSERT(T, k)
i= 0
repeat j = h(k, i)
if T[j] == NIL
then T[j]= k
return j
else i=i+1
until i==m
error "hash table overflow"
HASH_SERACH(T,k)
i = 0
repeat j = h(k, i)
if T[j] == k
then return j
i = i+1
until T[j] == NIL or i ==m
return NIL查詢關鍵字k的演算法的探查序列與將k插入時的插入演算法是一樣的。當在查詢過程中碰到一個空槽時,查詢演算法就(非成功地)停止,因為如果k確實在表中的話,也應該在該處,而不是探查序列的稍後位置上(之所以這樣說,是因為我們假定了關鍵字不會被刪除)。過程HASH-SEARCH的輸入為一個散列表T和一個關鍵字k,如果槽j中包含關鍵字k則返回j;如果k不在表T中,則返回NIL 。
刪除操作執行起來比較困難,當我們從槽i中刪除關鍵字時,不能簡單地讓T[i]=NIL,因為這樣會破壞查詢的過程。假設關鍵字k在i之後插入到散列表中,如果T[i]被設為NIL,那麼查詢過程就再也找不到k了。解決這個問題的方法是引入一個新的狀態DELETED,而不是NIL,這樣在插入過程中,一旦發現DELETED的槽,便可以在該槽中放置資料,而查詢過程不需要任何改動。但如此一來,查詢時間就不再依賴於裝載因子了,所以在必須刪除關鍵字的應用中,往往採用連結法來解決碰撞。
均勻雜湊:
假設每個關鍵字的探查序列等可能的為(0,1,……m-1)的m!種排列中的任何一種。真正的均勻雜湊難以實現,有三種技術常用來計算開放定址法中的探查序列:線性探查,二次探查,雙重探查。這些技術均不滿足均勻雜湊的假設。
線性探查:
h(k,i) = (h’(k) + i) mod m i = 0,1,…,m-1
給定一個關鍵字k,首先探查槽位h’(k),然後是h’(k) + 1,以此類推,直到最後的h’(k)-1。線上性探查中,初始探查位置決定了整個序列,所以有m種不同的探查序列。
線性探查有個缺點,就是一次群集。當表中i,i+1,i+2位置上都已經填滿時,下一個雜湊地址為i,i+1,i+2,i+3的關鍵字記錄都將競爭i+3的位置。隨著連續被佔用的槽位不斷增加,平均查詢時間也不斷增加。
二次探查:
h(k,i) = (h'(k) + c1i +c2i^2) mod m i = 0,1,…,m-1
後續的探查位置要在此基礎上加上一個偏移量,該偏移量以二次的方式依賴於探查號i。這種探查的效果要比線性探查好。但是,如果兩個關鍵字的初始探查位置相同,那它們的探查序列也是相同的,這一性質會導致二次群集。類似於線性探查,二次探查也僅有m個不同的探查序列。
雙重雜湊:
h(k,i) = (h1(k) +i*h2(k)) mod m i = 0,1,…,m-1
其中h1和h2為輔助雜湊函式。初始探查位置為T(h1(k) ] , 後續的探查位置在此基礎上加上偏移量h2(k)模m 。
雙重雜湊是開放定址法中的最好方法之一,不像線性和二次探查,雙重探查的的探查序列以兩種不同的方式依賴於關鍵字k。
為能查詢整個散列表,值h2(k)要與表的大小m互質。確保這個條件成立的一種方法是取m為2的幕,並設計一個總產生奇數的h2。另一種方法是取m為質數,並設計一個總是產生較m小的正整數的h2。
如:
我們可以取m為質數,並取h1(k) = k mod m, h2(k) = 1 + (k mod m'),其中m' 略小於m( 如m-1) 。比如,如果k=123456 ,m=701, m'=700,則有h1(k)=80,h2(k) = 257, 可知第一個探查位置為80, 然後檢查每第257個槽(模m), 直到找到該關鍵字,或查過了所有的槽。
給定一個裝載因子為a=n/m< l 的開放定址散列表,在一次不成功的查詢中,期望的探查數至多為1/ (1 一a) 。假設雜湊是一致的。
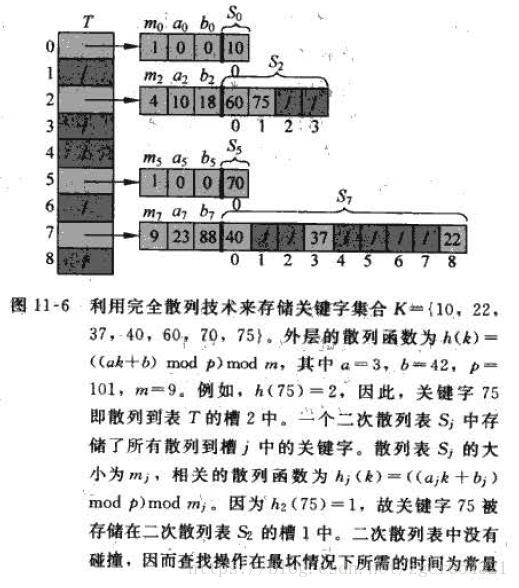
完全雜湊:
完全雜湊將關鍵字通過一級雜湊函式h1和二級雜湊函式h2後對映到二級雜湊中,其中,關鍵字個數等於桶數(n=m),二級雜湊的大小N(T[i])為關鍵字個數的平方,用以保證完全O(n)的儲存空間,以及O(1)的訪問效率。但實際上,不可能真正地完全實現無衝突。
如: