
MapReduce簡單入門基礎瞭解
阿新 • • 發佈:2018-11-10
MapReduce定義
MapReduce是一個分散式運算程式的程式設計框架,使用者開發"基於hadoop的資料分析應用"的核心框架
MapReduce核心是將使用者編寫的業務邏輯程式碼和自帶預設元件整合一個完整的分散式運算程式,併發運作在一個hadoop叢集上
優點
- 易於程式設計 :簡單實現一些介面完成一個分散式程式,這個程式分佈大量廉價的PC機器上,和一個單執行緒程式一樣
- 擴充套件性好:計算資源不足時,增加機器即可
- 高容錯性:一臺機器掛了,計算任務轉移到另外一個節點上執行,不至於任務執行失敗,整個過程是hadoop內部完成,不要人工參與
- 適合PB級別的資料離線處理:不適合線上處理
缺點
- 實時計算 :無法像mysql一樣毫秒級別返回結果
- 流式運算:流失計算的輸入資料是動態的,但是MapReduce輸入資料集是靜態的,
設計特點決定是靜態的 - DAG(有向圖)計算:當多個程式有依賴關係,後一個程式的輸入為前一個程式的輸出,MR程式不是不能做,每個MR程式輸出結果寫入磁碟,會造成大量磁碟IO,導致效能低下
MapReduce核心思想:
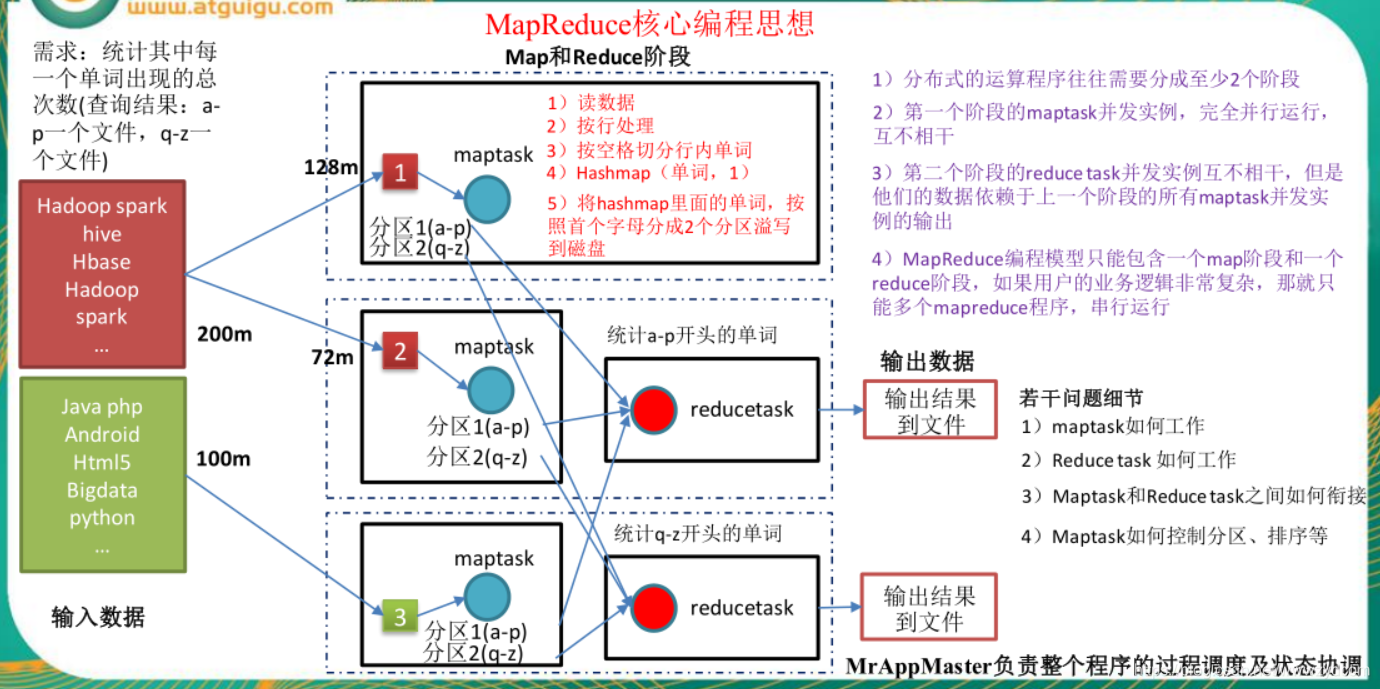
- 分散式的運算程式一般需要至少兩個階段
- 第一階段:maptask併發例項:完全並行執行,互不相干
- 第二階段:reduce task併發例項,互不相干,但是他們的資料依賴於上一個階段的所有maptask併發例項的輸出
- MapReduce程式設計模型只能包含一個map階段和一個reduce階段,使用者業務邏輯複雜,只能多個MapReduce程式,序列執行
MapReduce程序
一個完整的MapReduce程式在分散式時三類例項程序
(1) MrAppMaster:負責整個程式的過程排程以及狀態協調
(2) MapTask:負責map階段的整個資料處理流程
(3)ReduceTask:負責reduce階段的整個資料處理流程
MapReduce程式設計規範
(1) Mapper階段
(1)使用者自定義的Mapper要繼承自己的父類 (2)Mapper的輸入資料是KV對的形式(KV的型別可以自定義) (3)Mapper中的業務邏輯寫在map()方法中 (4)Mapper的輸出資料是KV對的形式(KV的型別自定義) (5)map()方法(maptask程序)對每一個<K,V>呼叫一次
(2)Reducer階段
(1)使用者自定義的Reducer要繼承自己的父類
(2)Reducer的輸入資料型別對應Mapper的輸出資料型別,也是KV
(3)Reducer的業務邏輯寫在reduce()方法中
(4)Reducetask程序對每一組相同的k的<k,v>組呼叫一次reduce()方法中
(3)Driver階段(提交執行mr程式的客戶端)
整個程式需要一個Drvier來進行提交,提交是描述了各種必要資訊的job物件