
Kafka瞭解一下
阿新 • • 發佈:2018-11-10

Kafka背景
Kafka最初是由LinkedIn公司使用Scala語言實現的,用作LinkedIn的活動流(Activity Stream)和運營資料處理管道(Pipeline)的基礎。現在它已被多家不同型別的公司作為多種型別的資料管道和訊息系統使用。領英在2011年捐贈給Apache,然後在2012年成為First-class Apache專案。
Kafka是什麼?
Kafka官方定義:分散式的流媒體平臺Apache Kafka是分散式訂閱、釋出、訊息傳遞的系統和強大的佇列,可以處理大量資料,並使您能夠將訊息從一個端點傳遞到另一個終端。
Kafka適用於離線和線上訊息消費。
Kafka訊息被保留在磁碟上,並在叢集內複製以防止資料丟失。
Kafka建立在ZooKeeper同步服務之上。
它與Apache Storm和Spark完美結合,實時流式傳輸資料分析。
Kafka優缺點
1、高吞吐量、低延遲:kafka每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒,每個topic可以分多個partition, consumer group 對partition進行consume操作。
2、可擴充套件:Kafka叢集支援熱擴充套件,可以在叢集啟動後把新伺服器加入到叢集。
3、容錯性:允許節點失敗,Kafka每個Partition資料會複製到幾臺伺服器,當某個Broker失效時, Zookeeper將通知生產者和消費者使用其他的Broker。
缺點:
1、重複訊息:Kafka保證每條訊息至少送達一次,雖然機率很小,但一條訊息可能被送達多次。
2、訊息亂序:Kafka某一個固定的Partition內部的訊息是保證有序的,如果一個Topic有多個Partition,partition之間的訊息送達不保證有序。
3、複雜性:Kafka需要Zookeeper的支援,Topic一般需要人工建立,部署和維護比一般MQ成本更高。
Kafka拓撲結構
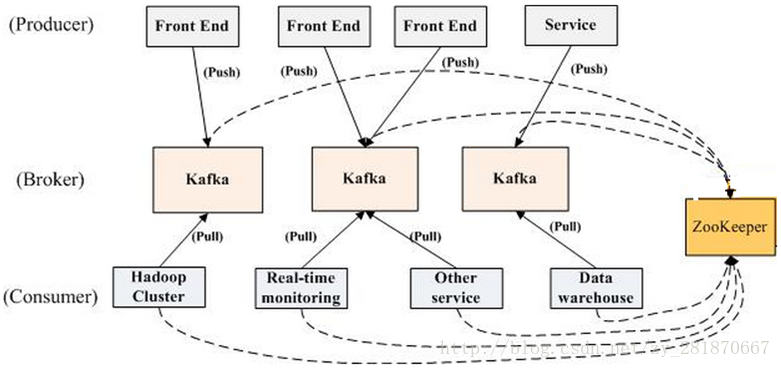
Producer:可以是web前端產生的Page View、搜尋等使用者活動跟蹤,或者是伺服器日誌、系統CPU報警、警告等運營指標
Zookeeper:Kafka通過Zookeeper管理叢集配置,檢測partition leader存活,以及在Consumer Group發生變化時進行rebalance
名詞解釋
Broker:Kafka叢集包含一個或多個伺服器,這種伺服器被稱為brokerProducer:負責釋出訊息到Kafka broker
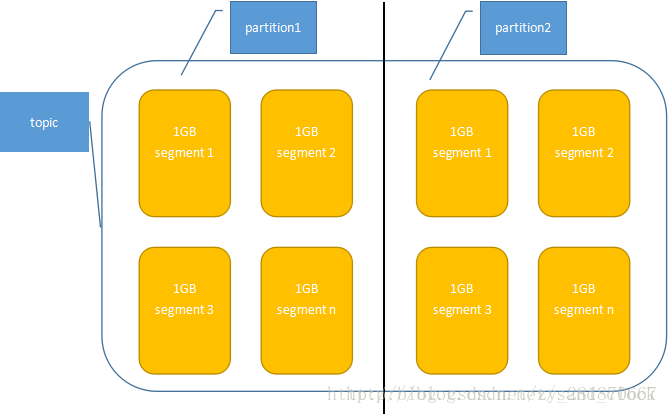
Topic:每條釋出到Kafka叢集的訊息都有一個類別,這個類別被稱為Topic(類似MQ中的queue)
Partition:Parition是物理上的概念,每個Topic包含一個或多個Partition
Segment:多個大小相等的段組成了一個partition,segment檔名為上一個segment檔案最後一條訊息的offset值。
Offset:一個連續的用於定位被追加到分割槽的每一個訊息的序列號,最大值為64位的long大小,19位數字字元長度。
Consumer:訊息消費者,向Kafka broker讀取訊息的客戶端。
Consumer Group:每個Consumer屬於一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬於預設的group)
Topic、partition、segment關係圖
Kafka Producer
生產者將訊息傳送到broker上訊息的存放位置:客戶端可以控制訊息傳送到哪個partition,有兩種,一種是隨機的;,一種是通過自定義函式指定partition
Kafka的批量傳送:kafka支援使用批處理來提高處理效率,在配置的閥值內實現訊息的批量傳送
1. hash(message)% numPartition
2.閾值可以是大小或者時間,一般是64K的大小或者10毫秒(max.message.bytes)
Kafka Consumer
消費者從broker拉取訊息Kafka也有兩種模式,佇列模式(Queue)和釋出-訂閱模式(Pub)
佇列模式:consumers可以同時爭奪訊息,但是隻有一個consumer消費。
釋出-訂閱模式:訊息會被廣播到consumers中,多個consumer可以加入一個consumer group,以組的身份共同競爭一個topic,topic的訊息會被訂閱的consumer group內的一個consumer消費。
Consumer需要維護消費的狀態:訊息是否被消費了,是在consumer這邊記錄的,這樣的不會對叢集和其他consumer產生影響,非常輕量級。
1.每一個consumer都是有一個consumer group的,不指定則歸屬預設的consumer group下。
2.釋出訂閱模式中,若所有的consumer都在一個consumer group中,那就是佇列模式的效果。
3.消費狀態是根據offset(偏移量)來確定的,類似於陣列的下標。憑藉offset,我們可以隨心所欲的消費
Topic & Partition
Topic相當於傳統MQ的queue,producer傳送訊息必須指定TopicPartition(分割槽)出現的原因:如果一個topic對應一個檔案,隨著資料量的不斷增大,這個檔案所在的機器I/O將會成為這個topic的效能瓶頸,而partition的誕生正是為了處理這個問題:它把topic的訊息拆分儲存
Topic下的partition是沒有上限的,根據具體業務情況來定,一般來說
(1)Topic的partition數量大於等於broker數量,可以提高吞吐率
(2)同一個partition的replica儘量分散到不同機器,高可用
當新加一個partition時,之前的partition資料不會變,新加的partition剛開始是空的,隨後進去Topic下的message就會重新參與所有partition的load balance
1.一個topic如果有三個partition,這三個partition可能不在同一個broker上。
2.在物理結構上,每個partition對應一個物理的目錄(資料夾),資料夾命名是[topicname]_[partition]_[序號]
3.Partition的數量:在建立Topic的時候指定
Topic的解剖圖
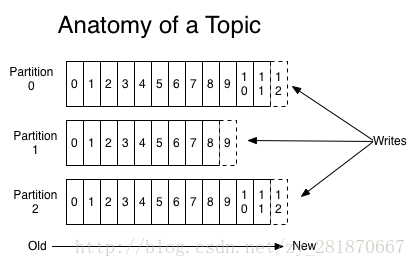
1.單個Partition內部是有序的,多個partition不保證有序
2.多個Partition內的訊息數量並不保證一致
Partition & Replica
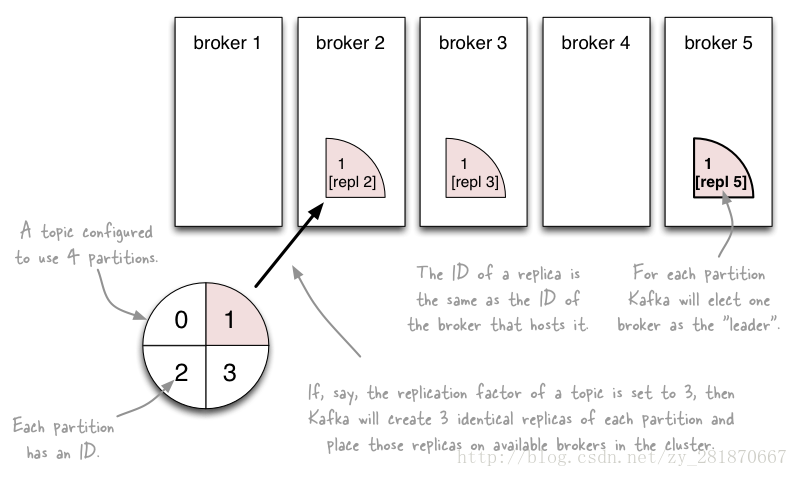
為了實現故障自動轉移,Kafka在0.8版本之後,針對partition增加了Replica(副本)。每個partition可以在其他broker節點存副本,以便某個broker宕機不會影響叢集。存replica副本的方式是按照broker的順序存的,比如:有5個kafka broker,某個topic有3個partition,每個partition存2個副本,那麼partition1存broker1和broker2,partition2存broker2和broker3,以此類推
副本數最大,安全係數越高,但是效能越低;副本數少的話,安全係數較低。
1.Kafka副本數不能大於broker數
2.Replica的數量:在建立Topic的時候指定(副本數量是包括本身的)
副本分配圖
假設叢集一共有4個brokers,一個topic有4個partition,每個Partition有3個副本。下圖是每個Broker上的副本分配情況。
Controller機制
在Kafka早期,對於分割槽的狀態管理依賴ZK的Watcher,每個broker都要在ZK上註冊Watcher,所以ZK會出現太多的Watcher。假如某個broker宕機,而這個宕機的broker上又有很多partition的話,就會造成很多watcher的觸發,造成叢集內大規模調整。這種設計容易出現羊群效應和ZK叢集過敏KafkaController作為kafka叢集的控制者,有且存在一個leader,若干個follower,leader處理所有的讀和寫操作,然後副本到followers。這樣ZK的壓力會減小很多
Controller的職責:更新元資料、建立刪除topic的行動執行等
官網的一段描述:we elect one of the brokers as the “controller”. This controller detects failures at the broker level and is responsible for changing the leader of all affected partitions in a failed broker. (controller在broker級別就檢測出故障,並且負責更改故障broker內的受影響的partition的leader)
Leader機制
和controller機制類似,不能一股腦的把所有節點的監聽壓力都放到ZK上,也不適合把壓力放到controller上面,因為controller的壓力已經很大了,所以出現了leader機制。
在Kafka中發生複製時確保partition的日誌能有序地寫到其他節點上,N個replicas中,其中一個replica為leader,其他都為follower, leader處理partition的所有讀寫請求,與此同時,follower會被動定期地去複製leader上的資料。
官網的一段描述:Each partition has one server which acts as the "leader" and zero or more servers which act as "followers". The leader handles all read and write requests for the partition while the followers passively replicate the leader.
ISR副本同步佇列
ISR (In-Sync Replicas),這個是指副本同步佇列,是由Kafka維護的列表,往partition寫入一條訊息,只有被ISR列表中的所有副本寫入,才會被視為已提交。在leader發生故障或者宕機的時候,就會在ISR列表選舉出一個新的leader(ISR狀態儲存在ZK)訊息延遲的處理:followers從leader同步訊息會有一定延遲(延遲時間和延遲條目 ,新版的0.10.x只支援延遲時間,不支援延遲條目),超出閾值則會被剔除出ISR。
新版為什麼移除ISR的“延遲條目”機制?
1。容易被誤傷。假如延遲條目設定為10,如果流量高峰,producer一次性發送20條訊息到broker,在leader接收到訊息而又未同步到followers的那個時間區間,如果被檢測到未同步訊息,那就會被移除ISR,而實際上該follower是存活的且效能沒問題的。
2。無法給出一個適合的值。“延遲條目”是全域性的,設定太大了,會影響真正“落後”follower的移除;設定小了,導致follower頻繁的進出ISR列表。
3。延遲時間(replica.lag.time.max.ms)是10秒
Leader的選舉
Kafka是在ISR列表順序選擇一個副本。為什麼不使用少數服從多數的方法?
少數服從多數是一種比較常見的Leader選舉法,要求超過半數的投票。
這種方法冗餘度較高,比如:如果容忍二臺機器失敗,則需要五臺機器。
而使用Kafka的這種方式,則只需要三臺機器。
極端情況:假如所有的ISR副本都宕機了,該腫麼辦?
Kafka提供了兩種方案,一種是:等待ISR列表中的副本復活;另一種是:選擇一個立即可用的,但是不一定在ISR列表中的副本。
前者保持了一致性,但是,可能需要等待很長時間;後者不需要等待很長時間,但是,又無法保證一致性(高可用性和強一致性的二選一)
kafka預設後者(unclean.leader.election.enable=true)
Ack機制
Kafka保證訊息的送達,提供了三種ACK級別1:當ack=0,這意味著producer傳送出訊息即送達,不等待伺服器的確認。這種情況下資料傳輸效率最高,但是資料可靠性確是最低的。
2:當ack=1,表示producer寫leader成功,broker就返回成功,沒有等待所有
followers寫入成功(預設)
3:當ack=-1,producer需要等待ISR中的所有副本都確認接收到資料後才算一
次傳送完成,可靠性最高。但是這樣也不能100%保證資料不丟失,比如當ISR中只有一個leader時(ISR中的成員由於某些情況會增加也會減少,可能最少就只剩一個leader),這樣就變成了ack=1的情況
1。當ack=1,一旦有某個broker宕機導致Partition Follow和leader切換,可能會導致丟資料
2。如果一定要高可靠性,則設定ack=-1且同時設定最小副本數大於1
3。若不滿足ACK,produc會丟擲異常 NotEnoughReplicas or NotEnoughReplicasAfterAppend
kafka安裝和基本操作
啟動ZK
zookeeper-server-start ../../config/zookeeper.properties
啟動kafka
kafka-server-start ../../config/server.properties
建立topic
kafka-topics --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --create --topic myTopic
刪除指定topic
kafka-topics --zookeeper localhost:2181 --delete --topic topic-test
檢視已建立的topic列表
kafka-topics --zookeeper localhost:2181 --list
檢視topic的資訊
kafka-topics --zookeeper localhost:2181 --describe --topic myTopic
進入指定Topic的 消費控制檯
kafka-console-consumer --bootstrap-server localhost:9092 --topic myTopic --from-beginning
進入指定Topic的 生產控制檯
kafka-console-producer --broker-list localhost:9092 --topic myTopic