Spark優化(五):使用map-side預聚合的shuffle操作
阿新 • • 發佈:2018-11-10
使用map-side預聚合的shuffle操作
如果因為業務需要,一定要使用shuffle操作,無法用map類的運算元來替代,那麼儘量使用可以map-side預聚合的運算元。
所謂的map-side預聚合,說的是在每個節點本地對相同的key進行一次聚合操作,類似於MapReduce中的本地combiner。
map-side預聚合之後,每個節點本地就只會有一條相同的key,因為多條相同的key都被聚合起來了。其它節點在拉取所有節點上的相同key時,就會大大減少需要拉取的資料數量,從而也就減少了磁碟IO以及網路傳輸開銷。
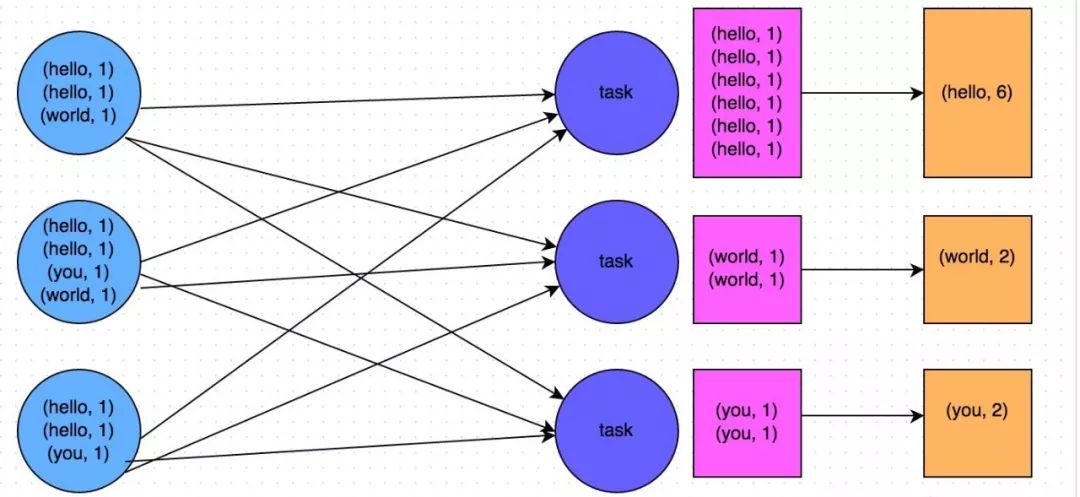
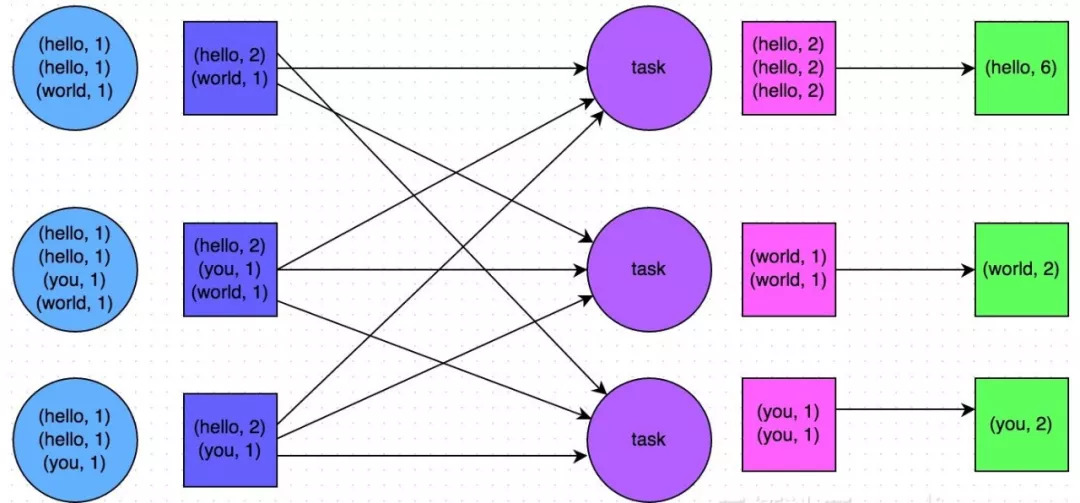
通常來說,在可能的情況下,建議使用reduceByKey或者aggregateByKey運算元來替代掉groupByKey運算元。因為reduceByKey和aggregateByKey運算元都會使用使用者自定義的函式對每個節點本地的相同key進行預聚合。而groupByKey運算元是不會進行預聚合的,全量的資料會在叢集的各個節點之間分發和傳輸,效能相對來說比較差。
比如以下兩幅圖就是典型的例子,分別基於reduceByKey和groupByKey進行單詞計數。其中第一張圖是groupByKey的原理圖,可以看到,沒有進行任何本地聚合時,所有資料都會在叢集節點之間傳輸;第二張圖是reduceByKey的原理圖,可以看到,每個節點本地的相同key資料,都進行了預聚合,然後才傳輸到其他節點上進行全域性聚合。