
KNN(K近鄰)演算法小結
1.K近鄰演算法的介紹:
K近鄰演算法是一個理論上比較成熟的分類演算法,也是機器學習中的基本演算法。該方法的思路為:如果一個樣本在特徵空間中的K個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一類別,那麼這個樣本也屬於這個類別。用官方的話來說,就是給定一個訓練資料集,對新的輸入例項,在訓練資料集中找到K個最鄰近的資料點,這K個數據點大多屬於某一類,那麼這個例項也屬於這一類。基本的過程為:將新的資料的每個特徵與樣本集中資料對應的特徵進行比較,然後演算法提取出樣本中最相似的分類標籤,一般提取出的樣本K不大於20,找出這K箇中次數最多的分類,即作為這個資料的分類。不足之處就是計算量比較大。
2.演算法的基本步驟:
1.計算已知類別資料集中的點與當前點的距離;
2.按照距離遞增次序進行排序;
3.選取與當前距離最小的K個點;
4.確定前K個點所在類別的出現頻率,
5.返回前K個點所出現頻率最高的類別作為當前點的預測分類;
3.演算法的舉例:
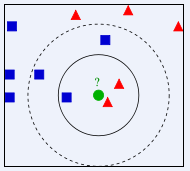
尋找中間綠色點為哪一類:
當 K=3時,綠色點的最近3個鄰居是一個小藍正方形和2個紅小三角形,少數從屬於多數,基於統計的方法,這個綠色待分類點屬於紅色小三角形一類。
當K= 5時,綠色點的最近5個鄰居時兩個小紅三角形和三個小藍正方形。還是少數從屬於多數,這個綠色待分類點屬於小藍正方形。
當K為其他值時,方法依次類推,距離的計算公式一般為歐式距離的計算。
4.案例程式碼顯示
# -*- coding: UTF-8 -*- import numpy as np import operator """ 函式說明:建立資料集 Parameters: 無 Returns: group - 資料集 labels - 分類標籤 Modify: 2017-07-13 """ def createDataSet(): #四組二維特徵 group = np.array([[1,101],[5,89],[108,5],[115,8]]) #四組特徵的標籤 labels = ['喜歡','喜歡','不喜歡','不喜歡'] return group, labels """ 函式說明:kNN演算法,分類器 Parameters: inX - 用於分類的資料(測試集) dataSet - 用於訓練的資料(訓練集) labes - 分類標籤 k - kNN演算法引數,選擇距離最小的k個點 Returns: sortedClassCount[0][0] - 分類結果 Modify: 2017-07-13 """ def classify0(inX, dataSet, labels, k): #numpy函式shape[0]返回dataSet的行數 dataSetSize = dataSet.shape[0] #在列向量方向上重複inX共1次(橫向),行向量方向上重複inX共dataSetSize次(縱向) diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet #二維特徵相減後平方 sqDiffMat = diffMat**2 #sum()所有元素相加,sum(0)列相加,sum(1)行相加 sqDistances = sqDiffMat.sum(axis=1) #開方,計算出距離 distances = sqDistances**0.5 #返回distances中元素從小到大排序後的索引值 sortedDistIndices = distances.argsort() #定一個記錄類別次數的字典 classCount = {} for i in range(k): #取出前k個元素的類別 voteIlabel = labels[sortedDistIndices[i]] #dict.get(key,default=None),字典的get()方法,返回指定鍵的值,如果值不在字典中返回預設值。 #計算類別次數 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #python3中用items()替換python2中的iteritems() #key=operator.itemgetter(1)根據字典的值進行排序 #key=operator.itemgetter(0)根據字典的鍵進行排序 #reverse降序排序字典 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #返回次數最多的類別,即所要分類的類別 return sortedClassCount[0][0] if __name__ == '__main__': #建立資料集 group, labels = createDataSet() #測試集 test = [101,20] #kNN分類 test_class = classify0(test, group, labels, 3) #列印分類結果 print(test_class)
分類器並不一定會得到百分百的結果,可以用檢測資料來檢測分類器的正確率。另外分類器的效能也會受到分類器設定和資料集的影響。錯誤率是常用的評估方法,主要用於分類器在某個資料集上的分類效果,錯誤率的範圍一般在0和1之間,可以將訓練集中的資料,大部分用於分類,小部分用於檢測分類器的錯誤率。測試的資料應該是隨機選擇的。
import numpy as np
import operator
"""
函式說明:kNN演算法,分類器
Parameters:
inX - 用於分類的資料(測試集)
dataSet - 用於訓練的資料(訓練集)
labes - 分類標籤
k - kNN演算法引數,選擇距離最小的k個點
Returns:
sortedClassCount[0][0] - 分類結果
Modify:
2017-03-24
"""
def classify0(inX, dataSet, labels, k):
#numpy函式shape[0]返回dataSet的行數
dataSetSize = dataSet.shape[0]
#在列向量方向上重複inX共1次(橫向),行向量方向上重複inX共dataSetSize次(縱向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二維特徵相減後平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#開方,計算出距離
distances = sqDistances**0.5
#返回distances中元素從小到大排序後的索引值
sortedDistIndices = distances.argsort()
#定一個記錄類別次數的字典
classCount = {}
for i in range(k):
#取出前k個元素的類別
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定鍵的值,如果值不在字典中返回預設值。
#計算類別次數
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替換python2中的iteritems()
#key=operator.itemgetter(1)根據字典的值進行排序
#key=operator.itemgetter(0)根據字典的鍵進行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次數最多的類別,即所要分類的類別
return sortedClassCount[0][0]
"""
函式說明:開啟並解析檔案,對資料進行分類:1代表不喜歡,2代表魅力一般,3代表極具魅力
Parameters:
filename - 檔名
Returns:
returnMat - 特徵矩陣
classLabelVector - 分類Label向量
Modify:
2017-03-24
"""
def file2matrix(filename):
#開啟檔案
fr = open(filename)
#讀取檔案所有內容
arrayOLines = fr.readlines()
#得到檔案行數
numberOfLines = len(arrayOLines)
#返回的NumPy矩陣,解析完成的資料:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3))
#返回的分類標籤向量
classLabelVector = []
#行的索引值
index = 0
for line in arrayOLines:
#s.strip(rm),當rm空時,預設刪除空白符(包括'\n','\r','\t',' ')
line = line.strip()
#使用s.split(str="",num=string,cout(str))將字串根據'\t'分隔符進行切片。
listFromLine = line.split('\t')
#將資料前三列提取出來,存放到returnMat的NumPy矩陣中,也就是特徵矩陣
returnMat[index,:] = listFromLine[0:3]
#根據文字中標記的喜歡的程度進行分類,1代表不喜歡,2代表魅力一般,3代表極具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
"""
函式說明:對資料進行歸一化
Parameters:
dataSet - 特徵矩陣
Returns:
normDataSet - 歸一化後的特徵矩陣
ranges - 資料範圍
minVals - 資料最小值
Modify:
2017-03-24
"""
def autoNorm(dataSet):
#獲得資料的最小值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
#最大值和最小值的範圍
ranges = maxVals - minVals
#shape(dataSet)返回dataSet的矩陣行列數
normDataSet = np.zeros(np.shape(dataSet))
#返回dataSet的行數
m = dataSet.shape[0]
#原始值減去最小值
normDataSet = dataSet - np.tile(minVals, (m, 1))
#除以最大和最小值的差,得到歸一化資料
normDataSet = normDataSet / np.tile(ranges, (m, 1))
#返回歸一化資料結果,資料範圍,最小值
return normDataSet, ranges, minVals
"""
函式說明:分類器測試函式
Parameters:
無
Returns:
normDataSet - 歸一化後的特徵矩陣
ranges - 資料範圍
minVals - 資料最小值
Modify:
2017-03-24
"""
def datingClassTest():
#開啟的檔名
filename = "datingTestSet.txt"
#將返回的特徵矩陣和分類向量分別儲存到datingDataMat和datingLabels中
datingDataMat, datingLabels = file2matrix(filename)
#取所有資料的百分之十
hoRatio = 0.10
#資料歸一化,返回歸一化後的矩陣,資料範圍,資料最小值
normMat, ranges, minVals = autoNorm(datingDataMat)
#獲得normMat的行數
m = normMat.shape[0]
#百分之十的測試資料的個數
numTestVecs = int(m * hoRatio)
#分類錯誤計數
errorCount = 0.0
for i in range(numTestVecs):
#前numTestVecs個數據作為測試集,後m-numTestVecs個數據作為訓練集
classifierResult = classify0(normMat[i,:], normMat[numTestVecs:m,:],
datingLabels[numTestVecs:m], 4)
print("分類結果:%d\t真實類別:%d" % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("錯誤率:%f%%" %(errorCount/float(numTestVecs)*100))
"""
函式說明:main函式
Parameters:
無
Returns:
無
Modify:
2017-03-24
"""
if __name__ == '__main__':
datingClassTest()KNN演算法不僅可以用於分類,還可以用於迴歸。通過找出該樣本的K個最近距離,將這些K個樣本的平均值賦給樣本,就可以得到該樣本的屬性。更有用的方法是將不同距離的鄰居對該樣本產生的影響給予不同的權值,如權值與距離成反比。 該演算法在分類時有個主要的不足是,當樣本不平衡時,如一個類的樣本容量很大,而其他類樣本容量很小時,有可能導致當輸入一個新樣本時,該樣本的K個鄰居中大容量類的樣本佔多數。 該演算法只計算“最近的”鄰居樣本,某一類的樣本數量很大,那麼或者這類樣本並不接近目標樣本,或者這類樣本很靠近目標樣本。無論怎樣,數量並不能影響執行結果。可以採用權值的方法(和該樣本距離小的鄰居權值大)來改進