
scrapy詳細資料流走向(個人總結)
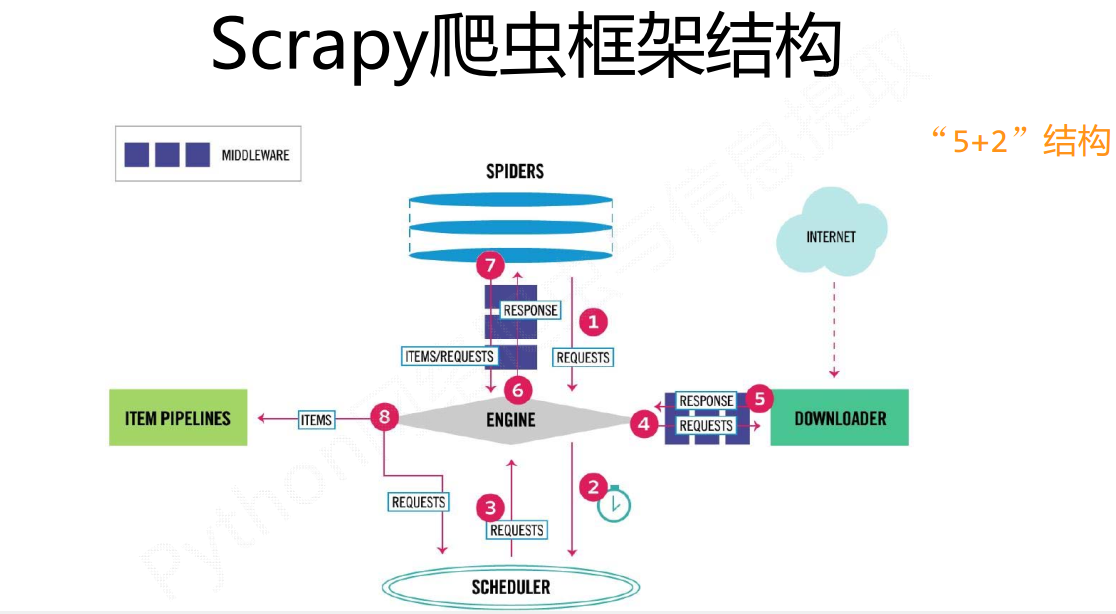
直接從資料流的角度來說比較容易理解:
·1、Spider建立一個初識url請求,把這個請求通過Engine轉給Scheduler排程模組。然後Scheduler向Engine提供一個請求(這個請求是一個真實的url請求)
疑問點一:為什麼Engine把請求發給Scheduler模組,然後又從Scheduler模組裡面取出來,這不是多此一舉麼,這個Scheduler模組有作用麼?
按照我的理解,scrapy把各個元件模組化,就是為了更加方便的配置,當然你把所有模組都寫在一起,功能同樣可以實現,只不過這就失去了這個框架的價值了,Scheduler就是為了存取請求,而Spider就是解析出新的請求和資料item。
疑問點二:為什麼說Scheduler存的是真實的url請求
Spider裡面的url不一定是我們需要的url,需要經過解析,生成我們所需要的真實url,然後通過Engine傳送給Scheduler
2、第一步Engine已經得到了真實的url地址,然後Engine把這個請求request傳送給Downloader模組
tips:我們主要到Engine傳送請求給Downloader模組前,需要進過DownloaderMiddleware中介軟體,實際上這裡可以對請求做一些修改,也就是新增User-Agent之類的引數,如果用過requests第三方包應該容易理解
3、Downloader模組把網頁下載完成後會把結果返回給Engine
tips:這個過程同樣會經過DownloaderMiddleware,所以很容易理解,我們可以在這裡修改response相關資訊
4、Engine得到資料之後,它會把資料傳送給Spider進行解析得到item(資料)或者是request(新的請求)
tips:比如我們本來要獲取的是圖片資訊,在得到的response中發現不止有圖片資訊(item),還有其他的連線(新的request)
5、Spider解析得到的item和request會有兩種走向
a:如果是item,也就是已經得到了資料,那麼就通過Engine把item傳送到Itempipeline進行處理,這裡主要是進行資料的清洗、查重、儲存等操作。
b:如果生成的是request,照著之前的,通過Engine把真實請求request傳送給Scheduler,然後Engine從Scheduler拿request,發給給Downloader下載,Downloader下載完通過Engine傳送給Spider。。如此往復,直到沒有新的request請求
有時候看到網上的教程那麼長會覺得難,不想去學,真正去學的時候會發現,其實也就那樣。好了,關於scrapy的資料流就到這。