
Shuffle機制
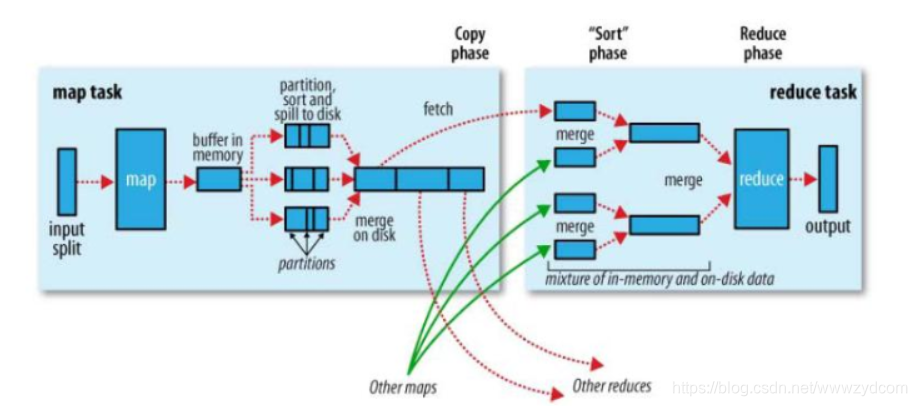
MapReduce確保每個reducer的輸入都是按鍵排序,系統執行排序的過程(將map的輸入作為輸出傳給reducer)
-
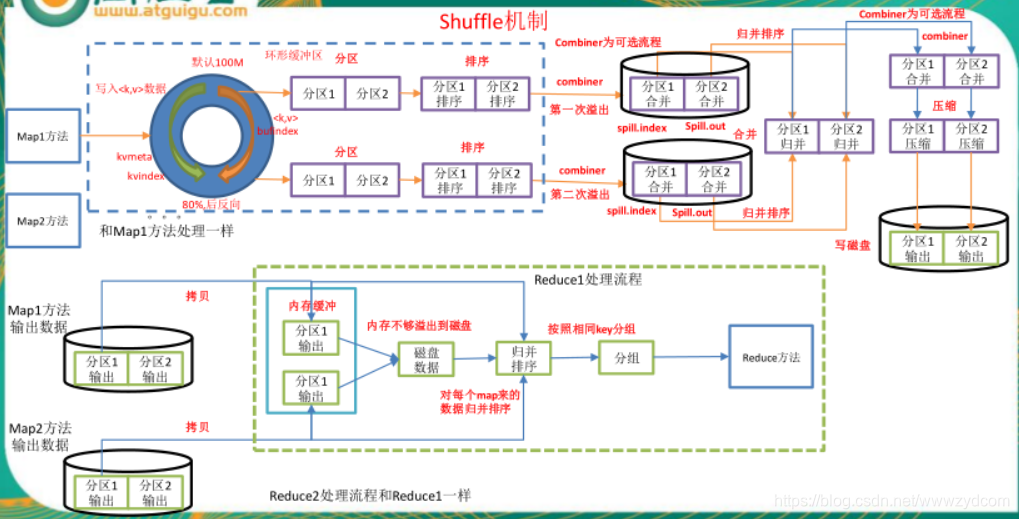
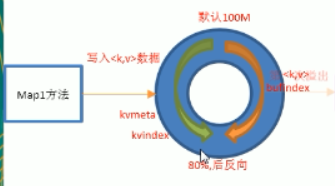
map方法 寫入<key,value>資料進入緩衝區
2.溢寫
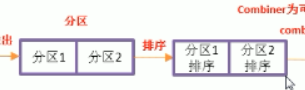
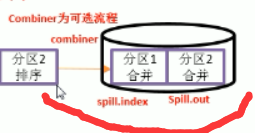
分割槽
排序
combiner為可選的流程
如果設定了,就會進行合併多次溢寫的操作
spill.index:溢寫檔案的大小,位置資訊
spill.out:溢寫檔案
…
多次溢寫
再一次combiner為可選的流程,設定了
如果設定了對資料進行了壓縮,也是優化的手段
協調了網路傳輸
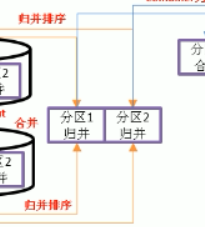
3.寫入磁碟.等待reduceTask 進行操作
4.Map方法拷貝資料
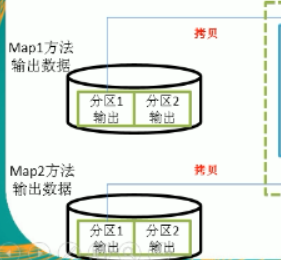
分別拷貝各自管理的分割槽,如果記憶體不夠,溢寫到磁碟中
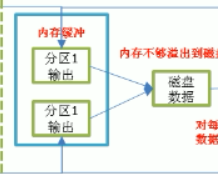
優化提高記憶體緩衝
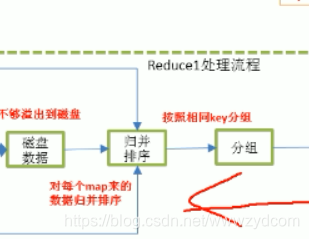
5. 歸併排序並分組
6.
相關推薦
Shuffle機制
MapReduce確保每個reducer的輸入都是按鍵排序,系統執行排序的過程(將map的輸入作為輸出傳給reducer) map方法 寫入<key,value>資料進入緩衝區 2.溢寫 分割槽 排序 combiner為可選的流程 如果設定了,就會進行
maprudece的shuffle機制
Maprudece的Shuffle機制 1.shuffle:map的輸出作為reduce的輸入的中間的過程 2.shuffle的階段 1)由map()方法將key/vaule寫到環形緩衝區當中 2)環形緩衝區預設為100MB,若達到閾值(80%)就會發生溢寫,產生臨時檔案(將8
MapReduce 的 shuffle 機制
由於 MapReduce 確保每個 reducer 的輸入都是按鍵排序的,因此在 map 處理完資料之後傳給 reducer 的這個過程中需要進行一系列操作,這個操作過程就是 shuffle。在《hadoop權威指南》中指出,shuffle 是 MapReduce 的 “心臟”,瞭解 shuffle 工作機制
spark的shuffle機制
對於大資料計算框架而言,Shuffle階段的設計優劣是決定效能好壞的關鍵因素之一。本文將介紹目前Spark的shuffle實現,並將之與MapReduce進行簡單對比。本文的介紹順序是:shuffle基本概念,MapReduce Shuffle發展史以及Spark Shuffle發展史。 (
MapReduce的整體流程、及shuffle機制
MapReduce的整體流程 1、待處理資料 2、提交客戶端submit() 3、提交資訊切片----hadoop jar wc.jar 4、計算出
大資料-Hadoop生態(17)-MapReduce框架原理-MapReduce流程,Shuffle機制,Partition分割槽
MapReduce工作流程 1.準備待處理檔案 2.job提交前生成一個處理規劃 3.將切片資訊job.split,配置資訊job.xml和我們自己寫的jar包交給yarn 4.yarn根據切片規劃計算出MapTask的數量 (以一個MapTask為例) 5.Maptask呼叫
Spark之Shuffle機制和原理
Spark Shuffle簡介 Shuffle就是對資料進行重組,由於分散式計算的特性和要求,在實現細節上更加繁瑣和複雜 在MapReduce框架,Shuffle是連線Map和Reduce之間的橋樑,Map階段通過shuffle讀取資料並輸出到對應的Reduce
MapReduce的Shuffle機制
1、MapReduce的shuffle機制 1.1、概述 MapReduce中,mapper階段處理的資料如何傳遞給reduce階段,是MapReduce框架中最關鍵的一個流程,這個流程就叫shuffle. Shuffle:資料混洗---------(核心機制:資料分割槽,排
簡單搞定Shuffle機制執行原理
2)流程詳解 上面的流程是整個mapreduce最全工作流程,但是shuffle過程只是從第7步開始到第16步結束,具體shuffle過程詳解,如下: 1)maptask收集我們的map()方法輸出的kv對,放到記憶體緩衝區中 2)從記憶體緩衝區不斷溢位本地磁碟檔案,可能會溢位多個檔案 3)多個溢
大資料(十):MapTask工作機制與Shuffle機制(partitioner輸出分割槽、WritableComparable排序)
一、MapTask工作機制 Read階段:MapTask通過使用者編寫的RecordReader,從輸入InputSplit中解析出一個個key/value Map階段:該節點主要是將解析出的key/value交給使用者編寫map()函式處理,併產生一系列
Hadoop之分塊、分片與shuffle機制詳解
一 分塊(Block) HDFS儲存系統中,引入了檔案系統的分塊概念(block),塊是儲存的最小單位,HDFS定義其大小為64MB。與單磁碟檔案系統相似,儲存在 HDFS上的檔案均儲存為多個塊,不同的是,如果某檔案大小沒有到達64MB,該檔案也不會佔據整個塊空間
spark基礎之shuffle機制和原理分析
一 概述 Shuffle就是對資料進行重組,由於分散式計算的特性和要求,在實現細節上更加繁瑣和複雜 在MapReduce框架,Shuffle是連線Map和Reduce之間的橋樑,Map階段通過shuf
Shuffle機制流程原理
基礎知識: Mapreduce確保每個reducer的輸入都是按鍵排序的。系統執行排序的過程(即將map輸出作為輸入傳給reducer)稱為shuffle。 shuffle階段是從map方法輸出資料以後開始到reduce方法輸入資料之前結束。 分割槽的數量 = Red
Spark Shuffle機制詳細原始碼解析
Shuffle過程主要分為Shuffle write和Shuffle read兩個階段,2.0版本之後hash shuffle被刪除,只保留sort shuffle,下面結合程式碼分析: # 1.ShuffleManager Spark在初始化SparkEnv的時候,會在create()方法裡面初始化Sh
大資料教程(8.8)MR內部的shuffle過程詳解&combiner的執行機制及程式碼實現
之前的文章已經簡單介紹過mapreduce的運作流程,不過其內部的shuffle過程並未深入講解;本篇部落格將分享shuffle的全過程。
大資料教程(8.8)MR內部的shuffle過程詳解&combiner的執行機制及程式碼實現
之前的文章已經簡單介紹過mapreduce的運作流程,不過其內部的shuffle過程並未深入講解;本篇部落格將分享shuffle的全過程。
【hadoop】MapReduce工作流程和MapTask、Shuffle、ReduceTask工作機制
MapReduce整個工作流程:一、MapTask階段(1)Read階段:MapTask通過使用者編寫的RecordReader,從輸入InputSplit中解析出一個個key/value。(2)Map階段:該節點主要是將解析出的key/value交給使用者編寫map()函式
大資料06-MapTask、Shuffle、ReduceTask,yarn工作機制
一、MapReduce整個工作流程: 二、 yarn基本架構和工作機制 一、yarn基本架構 (0)Mr 程式提交到客戶端所在的節點。 (1)Yarnrunner 向 Resourcemanager 申請一個 Application。
MapReduce shuffle過程及壓縮機制
shuffle過程 map階段處理的資料如何傳遞給reduce階段,是MapReduce框架中最關鍵的一個流程,這個流程就叫shuffle。 shuffle: ——核心機制:資料分割槽,排序,規約,分組,合併等過程。 shuffle是Mapreduce的核心,
微信網頁授權獲取用戶信息等機制
json 開發者 userinfo 技術分享 nal amp 分隔 response unionid 參考官方文檔 https://mp.weixin.qq.com/wiki/17/c0f37d5704f0b64713d5d2c37b468d75.html 1.用戶進入授權