【轉】提取caffe前饋的中間結果+逐層視覺化
阿新 • • 發佈:2018-11-10
轉自: https://blog.csdn.net/thy_2014/article/details/51659300
參考官方網址:http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/00-classification.ipynb
當caffe訓練出一個模型,想用這個模型進行分類參見:使用caffe訓練好的模型進行分類
本文接著介紹如何在將caffe前饋時的中間結果顯示出來。
以下提到的程式碼並不能單獨使用,需要加上使用caffe訓練好的模型進行分類中的程式碼才能夠正常執行。
1 提取中間的輸出:
首先來看看怎麼讀出網路名稱以及引數尺寸:
對於網路中的每層,典型的格式是:(batch_size, channel_dim, height, width)
這些寫成了一個OrderedDict, net.blods.
-
-
# for each layer, show the output shape
-
for layer_name, blob
in
-
print layer_name +
'\t' + str(blob.data.shape)
-
輸出:
data (50, 3, 227, 227) conv1 (50, 96, 55, 55) pool1 (50, 96, 27, 27) norm1 (50, 96, 27, 27) conv2 (50, 256, 27, 27) pool2 (50, 256, 13, 13) norm2 (50, 256, 13, 13) conv3 (50, 384, 13, 13) conv4 (50, 384, 13, 13) conv5 (50, 256, 13, 13) pool5 (50, 256, 6, 6) fc6 (50, 4096) fc7 (50, 4096) fc8 (50, 1000) prob (50, 1000)
這些引數寫在另一個OrderedDict, net.params. 這裡需要索引引數的結果,權重[0],偏置[1]
這些引數典型的格式是:
權重:(output_channels, input_channels, filter_height, filter_width)
偏置:(output_channels,)
-
-
for layer_name, param
in net.params.iteritems():
-
print layer_name +
'\t' + str(param[
0].data.shape), str(param[
1].data.shape)
-
輸出:
conv1 (96, 3, 11, 11) (96,) conv2 (256, 48, 5, 5) (256,) conv3 (384, 256, 3, 3) (384,) conv4 (384, 192, 3, 3) (384,) conv5 (256, 192, 3, 3) (256,) fc6 (4096, 9216) (4096,) fc7 (4096, 4096) (4096,) fc8 (1000, 4096) (1000,)當處理4維資料的時候,定義一個 矩形熱圖顯示函式非常有用:
-
def vis_square(data):
-
"""Take an array of shape (n, height, width) or (n, height, width, 3)
-
and visualize each (height, width) thing in a grid of size approx. sqrt(n) by sqrt(n)"""
-
-
# normalize data for display
-
data = (data - data.min()) / (data.max() - data.min())
-
-
# force the number of filters to be square
-
n = int(np.ceil(np.sqrt(data.shape[
0])))
-
padding = (((
0, n **
2 - data.shape[
0]),
-
(
0,
1), (
0,
1))
# add some space between filters
-
+ ((
0,
0),) * (data.ndim -
3))
# don't pad the last dimension (if there is one)
-
data = np.pad(data, padding, mode=
'constant', constant_values=
1)
# pad with ones (white)
-
-
# tile the filters into an image
-
data = data.reshape((n, n) + data.shape[
1:]).transpose((
0,
2,
1,
3) + tuple(range(
4, data.ndim +
1)))
-
data = data.reshape((n * data.shape[
1], n * data.shape[
3]) + data.shape[
4:])
-
-
plt.imshow(data); plt.axis(
'off')
來看看使用上面的函式來顯示第1個捲尺層過濾器的資料:
-
-
# the parameters are a list of [weights, biases]
-
filters = net.params[
'conv1'][
0].data
-
vis_square(filters.transpose(
0,
2,
3,
1))
-

來看看第1個卷積層的輸出資料(只顯示了前36個):
-
feat = net.blobs[
'conv1'].data[
0, :
36]
-
vis_square(feat)

同樣的道理,想要顯示第5個卷積層相應的資料,第5個pooling層的資料,等都是一樣的。
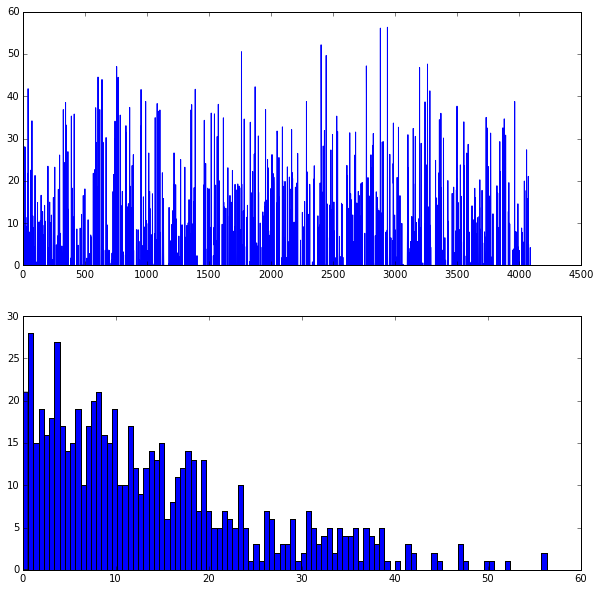
那麼全連線層的資料怎麼顯示呢?
以fc6的輸出為例:
-
feat = net.blobs[
'fc6'].data[
0]
-
plt.subplot(
2,
1,
1)
-
plt.plot(feat.flat)
-
plt.subplot(
2,
1,
2)
-
_ = plt.hist(feat.flat[feat.flat >
0], bins=
100)
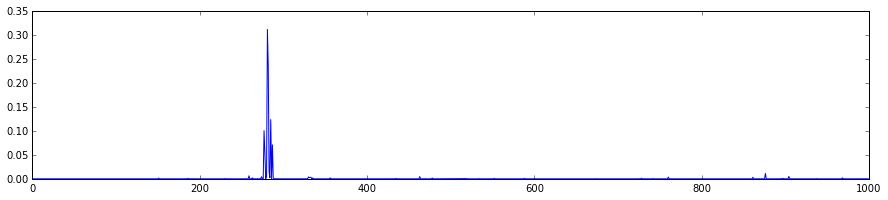
最後希望將所有分類的概率都畫出來:
-
feat = net.blobs[
'prob'].data[
0]
-
plt.figure(figsize=(
15,
3))
-
plt.plot(feat.flat)
[<matplotlib.lines.Line2D at 0x7f09587dfb50>]