
python實現人臉檢測及識別(2)---- 利用keras庫訓練人臉識別模型
前面已經採集好資料集boss資料夾存放需要識別的物件照片,other存放其他人的訓練集照片,現在,我們終於可以嘗試訓練我們自己的卷積神經網路模型了。CNN擅長影象處理,keras庫的tensorflow版亦支援此種網路模型,萬事俱備,就放開手做吧。前面說過,我們需要通過大量的訓練資料訓練我們的模型,因此首先要做的就是把訓練資料準備好,並將其輸入給CNN。前面我們已經準備好了2000張臉部影象,但沒有進行標註,並且還需要將資料載入到記憶體,以方便輸入給CNN。因此,第一步工作就是載入並標註資料到記憶體。
首先我們建立一個空白的python檔案,檔名為:boss_input.py,程式碼如下:

1 # -*- coding: utf-8 -*- 2 3 import os 4 import sys 5 import numpy as np 6 import cv2 7 8 IMAGE_SIZE = 64 9 10 #按照指定影象大小調整尺寸 11 def resize_image(image, height = IMAGE_SIZE, width = IMAGE_SIZE): 12 top, bottom, left, right = (0, 0, 0, 0) 13 14 #獲取影象尺寸 15 h, w, _ = image.shape16 17 #對於長寬不相等的圖片,找到最長的一邊 18 longest_edge = max(h, w) 19 20 #計算短邊需要增加多上畫素寬度使其與長邊等長 21 if h < longest_edge: 22 dh = longest_edge - h 23 top = dh // 2 24 bottom = dh - top 25 elif w < longest_edge: 26 dw = longest_edge - w 27 left = dw // 2 28right = dw - left 29 else: 30 pass 31 32 #RGB顏色 33 BLACK = [0, 0, 0] 34 35 #給影象增加邊界,是圖片長、寬等長,cv2.BORDER_CONSTANT指定邊界顏色由value指定 36 constant = cv2.copyMakeBorder(image, top , bottom, left, right, cv2.BORDER_CONSTANT, value = BLACK) 37 38 #調整影象大小並返回 39 return cv2.resize(constant, (height, width)) 40 41 #讀取訓練資料 42 images = [] 43 labels = [] 44 def read_path(path_name): 45 for dir_item in os.listdir(path_name): 46 #從初始路徑開始疊加,合併成可識別的操作路徑 47 full_path = os.path.abspath(os.path.join(path_name, dir_item)) 48 49 if os.path.isdir(full_path): #如果是資料夾,繼續遞迴呼叫 50 read_path(full_path) 51 else: #檔案 52 if dir_item.endswith('.jpg'): 53 image = cv2.imread(full_path) 54 image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE) 55 56 #放開這個程式碼,可以看到resize_image()函式的實際呼叫效果 57 #cv2.imwrite('1.jpg', image) 58 59 images.append(image) 60 labels.append(path_name) 61 62 return images,labels 63 64 65 #從指定路徑讀取訓練資料 66 def load_dataset(path_name): 67 images,labels = read_path(path_name) 68 69 #將輸入的所有圖片轉成四維陣列,尺寸為(圖片數量*IMAGE_SIZE*IMAGE_SIZE*3) 70 #我和閨女兩個人共1200張圖片,IMAGE_SIZE為64,故對我來說尺寸為1200 * 64 * 64 * 3 71 #圖片為64 * 64畫素,一個畫素3個顏色值(RGB) 72 images = np.array(images) 73 print(images.shape) 74 75 #標註資料,'me'資料夾下都是我的臉部影象,全部指定為0,另外一個資料夾下是閨女的,全部指定為1 76 labels = np.array([0 if label.endswith('me') else 1 for label in labels]) 77 78 return images, labels 79 80 if __name__ == '__main__': 81 if len(sys.argv) != 2: 82 print("Usage:%s path_name\r\n" % (sys.argv[0])) 83 else: 84 images, labels = load_dataset('./data') 85
上面給出的程式碼主函式就是load_dataset(),它將圖片資料進行標註並以多維陣列的形式載入到記憶體中。我實際用於訓練的臉部資料共1200張,我去掉了一些模糊的或者表情基本一致的頭像,留下了清晰、臉部表情有些區別的,我和其他人各留了600張,所以訓練資料變成了1200。上述程式碼註釋很清楚,不多講,唯一一個理解起來稍微有點難度的就是resize_image()函式。這個函式其實就做了一件事情,判斷圖片是不是四邊等長,也就是圖片是不是正方形。如果不是,則短的那兩邊增加兩條黑色的邊框,使影象變成正方形,這樣再呼叫cv2.resize()函式就可以實現等比例縮放了。因為我們指定縮放的比例就是64 x 64,只有縮放之前影象為正方形才能確保影象不失真。resize_image()函式的執行結果如下所示:

上圖為200 x 300的圖片,寬度小於高度,因此,需要增加寬度,正常應該是兩邊各增加寬50畫素的黑邊:

如我們所願,成了一個300 x 300的正方形圖片,這時我們再縮放到64 x 64就可以了:

上圖就是我們將要輸入到CNN中的圖片,之所以縮放到這麼小,主要是為了減少計算量及記憶體佔用,提升訓練速度。執行程式之前,請把圖片組織一下,結構參見下圖:
boss_input.py所在資料夾下建立一個data資料夾,在data下再建立boss和other兩個資料夾,boss放本人的影象,other放其他人的,我各放了600張圖片。
這些工作做完之後,我們就可以開始構建訓練程式碼了。
同樣,在boss_input.py所在資料夾下新建一個python空白檔案boss_train.py,然後我們先把需要的庫檔案新增到程式碼中:
#-*- coding: utf-8 -*- import random import numpy as np from sklearn.model_selection import train_test_split from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Convolution2D, MaxPooling2D from keras.optimizers import SGD from keras.utils import np_utils from keras.models import load_model from keras import backend as K from load_face_dataset import load_dataset, resize_image, IMAGE_SIZE
我們先不管匯入的這些庫是幹啥的,你只要知道接下來的程式碼要用到這些庫就夠了,用到了我們再講。到目前為止,資料載入的工作已經完成,我們只需呼叫這個介面即可。關於訓練集的使用,我們需要拿出一部分用於訓練網路,建立識別模型;另一部分用於驗證模型。同時我們還有一些其它的比如資料歸一化等預處理的工作要做,因此,我們把這些工作封裝成一個dataset類來完成:
1 class Dataset: 2 def __init__(self, path_name): 3 #訓練集 4 self.train_images = None 5 self.train_labels = None 6 7 #驗證集 8 self.valid_images = None 9 self.valid_labels = None 10 11 #測試集 12 self.test_images = None 13 self.test_labels = None 14 15 #資料集載入路徑 16 self.path_name = path_name 17 18 #當前庫採用的維度順序 19 self.input_shape = None 20 21 #載入資料集並按照交叉驗證的原則劃分資料集並進行相關預處理工作 22 def load(self, img_rows = IMAGE_SIZE, img_cols = IMAGE_SIZE, 23 img_channels = 3, nb_classes = 2): 24 #載入資料集到記憶體 25 images, labels = load_dataset(self.path_name) 26 27 train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size = 0.3, random_state = random.randint(0, 100)) 28 _, test_images, _, test_labels = train_test_split(images, labels, test_size = 0.5, random_state = random.randint(0, 100)) 29 30 #當前的維度順序如果為'th',則輸入圖片資料時的順序為:channels,rows,cols,否則:rows,cols,channels 31 #這部分程式碼就是根據keras庫要求的維度順序重組訓練資料集 32 if K.image_dim_ordering() == 'th': 33 train_images = train_images.reshape(train_images.shape[0], img_channels, img_rows, img_cols) 34 valid_images = valid_images.reshape(valid_images.shape[0], img_channels, img_rows, img_cols) 35 test_images = test_images.reshape(test_images.shape[0], img_channels, img_rows, img_cols) 36 self.input_shape = (img_channels, img_rows, img_cols) 37 else: 38 train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels) 39 valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels) 40 test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels) 41 self.input_shape = (img_rows, img_cols, img_channels) 42 43 #輸出訓練集、驗證集、測試集的數量 44 print(train_images.shape[0], 'train samples') 45 print(valid_images.shape[0], 'valid samples') 46 print(test_images.shape[0], 'test samples') 47 48 #我們的模型使用categorical_crossentropy作為損失函式,因此需要根據類別數量nb_classes將 49 #類別標籤進行one-hot編碼使其向量化,在這裡我們的類別只有兩種,經過轉化後標籤資料變為二維 50 train_labels = np_utils.to_categorical(train_labels, nb_classes) 51 valid_labels = np_utils.to_categorical(valid_labels, nb_classes) 52 test_labels = np_utils.to_categorical(test_labels, nb_classes) 53 54 #畫素資料浮點化以便歸一化 55 train_images = train_images.astype('float32') 56 valid_images = valid_images.astype('float32') 57 test_images = test_images.astype('float32') 58 59 #將其歸一化,影象的各畫素值歸一化到0~1區間 60 train_images /= 255 61 valid_images /= 255 62 test_images /= 255 63 64 self.train_images = train_images 65 self.valid_images = valid_images 66 self.test_images = test_images 67 self.train_labels = train_labels 68 self.valid_labels = valid_labels 69 self.test_labels = test_labels
我們構建了一個Dataset類,用於資料載入及預處理。其中,__init__()為類的初始化函式,load()則完成實際的資料載入及預處理工作。載入前面已經說過很多了,就不多說了。關於預處理,我們做了幾項工作:
1)按照交叉驗證的原則將資料集劃分成三部分:訓練集、驗證集、測試集;
2)按照keras庫執行的後端系統要求改變影象資料的維度順序;
3)將資料標籤進行one-hot編碼,使其向量化
4)歸一化影象資料
關於第一項工作,先簡單說說什麼是交叉驗證?交叉驗證屬於機器學習中常用的精度測試方法,它的目的是提升模型的可靠和穩定性。我們會拿出大部分資料用於模型訓練,小部分資料用於對訓練後的模型驗證,驗證結果會與驗證集真實值(即標籤值)比較並計算出差平方和,此項工作重複進行,直至所有驗證結果與真實值相同,交叉驗證結束,模型交付使用。在這裡我們匯入了sklearn庫的交叉驗證模組,利用函式train_test_split()來劃分訓練集和驗證集,具體語句如下:
train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size = 0.2,
random_state = random.randint(0, 100))
train_test_split()會根據test_size引數按比例劃分資料集(不要被test_size的外表所迷惑,它只是用來指定資料集劃分比例的,本質上與測試無關,劃分完了你愛咋用就咋用),在這裡我們劃分出了30%的資料用於驗證,70%用於訓練模型。引數random_state用於指定一個隨機數種子,從全部資料中隨機選取資料建立訓練集和驗證集,所以你將會看到每次訓練的結果都會稍有不同。當然,為了省事,測試集我也呼叫了這個函式:
_, test_images, _, test_labels = train_test_split(images, labels, test_size = 0.5,
random_state = random.randint(0, 100))
在這裡,測試集我選擇的比例為0.5,所以前面的“_, test_images, _, test_labels”語句你調個順序也成,即“test_images, _, test_labels, _”,但是如果你改成其它數值,就必須嚴格按照程式碼給出的順序才能得到你想要的結果。train_test_split()函式會按照訓練集特徵資料(這裡就是影象資料)、測試集特徵資料、訓練集標籤、測試集標籤的順序返回各資料集。所以,看你的選擇了。
關於第二項工作,我們前面不止一次說過keras建立在tensorflow或theano基礎上,換句話說,keras的後端系統可以是tensorflow也可以是theano。後端系統決定了影象資料輸入CNN網路時的維度順序,tensorflow的維度順序為行數(rows)、列數(cols)、通道數(顏色通道,channels);theano則是通道數、行數、列數。所以,我們通過呼叫image_dim_ordering()函式來確定後端系統的型別(‘th’代表theano,'tf'代表tensorflow),然後我們再通過numpy提供的reshape()函式重新調整陣列維度。
關於第三項工作,對標籤集進行one-hot編碼的原因是我們的訓練模型採用categorical_crossentropy作為損失函式(多分類問題的常用函式,後面會詳解),這個函式要求標籤集必須採用one-hot編碼形式。所以,我們對訓練集、驗證集和測試集標籤均做了編碼轉換。那麼什麼是one-hot編碼呢?one-hot有的翻譯成獨熱,有的翻譯成一位有效,個人感覺一位有效更直白一些。因為one-hot編碼採用狀態暫存器的組織方式對狀態進行編碼,每個狀態值對應一個暫存器位,且任意時刻,只有一位有效。對於我們的程式來說,我們類別狀態只有兩種(nb_classes = 2):0和1,0代表我,1代表閨女。one-hot編碼會提供兩個暫存器位儲存這兩個狀態,如果標籤值為0,則編碼後值為[1 0],代表第一位有效;如果為1,則編碼後值為[0 1],代表第2為有效。換句話說,one-hot編碼將數值變成了位置資訊,使其向量化,這樣更方便CNN操作。
關於第四項工作,資料集先浮點後歸一化的目的是提升網路收斂速度,減少訓練時間,同時適應值域在(0,1)之間的啟用函式,增大區分度。其實歸一化有一個特別重要的原因是確保特徵值權重一致。舉個例子,我們使用mse這樣的均方誤差函式時,大的特徵數值比如(5000-1000)2與小的特徵值(3-1)2相加再求平均得到的誤差值,顯然大值對誤差值的影響最大,但大部分情況下,特徵值的權重應該是一樣的,只是因為單位不同才導致數值相差甚大。因此,我們提前對特徵資料做歸一化處理,以解決此類問題。關於歸一化的詳細介紹有興趣的請參考如下連結:
資料準備工作到此完成,接下來就要進入整個系列最關鍵的一個節點——建立我們自己的卷積神經網路模型,激動吧;)?與資料集載入及預處理模組一樣,我們依然將模型構建成一個類來使用,新建的這個模型類新增在Dataset類的下面:
1 #CNN網路模型類 2 class Model: 3 def __init__(self): 4 self.model = None 5 6 #建立模型 7 def build_model(self, dataset, nb_classes = 2): 8 #構建一個空的網路模型,它是一個線性堆疊模型,各神經網路層會被順序新增,專業名稱為序貫模型或線性堆疊模型 9 self.model = Sequential() 10 11 #以下程式碼將順序新增CNN網路需要的各層,一個add就是一個網路層 12 self.model.add(Convolution2D(32, 3, 3, border_mode='same', 13 input_shape = dataset.input_shape)) #1 2維卷積層 14 self.model.add(Activation('relu')) #2 啟用函式層 15 16 self.model.add(Convolution2D(32, 3, 3)) #3 2維卷積層 17 self.model.add(Activation('relu')) #4 啟用函式層 18 19 self.model.add(MaxPooling2D(pool_size=(2, 2))) #5 池化層 20 self.model.add(Dropout(0.25)) #6 Dropout層 21 22 self.model.add(Convolution2D(64, 3, 3, border_mode='same')) #7 2維卷積層 23 self.model.add(Activation('relu')) #8 啟用函式層 24 25 self.model.add(Convolution2D(64, 3, 3)) #9 2維卷積層 26 self.model.add(Activation('relu')) #10 啟用函式層 27 28 self.model.add(MaxPooling2D(pool_size=(2, 2))) #11 池化層 29 self.model.add(Dropout(0.25)) #12 Dropout層 30 31 self.model.add(Flatten()) #13 Flatten層 32 self.model.add(Dense(512)) #14 Dense層,又被稱作全連線層 33 self.model.add(Activation('relu')) #15 啟用函式層 34 self.model.add(Dropout(0.5)) #16 Dropout層 35 self.model.add(Dense(nb_classes)) #17 Dense層 36 self.model.add(Activation('softmax')) #18 分類層,輸出最終結果 37 38 #輸出模型概況 39 self.model.summary()
先不解釋程式碼,咱先看看上述程式碼的執行情況,接著再新增幾行測試程式碼:
if __name__ == '__main__': dataset = Dataset('./data/') dataset.load() model = Model() model.build_model(dataset)
然後在控制檯輸入:
python3 boss_train.py
如果你沒敲錯程式碼,一切順利的話,你應該看到類似下面這樣的輸出內容:
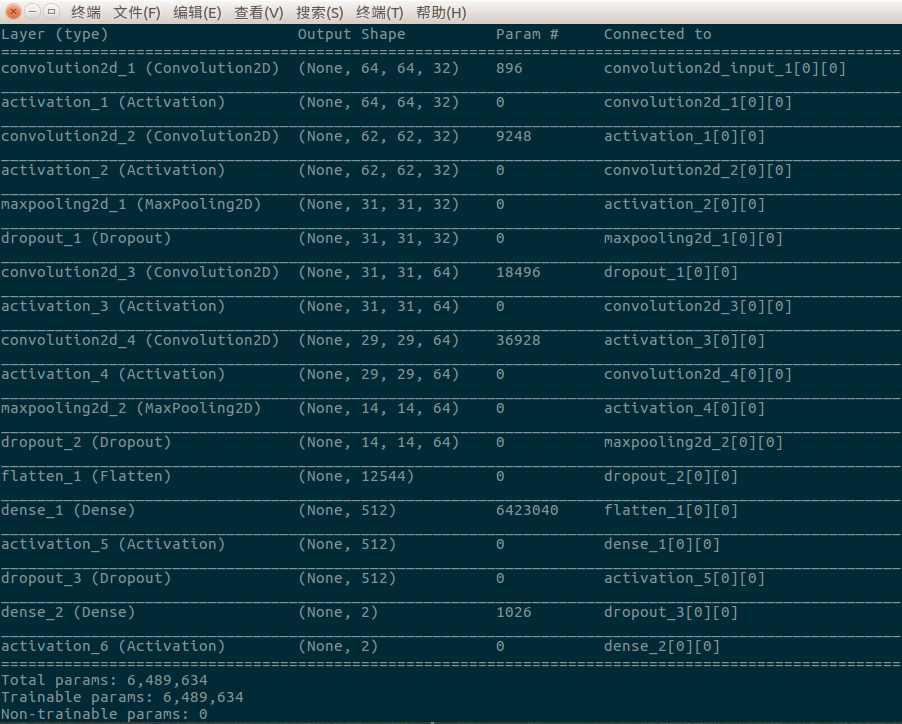
我們通過呼叫self.model.summary()函式將網路模型基本結構資訊展示在我們面前,包括層型別、維度、引數個數、層連線等資訊,一目瞭然,簡潔、清晰。通過上圖我們可以看出,這個網路模型共18層,包括4個卷積層、5個啟用函式層、2個池化層(pooling layer)、3個Dropout層、2個全連線層、1個Flatten層、1個分類層,訓練引數為6,489,634個,還是很可觀的。
你看,這個實際運作的網路比我們上次給出的那個3層卷積的網路複雜多了,多了池化、Dropout、Dense、Flatten以及最終的分類層,這些都是些什麼鬼東西,需要我們逐個理一理:
卷積層(convolution layer):這一層前面講了太多,這裡重點講講Convolution2D()函式。根據keras官方文件描述,2D代表這是一個2維卷積,其功能為對2維輸入進行滑窗卷積計算。我們的臉部影象尺寸為64*64,擁有長、寬兩維,所以在這裡我們使用2維卷積函式計算卷積。所謂的滑窗計算,其實就是利用卷積核逐個畫素、順序進行計算,如下圖:

上圖選擇了最簡單的均值卷積核,3x3大小,我們用這個卷積核作為掩模對前面4x4大小的影象逐個畫素作卷積運算。首先我們將卷積核中心對準影象第一個畫素,在這裡就是畫素值為237的那個畫素。卷積核覆蓋的區域(掩模之稱即由此來),其下所有畫素取均值然後相加:
C(1) = 0 * 0.5 + 0 * 0.5 + 0 * 0.5 + 0 * 0.5 + 237 * 0.5 + 203 * 0.5 + 0 * 0.5 + 123 * 0.5 + 112 * 0.5
結果直接替換卷積核中心覆蓋的畫素值,接著是第二個畫素、然後第三個,從左至右,由上到下……以此類推,卷積核逐個覆蓋所有畫素。整個操作過程就像一個滑動的視窗逐個滑過所有畫素,最終生成一副尺寸相同但已經過卷積處理的影象。上圖我們採用的是均值卷積核,實際效果就是將影象變模糊了。顯然,卷積核覆蓋影象邊界畫素時,會有部分割槽域越界,越界的部分我們以0填充,如上圖。對於此種情況,還有一種處理方法,就是丟掉邊界畫素,從覆蓋區域不越界的畫素開始計算。像上圖,如果採用丟掉邊界畫素的方法,3x3的卷積核就應該從第2行第2列的畫素(值為112)開始,到第3行第3列結束,最終我們會得到一個2x2的影象。這種處理方式會丟掉影象的邊界特徵;而第一種方式則保留了影象的邊界特徵。在我們建立的模型中,卷積層採用哪種方式處理影象邊界,卷積核尺寸有多大等引數都可以通過Convolution2D()函式來指定:
self.model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape = dataset.input_shape))
第一個卷積層包含32個卷積核,每個卷積核大小為3x3,border_mode值為“same”意味著我們採用保留邊界特徵的方式滑窗,而值“valid”則指定丟掉邊界畫素。根據keras開發文件的說明,當我們將卷積層作為網路的第一層時,我們還應指定input_shape引數,顯式地告知輸入資料的形狀,對我們的程式來說,input_shape的值為(64,64,3),來自Dataset類,代表64x64的彩色RGB影象。
啟用函式層:它的作用前面已經說了,這裡講一下程式碼中採用的relu(Rectified Linear Units,修正線性單元)函式,它的數學形式如下:
ƒ(x) = max(0, x)
這個函式非常簡單,其輸出一目瞭然,小於0的輸入,輸出全部為0,大於0的則輸入與輸出相等。該函式的優點是收斂速度快,除了它,keras庫還支援其它幾種啟用函式,如下:
- softplus
- softsign
- tanh
- sigmoid
- hard_sigmoid
- linear
它們的函式式、優缺點度娘會告訴你,不多說。對於不同的需求,我們可以選擇不同的啟用函式,這也是模型訓練可調整的一部分,運用之妙,存乎一心,請自忖之。另外再交代一句,其實啟用函式層按照我們前文所講,其屬於人工神經元的一部分,所以我們亦可以在構造層物件時通過傳遞activation引數設定,如下:
self.model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape = dataset.input_shape)) self.model.add(Activation('relu')) #設定為單獨的啟用層 #通過傳遞activation引數設定,與上兩行程式碼的作用相同 self.model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape = dataset.input_shape, activation='relu'))
池化層(pooling layer):池化層存在的目的是縮小輸入的特徵圖,簡化網路計算複雜度;同時進行特徵壓縮,突出主要特徵。我們通過呼叫MaxPooling2D()函式建立了池化層,這個函式採用了最大值池化法,這個方法選取覆蓋區域的最大值作為區域主要特徵組成新的縮小後的特徵圖:
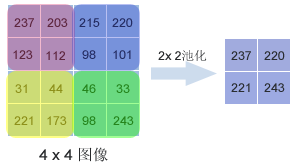
顯然,池化層與卷積層覆蓋區域的方法不同,前者按照池化尺寸逐塊覆蓋特徵圖,卷積層則是逐個畫素滑動覆蓋。對於我們輸入的64x64的臉部特徵圖來說,經過2x2池化後,影象變為32x32大小。
Dropout層:隨機斷開一定百分比的輸入神經元連結,以防止過擬合。那麼什麼是過擬合呢?一句話解釋就是訓練資料預測準確率很高,測試資料預測準確率很低,用圖形表示就是擬合曲線較尖,不平滑。導致這種現象的原因是模型的引數很多,但訓練樣本太少,導致模型擬合過度。為了解決這個問題,Dropout層將有意識的隨機減少模型引數,讓模型變得簡單,而越簡單的模型越不容易產生過擬合。程式碼中Dropout()函式只有一個輸入引數——指定拋棄比率,範圍為0~1之間的浮點數,其實就是百分比。這個引數亦是一個可調引數,我們可以根據訓練結果調整它以達到更好的模型成熟度。
Flatten層:截止到Flatten層之前,在網路中流動的資料還是多維的(對於我們的程式就是2維的),經過多次的卷積、池化、Dropout之後,到了這裡就可以進入全連線層做最後的處理了。全連線層要求輸入的資料必須是一維的,因此,我們必須把輸入資料“壓扁”成一維後才能進入全連線層,Flatten層的作用即在於此。該層的作用如此純粹,因此反映到程式碼上我們看到它不需要任何輸入引數。
全連線層(dense layer):全連線層的作用就是用於分類或迴歸,對於我們來說就是分類。keras將全連線層定義為Dense層,其含義就是這裡的神經元連線非常“稠密”。我們通過Dense()函式定義全連線層。這個函式的一個必填引數就是神經元個數,其實就是指定該層有多少個輸出。在我們的程式碼中,第一個全連線層(#14 Dense層)指定了512個神經元,也就是保留了512個特徵輸出到下一層。這個引數可以根據實際訓練情況進行調整,依然是沒有可參考的調整標準,自調之。
分類層:全連線層最終的目的就是完成我們的分類要求:0或者1,模型構建程式碼的最後兩行完成此項工作:
self.model.add(Dense(nb_classes)) #17 Dense層 self.model.add(Activation('softmax')) #18 分類層,輸出最終結果
第17層我們按照實際的分類要求指定神經元個數,對我們來說就是2,18層我們通過softmax函式完成最終分類。關於softmax函式,其函式式如下:
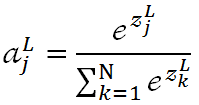
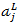 代表第L層第j個神經元的輸出,
代表第L層第j個神經元的輸出,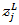 代表第L層第j個神經元的輸入,我們用單個神經元的輸入結合自然常數e做指數運算,運算結果除以所有L層神經元輸入的指數運算之和,就得到了一個介於0~1之間的浮點值。顯然,從上述公式很容易看出,所有神經元輸出之和肯定為1:
代表第L層第j個神經元的輸入,我們用單個神經元的輸入結合自然常數e做指數運算,運算結果除以所有L層神經元輸入的指數運算之和,就得到了一個介於0~1之間的浮點值。顯然,從上述公式很容易看出,所有神經元輸出之和肯定為1:
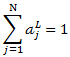
這個值其實就是第j個神經元在所有神經元輸出中所佔的百分比。從分類的角度來說,該神經元的輸出值越大,其對應的類別為真實類別的可能性就越大。因此,經過softmax函式,上層的N個輸入被對映成N個概率分佈,概率之和為1,概率值最大者即為模型預測的類別。
好了,模型構建完畢,接下來構建訓練程式碼,在build_model()函式下面繼續新增如下程式碼:
1 #訓練模型 2 def train(self, dataset, batch_size = 20, nb_epoch = 10, data_augmentation = True): 3 sgd = SGD(lr = 0.01, decay = 1e-6, 4 momentum = 0.9, nesterov = True) #採用SGD+momentum的優化器進行訓練,首先生成一個優化器物件 5 self.model.compile(loss='categorical_crossentropy', 6 optimizer=sgd, 7 metrics=['accuracy']) #完成實際的模型配置工作 8 9 #不使用資料提升,所謂的提升就是從我們提供的訓練資料中利用旋轉、翻轉、加噪聲等方法創造新的 10 #訓練資料,有意識的提升訓練資料規模,增加模型訓練量 11 if not data_augmentation: 12 self.model.fit(dataset.train_images, 13 dataset.train_labels, 14 batch_size = batch_size, 15 nb_epoch = nb_epoch, 16 validation_data = (dataset.valid_images, dataset.valid_labels), 17 shuffle = True) 18 #使用實時資料提升 19 else: 20 #定義資料生成器用於資料提升,其返回一個生成器物件datagen,datagen每被呼叫一 21 #次其生成一組資料(順序生成),節省記憶體,其實就是python的資料生成器 22 datagen = ImageDataGenerator( 23 featurewise_center = False, #是否使輸入資料去中心化(均值為0), 24 samplewise_center = False, #是否使輸入資料的每個樣本均值為0 25 featurewise_std_normalization = False, #是否資料標準化(輸入資料除以資料集的標準差) 26 samplewise_std_normalization = False, #是否將每個樣本資料除以自身的標準差 27 zca_whitening = False, #是否對輸入資料施以ZCA白化 28 rotation_range = 20, #資料提升時圖片隨機轉動的角度(範圍為0~180) 29 width_shift_range = 0.2, #資料提升時圖片水平偏移的幅度(單位為圖片寬度的佔比,0~1之間的浮點數) 30 height_shift_range = 0.2, #同上,只不過這裡是垂直 31 horizontal_flip = True, #是否進行隨機水平翻轉 32 vertical_flip = False) #是否進行隨機垂直翻轉 33 34 #計算整個訓練樣本集的數量以用於特徵值歸一化、ZCA白化等處理 35 datagen.fit(dataset.train_images) 36 37 #利用生成器開始訓練模型 38 self.model.fit_generator(datagen.flow(dataset.train_images, dataset.train_labels, 39 batch_size = batch_size), 40 samples_per_epoch = dataset.train_images.shape[0], 41 nb_epoch = nb_epoch, 42 validation_data = (dataset.valid_images, dataset.valid_labels))
按照我們的習慣,依然先不解釋程式碼,先看執行結果,程式執行前新增如下一行程式碼:
#先前新增的測試build_model()函式的程式碼 model.build_model(dataset) #測試訓練函式的程式碼 model.train(dataset)
儲存,控制檯輸入:
python3 boss_train.py
訓練結果如下:
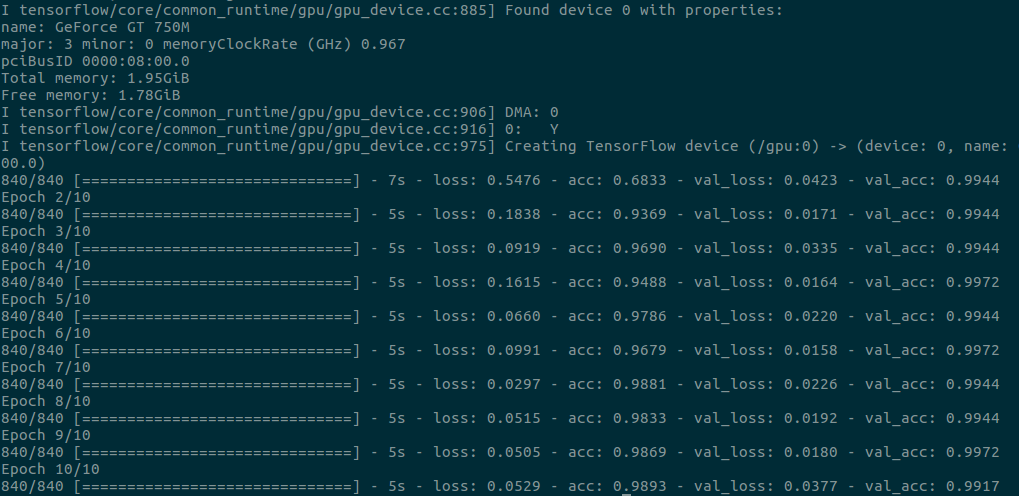
我們共進行了10輪次訓練(nb_epoch = 10),每輪42次迭代(840 / 20,訓練集1200 x (1-0.3) = 840),每次迭代訓練使用20個樣本(batch_size = 20),得到的訓練結果還不錯(以第10輪次訓練結果為例):
訓練誤差(loss):0.0529
訓練準確率(acc):0.9893
驗證誤差(val_loass):0.0377
驗證準確率(val_acc):0.9917
驗證集準確率高達99%,至少從驗證結果上看模型已達實用化要求,下一步可以用測試資料集對其進行測試了。新增測試程式碼之前,我們需要對訓練程式碼中幾個關鍵函式交代一下。首先是優化器函式,優化器用於訓練模型,它的作用就是調整訓練引數(權重和偏置值)使其最優,確保e值最小(參見系列4——CNN入門)。keras提供了很多優化器,我們在這裡採用的SGD就是其中一種,它就是機器學習領域最著名的隨機梯度下降法。函式第一個引數lr用於指定學習效率(lr,Learning Rate,參見系列4),其值為大於0的浮點數。decay指定每次更新後學習效率的衰減值,這個值一定很小(1e-6,0.000 001),否則速率會衰減很快。momentum指定動量值。SGD方法有一個明顯的缺點就是,它的下降方向完全依賴當前的訓練樣本(batch),因此其優化十分不穩定。為了解決這個問題,大牛們引進了動量(momentum),用它來模擬物體運動時的慣性,讓優化器在一定程度上保留之前的優化方向,同時利用當前樣本微調最終的優化方向,這樣即能增加穩定性,提高學習速度,又在一定程度上避免了陷入區域性最優陷阱。引數momentum即用於指定在多大程度上保留原有方向,其值為0~1之間的浮點數。一般來說,選擇一個在0.5~0.9之間的數即可。程式碼中SGD函式的最後一個引數nesterov則用於指定是否採用nesterov動量方法,nesterov momentum是對傳統動量法的一個改進方法,其效率更高,關於它的詳細介紹可參考如下連結:
http://www.360doc.com/content/16/1010/08/36492363_597225745.shtml
對於compile()函式,其作用就是編譯模型以完成實際的配置工作,為接下來的模型訓練做好準備。換句話說,compile之後模型就可以開始訓練了。這個函式有一個很重要的引數:loss,它用於指定一個損失函式。所謂損失函式,通俗地說,它是統計學中衡量損失和錯誤程度的函式,顯然,其值越小,模型就越好。如果你仔細閱讀了系列4——CNN入門,那麼,你肯定能猜到這個函式其實就是我們的優化物件。程式碼中loss的值為“categorical_crossentropy”,常用於多分類問題,其與啟用函式softmax配對使用(我們的類別只有兩種,也可採用‘binary_crossentropy’二值分類函式,該函式與sigmoid配對使用,注意如果採用它就不需要one-hot編碼)。引數metrics用於指定模型評價指標,引數值”accuracy“表示用準確率來評價(keras官方文件目前沒有查到第2種評價指標,有知道的請告知)。
接著就是資料提升,我們可以選擇不提升,也就是採用原始訓練集和驗證集,這時我們直接呼叫model.fit()函式即可開始模型訓練。該函式shuffle引數用於指定是否隨機打亂資料集。一般來說選擇資料提升要比不提升好,這樣可以讓我們利用有限數量的圖片獲得無限數量的訓練圖片。因為我們一旦選擇資料提升,ImageDataGenerator()函式返回的生成器會在模型訓練時無限生成訓練資料,直至所有訓練輪次(epoch)結束(對我們的程式碼來說就是840 x 10,生成了8400張圖片)。model.fit_generator()函式使用生成器開始模型訓練。
在這裡需要重點交代一下batch_size和nb_epoch兩個引數。nb_epoch指定模型需要訓練多少輪次,使用訓練集全部樣本訓練一次為一個訓練輪次。根據模型成熟度,我們可以適當調整該值以增加或減少訓練次數。batch_size則是一個影響模型訓練結果的重要引數。我們知道,一個訓練輪次要經過多次迭代訓練才能讓模型逐漸趨向本輪最優,這是因為理論上每次迭代訓練結束後,模型都應該朝著梯度下降的方向前進一步,直至全部樣本訓練完畢,模型梯度到達本輪最小點。之所以說理論上,是因為決定梯度方向的是訓練樣本,每次迭代訓練選取的樣本——其決定的下降方向能否很好的代表樣本全體,直接決定了模型能否到達正確的極值點。對於小的訓練集,我們完全可以採用全資料集的方式進行訓練,因為,全資料集確定的方向肯定能代表正確方向。但這樣做對大的訓練集就很不現實,因為記憶體有限,無法一次載入全部資料。於是,批梯度下降法(Mini-batches Learning)應運而生。我們一次選取適當數量的訓練樣本(視記憶體大小,可多可少),逐批次迭代,直至本輪全部樣本訓練完畢。引數batch_size的作用即在於此,其指定每次迭代訓練樣本的數量。該值的選取非常講究,不能盲目的增大或減小,因為batch_size太大或太小都會讓模型訓練效率變慢。顯然,batch_size肯定存在一個區域性最優值,這需要我們慢慢除錯,除錯時可從一個小值開始,慢慢加大,直至到達一個合理值(建議編碼實現該引數調優)。
現在模型訓練的工作已經完成,接下來我們就要考慮模型使用的問題了。要想使用模型,我們必須能夠把模型儲存下來,因此,我們繼續為Model類新增兩個函式:
1 MODEL_PATH = './store/model.h5' 2 def save_model(self, file_path = MODEL_PATH): 3 self.model.save(file_path) 4 5 def load_model(self, file_path = MODEL_PATH): 6 self.model = load_model(file_path)
一個函式用於儲存模型,一個函式用於載入模型。keras庫利用了壓縮效率更高的HDF5儲存模型,所以我們用“.h5”作為檔案字尾。上述程式碼新增完畢後,我們接著在檔案尾部新增測試程式碼,把模型訓練好並把模型儲存下來:
1 if __name__ == '__main__': 2 dataset = Dataset('./data/') 3 dataset.load()