
Spark優化(十):資源引數調優
在開發完Spark作業之後,就該為作業配置合適的資源了。Spark的資源引數,基本都可以在spark-submit命令中作為引數設定。很多Spark初學者通常不知道該設定哪些必要的引數以及如何設定這些引數,最後就只能胡亂設定,甚至壓根兒不設定。
資源引數設定的不合理,可能會導致沒有充分利用叢集資源,作業執行會極其緩慢;或者設定的資源過大,佇列沒有足夠的資源來提供,進而導致各種異常。
總之,無論是哪種情況,都會導致Spark作業的執行效率低下,甚至根本無法執行。因此我們必須對Spark作業的資源使用原理有一個清晰的認識,並知道在Spark作業執行過程中,有哪些資源引數是可以設定的,以及如何設定合適的引數值。
1、Spark作業基本執行原理
詳細原理如下圖所示:
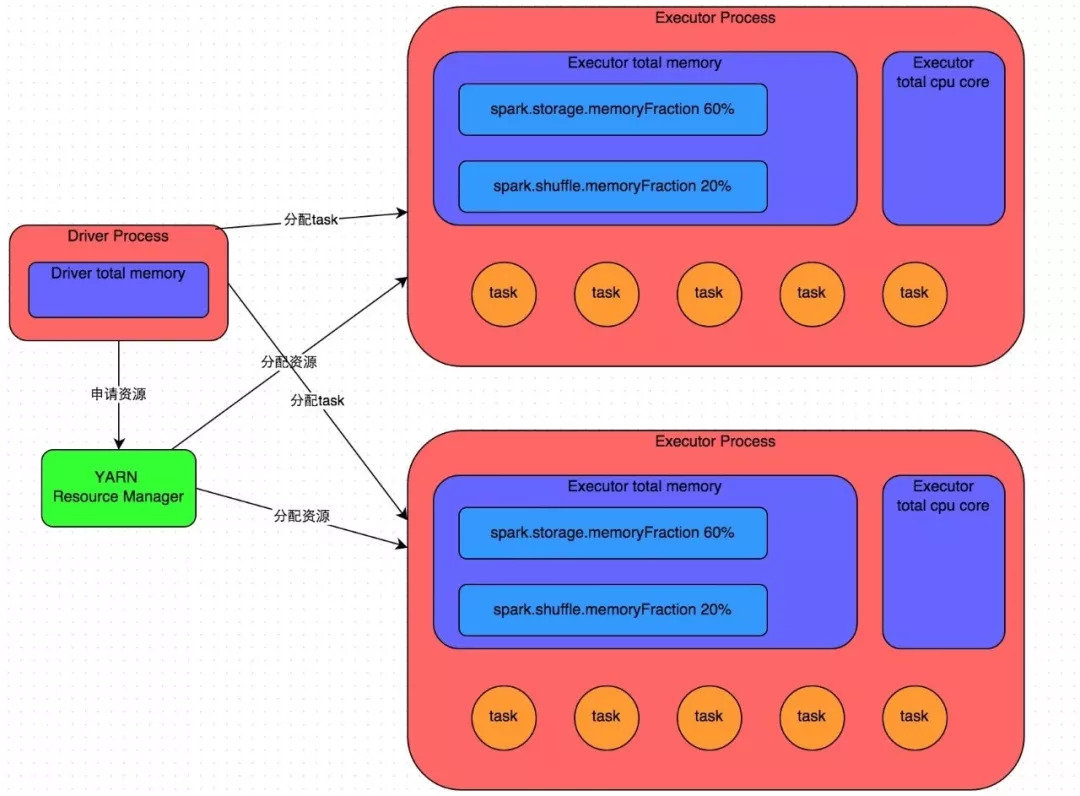
我們使用spark-submit提交一個Spark作業之後,這個作業就會啟動一個對應的Driver程序。
根據你使用的部署模式(deploy-mode)不同,Driver程序可能在本地啟動,也可能在叢集中某個工作節點上啟動。Driver程序本身會根據我們設定的引數,佔有一定數量的記憶體和CPU core。而Driver程序要做的第一件事情,就是向叢集管理器(可以是Spark Standalone叢集,也可以是其他的資源管理叢集,美團•大眾點評使用的是YARN作為資源管理叢集)申請執行Spark作業需要使用的資源,這裡的資源指的就是Executor程序。
YARN叢集管理器會根據我們為Spark作業設定的資源引數,在各個工作節點上,啟動一定數量的Executor程序,每個Executor程序都佔有一定數量的記憶體和CPU core。
在申請到了作業執行所需的資源之後,Driver程序就會開始排程和執行我們編寫的作業程式碼了。
Driver程序會將我們編寫的Spark作業程式碼分拆為多個stage,每個stage執行一部分程式碼片段,併為每個stage建立一批task,然後將這些task分配到各個Executor程序中執行。
task是最小的計算單元,負責執行一模一樣的計算邏輯(也就是我們自己編寫的某個程式碼片段),只是每個task處理的資料不同而已。一個stage的所有task都執行完畢之後,會在各個節點本地的磁碟檔案中寫入計算中間結果,然後Driver就會排程執行下一個stage。下一個stage的task的輸入資料就是上一個stage輸出的中間結果。
如此迴圈往復,直到將我們自己編寫的程式碼邏輯全部執行完,並且計算完所有的資料,得到我們想要的結果為止。
Spark是根據shuffle類運算元來進行stage的劃分。
如果我們的程式碼中執行了某個shuffle類運算元(比如reduceByKey、join等),那麼就會在該運算元處,劃分出一個stage界限來。可以大致理解為shuffle運算元執行之前的程式碼會被劃分為一個stage,shuffle運算元執行以及之後的程式碼會被劃分為下一個stage。
因此一個stage剛開始執行的時候,它的每個task可能都會從上一個stage的task所在的節點,去通過網路傳輸拉取需要自己處理的所有key,然後對拉取到的所有相同的key使用我們自己編寫的運算元函式執行聚合操作(比如reduceByKey()運算元接收的函式)。這個過程就是shuffle。
當我們在程式碼中執行了cache/persist等持久化操作時,根據我們選擇的持久化級別的不同,每個task計算出來的資料也會儲存到Executor程序的記憶體或者所在節點的磁碟檔案中。
因此Executor的記憶體主要分為三塊:
-
第一塊是讓task執行我們自己編寫的程式碼時使用,預設是佔Executor總記憶體的20%;
-
第二塊是讓task通過shuffle過程拉取了上一個stage的task的輸出後,進行聚合等操作時使用,預設也是佔Executor總記憶體的20%;
-
第三塊是讓RDD持久化時使用,預設佔Executor總記憶體的60%。
task的執行速度是跟每個Executor程序的CPU core數量有直接關係的。一個CPU core同一時間只能執行一個執行緒。而每個Executor程序上分配到的多個task,都是以每個task一條執行緒的方式,多執行緒併發執行的。如果CPU core數量比較充足,而且分配到的task數量比較合理,那麼通常來說,可以比較快速和高效地執行完這些task執行緒。
以上就是Spark作業的基本執行原理的說明,大家可以結合原理圖來理解。理解作業基本原理,是我們進行資源引數調優的基本前提。
2、資源引數調優
瞭解完Spark作業執行的基本原理之後,對資源相關的引數就容易理解了。所謂的Spark資源引數調優,其實主要就是對Spark執行過程中各個使用資源的地方,通過調節各種引數來優化資源使用的效率,從而提升Spark作業的執行效能。
以下引數就是Spark中主要的資源引數,每個引數都對應著作業執行原理中的某個部分,我們同時也給出了一個調優的參考值:
num-executors
引數說明:該引數用於設定Spark作業總共要用多少個Executor程序來執行。Driver在向YARN叢集管理器申請資源時,YARN叢集管理器會盡可能按照你的設定來在叢集的各個工作節點上,啟動相應數量的Executor程序。這個引數非常之重要,如果不設定的話,預設只會給你啟動少量的Executor程序,此時你的Spark作業的執行速度是非常慢的。
引數調優建議:每個Spark作業的執行一般設定50~100個左右的Executor程序比較合適,設定太少或太多的Executor程序都不好。設定的太少,無法充分利用叢集資源;設定的太多的話,大部分佇列可能無法給予充分的資源。
executor-memory
引數說明:該引數用於設定每個Executor程序的記憶體。Executor記憶體的大小,很多時候直接決定了Spark作業的效能,而且跟常見的JVM OOM異常也有直接的關聯。
引數調優建議:每個Executor程序的記憶體設定4G~8G較為合適。但是這只是一個參考值,具體的設定還是得根據不同部門的資源佇列來定。可以看看自己團隊的資源佇列的最大記憶體限制是多少,num-executors乘以executor-memory,就代表了你的Spark作業申請到的總記憶體量(也就是所有Executor程序的記憶體總和),這個量是不能超過佇列的最大記憶體量的。此外,如果你是跟團隊裡其他人共享這個資源佇列,那麼申請的總記憶體量最好不要超過資源佇列最大總記憶體的1/3~1/2,避免你自己的Spark作業佔用了佇列所有的資源,導致別的同學的作業無法執行。
executor-cores
引數說明:該引數用於設定每個Executor程序的CPU core數量。這個引數決定了每個Executor程序並行執行task執行緒的能力。因為每個CPU core同一時間只能執行一個task執行緒,因此每個Executor程序的CPU core數量越多,越能夠快速地執行完分配給自己的所有task執行緒。
引數調優建議:Executor的CPU core數量設定為2~4個較為合適。同樣得根據不同部門的資源佇列來定,可以看看自己的資源佇列的最大CPU core限制是多少,再依據設定的Executor數量,來決定每個Executor程序可以分配到幾個CPU core。同樣建議,如果是跟他人共享這個佇列,那麼num-executors * executor-cores不要超過佇列總CPU core的1/3~1/2左右比較合適,也是避免影響其他同學的作業執行。
driver-memory
引數說明:該引數用於設定Driver程序的記憶體。
引數調優建議:Driver的記憶體通常來說不設定,或者設定1G左右應該就夠了。唯一需要注意的一點是,如果需要使用collect運算元將RDD的資料全部拉取到Driver上進行處理,那麼必須確保Driver的記憶體足夠大,否則會出現OOM記憶體溢位的問題。
spark.default.parallelism
引數說明:該引數用於設定每個stage的預設task數量。這個引數極為重要,如果不設定可能會直接影響你的Spark作業效能。
引數調優建議:Spark作業的預設task數量為500~1000個較為合適。很多同學常犯的一個錯誤就是不去設定這個引數,那麼此時就會導致Spark自己根據底層HDFS的block數量來設定task的數量,預設是一個HDFS block對應一個task。通常來說,Spark預設設定的數量是偏少的(比如就幾十個task),如果task數量偏少的話,就會導致你前面設定好的Executor的引數都前功盡棄。試想一下,無論你的Executor程序有多少個,記憶體和CPU有多大,但是task只有1個或者10個,那麼90%的Executor程序可能根本就沒有task執行,也就是白白浪費了資源。因此Spark官網建議的設定原則是,設定該引數為num-executors * executor-cores的2~3倍較為合適,比如Executor的總CPU core數量為300個,那麼設定1000個task是可以的,此時可以充分地利用Spark叢集的資源。
spark.storage.memoryFraction
引數說明:該引數用於設定RDD持久化資料在Executor記憶體中能佔的比例,預設是0.6。也就是說,預設Executor 60%的記憶體,可以用來儲存持久化的RDD資料。根據你選擇的不同的持久化策略,如果記憶體不夠時,可能資料就不會持久化,或者資料會寫入磁碟。
引數調優建議:如果Spark作業中,有較多的RDD持久化操作,該引數的值可以適當提高一些,保證持久化的資料能夠容納在記憶體中。避免記憶體不夠快取所有的資料,導致資料只能寫入磁碟中,降低了效能。但是如果Spark作業中的shuffle類操作比較多,而持久化操作比較少,那麼這個引數的值適當降低一些比較合適。此外,如果發現作業由於頻繁的gc導致執行緩慢(通過spark web ui可以觀察到作業的gc耗時),意味著task執行使用者程式碼的記憶體不夠用,那麼同樣建議調低這個引數的值。
spark.shuffle.memoryFraction
引數說明:該引數用於設定shuffle過程中一個task拉取到上個stage的task的輸出後,進行聚合操作時能夠使用的Executor記憶體的比例,預設是0.2。也就是說,Executor預設只有20%的記憶體用來進行該操作。shuffle操作在進行聚合時,如果發現使用的記憶體超出了這個20%的限制,那麼多餘的資料就會溢寫到磁碟檔案中去,此時就會極大地降低效能。
引數調優建議:如果Spark作業中的RDD持久化操作較少,shuffle操作較多時,建議降低持久化操作的記憶體佔比,提高shuffle操作的記憶體佔比比例,避免shuffle過程中資料過多時記憶體不夠用,必須溢寫到磁碟上,降低了效能。此外,如果發現作業由於頻繁的gc導致執行緩慢,意味著task執行使用者程式碼的記憶體不夠用,那麼同樣建議調低這個引數的值。
資源引數的調優,沒有一個固定的值,需要同學們根據自己的實際情況(包括Spark作業中的shuffle運算元量、RDD持久化運算元量以及spark web ui中顯示的作業gc情況),同時參考本篇文章中給出的原理以及調優建議,合理地設定上述引數。
3、資源引數參考示例
以下是一份spark-submit命令的示例,大家可以參考一下,並根據自己的實際情況進行調節:
./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
根據實踐經驗來看,大部分Spark作業經過本次基礎篇所講解的開發調優與資源調優之後,一般都能以較高的效能運行了,足以滿足我們的需求。但在不同的生產環境和專案背景下,還是有可能會遇到其他更加棘手的問題(比如各種資料傾斜),也可能會遇到更高的效能要求。