
運動偵測演算法概論及彙總
運動目標檢測是指在序列影象中檢測出變化區域並將運動目標從背景影象中提取出來。通常情況下,目標分類、跟蹤和行為理解等後處理過程僅僅考慮影象中對應於運動目標的畫素區域,因此運動目標的正確檢測與分割對於後期處理非常重要然而,由於場景的動態變化,如天氣、光照、陰影及雜亂背景干擾等的影響,使得運動目標的檢測與分割變得相當困難。根據攝像頭是否保持靜止,運動檢測分為靜態背景和運運動目標檢測是指在序列影象中檢測出變化區域並將運動目標從背景影象中提取出來。通常情況下,目標分類、跟蹤和行為理解等後處理過程僅僅考慮影象中對應於運動目標的畫素區域,因此運動目標的正確檢測與分割對於後期處理非常重要然而,由於場景的動態變化,如天氣、光照、陰影及雜亂背景干擾等的影響,使得運動目標的檢測與分割變得相當困難。根據攝像頭是否保持靜止,運動檢測分為靜態背景和運動背景兩類。大多數視訊監控系統是攝像頭固定的,因此靜態背景下運動目標檢測演算法受到廣泛關注,常用的方法有幀差法、光流法、背景減除法、
一. 幀間差分法
1. 演算法原理
幀間差分法是將視訊流中相鄰兩幀或相隔幾幀影象的兩幅影象畫素值相減,並對相減後的影象進行閾值化來提取影象中的運動區域。 若相減兩幀影象的幀數分別為第k幀, 第(k+1)幀,其幀影象分別為fk(x,y),fk+1(x,y),差分影象二值化閾值為T,差分影象用D(x, y)表示,則幀間差分法的公式如下:
D(x,y)={1,|fk+1(x,y)−fk(x,y)|>T0,others
幀間差分法的優缺點如下:
- 優點:演算法簡單,不易受環境光線影響
- 缺點:
- 不能用於運動的攝像頭中;
- 無法識別靜止或運動速度很慢的目標;
- 運動目標表面有大面積灰度值相似區域的情況下,在做差分時影象會出現孔洞;
2. 演算法原始碼
筆者已經將把原始碼上傳到GitHub網站上,地址如下:
https://github.com/upcAutoLang/BackgroundSplit-OpenCV/tree/master/src/FramesDifference
二幀差值(相鄰幀間差分法直接對相鄰的兩幀影象做差分運算,並取差分運算的絕對值構成移動物體,優點是運算快速,實時性高,缺點是無法應對光照的突變,物體間一般具有空洞)
opencv、c++實現:
#include "core/core.hpp"
#include "highgui/highgui.hpp"
#include "imgproc/imgproc.hpp"
using namespace cv;
int main(int argc,char *argv[])
{
VideoCapture videoCap(argv[1]);
if(!videoCap.isOpened())
{
return -1;
}
double videoFPS=videoCap.get(CV_CAP_PROP_FPS); //獲取幀率
double videoPause=1000/videoFPS;
Mat framePre; //上一幀
Mat frameNow; //當前幀
Mat frameDet; //運動物體
videoCap>>framePre;
cvtColor(framePre,framePre,CV_RGB2GRAY);
while(true)
{
videoCap>>frameNow;
if(frameNow.empty()||waitKey(2500)==27)
{
break;
}
cvtColor(frameNow,frameNow,CV_RGB2GRAY);
absdiff(frameNow,framePre,frameDet);
framePre=frameNow;
imshow("Video",frameNow);
imshow("Detection",frameDet);
}
return 0;
}
呼叫了Opencv自帶的視訊檔案“768x576.avi”,視訊檔案位置:“opencv\sources\samples\gpu”,下圖是視訊第100幀時影象:
 |
 |
右圖是相鄰兩幀差法檢測到的物體,檢測效果沒有經過膨脹或腐蝕等處理。可以看到物體的輪廓是“雙邊”的,並且物體的移動速度越快,雙邊輪廓現象越粗越明顯(這是不是給監控中速度檢測提供了一個思路~~),另一個就是物體具有較大的空洞。
三幀差法是在相鄰幀差法基礎上改進的演算法,在一定程度上優化了運動物體雙邊,粗輪廓的現象,相比之下,三幀差法比相鄰幀差法更適用於物體移動速度較快的情況,比如道路上車輛的智慧監控。
三幀差法基本實現步驟:1. 前兩幀影象做灰度差;2. 當前幀影象與前一幀影象做灰度差;3. 1和2的結果影象按位做“與”操作。
opencv、C++實現:
#include "core/core.hpp"
#include "highgui/highgui.hpp"
#include "imgproc/imgproc.hpp"
using namespace cv;
int main(int argc,char *argv[])
{
VideoCapture videoCap(argv[1]);
if(!videoCap.isOpened())
{
return -1;
}
double videoFPS=videoCap.get(CV_CAP_PROP_FPS); //獲取幀率
double videoPause=1000/videoFPS;
Mat framePrePre; //上上一幀
Mat framePre; //上一幀
Mat frameNow; //當前幀
Mat frameDet; //運動物體
videoCap>>framePrePre;
videoCap>>framePre;
cvtColor(framePrePre,framePrePre,CV_RGB2GRAY);
cvtColor(framePre,framePre,CV_RGB2GRAY);
int save=0;
while(true)
{
videoCap>>frameNow;
if(frameNow.empty()||waitKey(videoPause)==27)
{
break;
}
cvtColor(frameNow,frameNow,CV_RGB2GRAY);
Mat Det1;
Mat Det2;
absdiff(framePrePre,framePre,Det1); //幀差1
absdiff(framePre,frameNow,Det2); //幀差2
threshold(Det1,Det1,0,255,CV_THRESH_OTSU); //自適應閾值化
threshold(Det2,Det2,0,255,CV_THRESH_OTSU);
Mat element=getStructuringElement(0,Size(3,3)); //膨脹核
dilate(Det1,Det1,element); //膨脹
dilate(Det2,Det2,element);
bitwise_and(Det1,Det2,frameDet);
framePrePre=framePre;
framePre=frameNow;
imshow("Video",frameNow);
imshow("Detection",frameDet);
}
return 0;
}
同樣是“768x576.avi”視訊檔案,並且也儲存了第100幀的原始影象和運動物體檢測影象:
 |
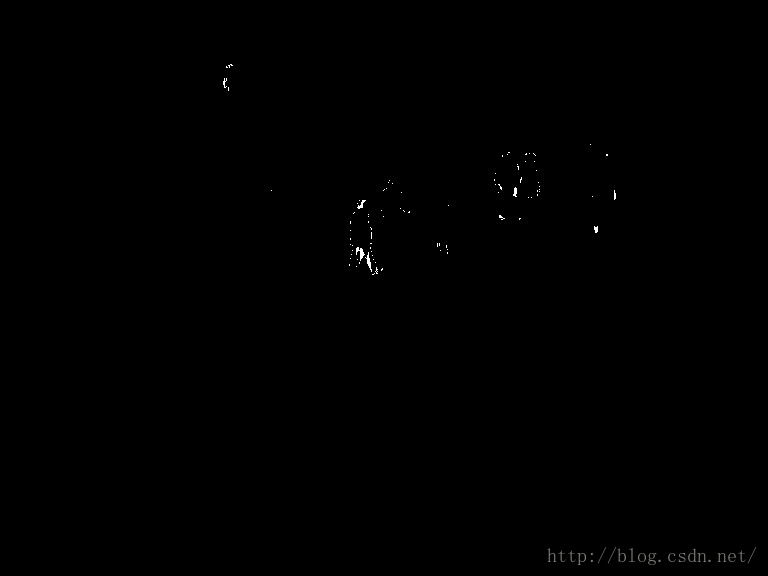 |
 |
原始幀影象;未經形態學處理的原始的三幀差法檢測到的運動物體,未經任何形態學處理的原始的三幀差法檢測到的物體的雙邊輪廓現象有所改善,但同時也有丟失輪廓的現象;最後兩個幀差影象按位與操作之前做了一下膨脹處理的效果。
相比相鄰兩幀差法,原始的三幀差法對物體的雙邊粗輪廓和“鬼影”現象有所改善,比較適合對運動速度較快物體的檢測,但是仍然會有空洞出現,並且物體移動速度較慢時容易丟失輪廓。當然三幀差法做了兩次的差分運算,給了三幀差法更多可操作和優化的空間,為更優秀的檢測效果提供了可能。
二. 背景差分法
參考網址:
《背景差分法》
《幀間差分法和背景建模法》
1. 演算法原理
背景差分法是一種對靜止場景進行運動分割的通用方法,它將當前獲取的影象幀與背景影象做差分運算,得到目標運動區域的灰度圖,對灰度圖進行閾值化提取運動區域,而且為避免環境光照變化影響,背景影象根據當前獲取影象幀進行更新。
根據前景檢測,背景維持和後處理方法,存在幾種不同的背景差方法。若設It,BtIt,Bt分別為當前幀與背景幀影象,T為前景灰度閾值,則其中一種方法流程如下:
- 取前幾幀影象的平均值,將其作為初始的背景影象BtBt;
- 當前幀影象與背景影象作灰度減運算,並取絕對值;公式即為|It(x,y)−Bt(x,y)|;
- 對當前幀的畫素(x,y),若有|It(x,y)−Bt(x,y)|>T,則該畫素點為前景點;
- (可選)對前景畫素圖進行形態學操作(腐蝕、膨脹、開閉操作等)
- 用當前幀影象對背景影象進行更新;
背景差分法的優缺點如下:
- 優點:
- 演算法比較簡單;
- 一定程度上克服了環境光線的影響;
- 缺點:
- 不能用於運動的攝像頭;
- 對背景影象實時更新困難;
高斯背景模型 在運動檢測中的應用
原理 : 高斯模型就是用高斯概率密度函式(正態分佈曲線)精確地量化事物,將一個事物分解為若干的基於高斯概率密度函式(正態分佈曲線)形成的模型。
對影象背景建立高斯模型的原理及過程:影象灰度直方圖反映的是影象中某個灰度值出現的頻次,也可以認為是影象灰度概率密度的估計。如果影象所包含的目標區域和背景區域相比,區域面積較大且區域在灰度上有一定的差異,那麼該影象的灰度直方圖呈現雙峰-谷形狀,其中一個峰對應於目標的重心灰度,另一個峰對應於背景的中心灰度。對於複雜的影象,尤其是醫學影象,一般是多峰的。通過將直方圖的多峰特性看作是多個高斯分佈的疊加,可以解決影象的分割問題。
在智慧監控系統中,對於運動目標的檢測是中心內容,而在運動目標檢測提取中,背景目標對於目標的識別和跟蹤至關重要。而建模正是背景目標提取的一個重要環節。
我們首先要提起背景和前景的概念,前景是指在假設背景為靜止的情況下,任何有意義的運動物體即為前景。建模的基本思想是從當前幀中提取前景,其目的是使背景更接近當前視訊幀的背景。即利用當前幀和視訊序列中的當前背景幀進行加權平均來更新背景,但是由於光照突變以及其他外界環境的影響,一般的建模後的背景並非十分乾淨清晰,而高斯混合模型是是建模最為成功的方法之一。
混合高斯模型使用K(基本為3到5個)個高斯模型來表徵影象中各個畫素點的特徵,在新一幀影象獲得後更新混合高斯模型, 用當前影象中的每個畫素點與混合高斯模型匹配,如果成功則判定該點為背景點, 否則為前景點。 通觀整個高斯模型,主要是有方差和均值兩個引數決定,對均值和方差的學習,採取不同的學習機制,將直接影響到模型的穩定性、精確性和收斂性 。由於我們是對運動目標的背景提取建模,因此需要對高斯模型中方差和均值兩個引數實時更新。為提高模型的學習能力,改進方法對均值和方差的更新採用不同的學習率;為提高在繁忙的場景下,大而慢的運動目標的檢測效果,引入權值均值的概念,建立背景影象並實時更新,然後結合權值、權值均值和背景影象對畫素點進行前景和背景的分類。
到這裡為止,混合高斯模型的建模基本完成,我在歸納一下其中的流程,首先初始化預先定義的幾個高斯模型,對高斯模型中的引數進行初始化,並求出之後將要用到的引數。其次,對於每一幀中的每一個畫素進行處理,看其是否匹配某個模型,若匹配,則將其歸入該模型中,並對該模型根據新的畫素值進行更新,若不匹配,則以該畫素建立一個高斯模型,初始化引數,代理原有模型中最不可能的模型。最後選擇前面幾個最有可能的模型作為背景模型,為背景目標提取做鋪墊。
方法: 目前,運動物體檢測的問題主要分為兩類,攝像機固定和攝像機運動。對於攝像機運動的運動物體檢測問題,比較著名的解決方案是光流法,通過求解偏微分方程求的影象序列的光流場,從而預測攝像機的運動狀態。對於攝像機固定的情形,當然也可以用光流法,但是由於光流法的複雜性,往往難以實時的計算,所以我採用高斯背景模型。因為,在攝像機固定的情況下,背景的變化是緩慢的,而且大都是光照,風等等的影響,通過對背景建模,對一幅給定影象分離前景和背景,一般來說,前景就是運動物體,從而達到運動物體檢測的目的。
單分佈高斯背景模型
單分佈高斯背景模型認為,對一個背景影象,特定畫素亮度的分佈滿足高斯分佈,即對背景影象B, (x,y)點的亮度滿足:
IB (x,y) ~ N(u,d)
這樣我們的背景模型的每個象素屬性包括兩個引數:平均值u 和 方差d。
對於一幅給定的影象G,如果 Exp(-(IG (x,y)-u(x,y))^2/(2*d^2)) > T,認為(x,y)是背景點,反之是前景點。
同時,隨著時間的變化,背景影象也會發生緩慢的變化,這時我們要不斷更新每個象素點的引數
u(t+1,x,y) = a*u(t,x,y) + (1-a)*I(x,y)
這裡,a稱為更新引數,表示背景變化的速度,一般情況下,我們不更新d(實驗中發現更不更新 d,效果變化不大)。
opencv
int main( int argc, char** argv )
{
VideoCapture cam("bike.avi");// 0開啟預設的攝像頭
if(!cam.isOpened())
return -1;
namedWindow("mask",CV_WINDOW_AUTOSIZE);
namedWindow("frame",CV_WINDOW_AUTOSIZE);
Mat frame,mask,threImage,output;
int delay = 1000/cam.get(CV_CAP_PROP_FPS);
BackgroundSubtractorMOG bgSubtractor(10,10,0.5,false);
//構造混合高斯模型 引數1:使用歷史幀的數量 2:混合高斯個數,3:背景比例 4::噪聲權重
while (true)
{
cam>>frame;
imshow("frame",frame);
bgSubtractor(frame,mask,0.001);
imshow("mask",mask);
waitKey(delay);
}
return 0;
}

累積權重構建背景模型
運動物體檢測與跟蹤中的幀差分法,除了相鄰幀差分法和三幀差分法外,還有一種差分方法,可以通過建立不含前景的背景模型,用當前幀和背景模型做差,差值就可以體現運動物體大概的位置和大小資訊。相比相鄰幀差分法和三幀差分法,背景模型做差法可以較為完整的體現運動物體的整體輪廓,運動物體的雙重輪廓、“鬼影”、空洞現象改善明顯,下文的對比效果可以看到這一點。
但背景模型的選取和建立的要求條件也更為苛刻:
1. 背景模型中不能包含前景物體,如果包含前景物體,則在之後檢測到的運動物體結果中,會一直保留有前景運動物體初始的輪廓。
例如下邊這個例子,選取了第一幀作為背景模型,不幸的是,第一幀中含有運動物體,用紅色框標示出:
 |
 |
正如前邊所說的,在之後檢測到的運動物體結果中,3個前景運動物體初始的輪廓一直存在,即使運動物體早已經不在初始的位置,用紅色框標示出。
若使用完全不包含前景物體的背景影象作為背景模型,上述情況就不會出現了,檢測效果也比較好。比如使用下邊這個影象作為背景模型:
 |
 |
由於這個視訊沒有完全不包含前景物體的背景影象,我的方法是求所有視訊幀序列和的平均值作為背景模型,在一定程度上可以代表不含前景的背景圖,部分位置處移動物體停留的事件比較久,所以有一些黑影出現,如影象中部區域。檢測效果中不再有之前的3個“偽影像”,並且可以看到,相比相鄰幀差分法和三幀差分法,背景模型做差法可以較為完整的體現運動物體的整體輪廓,運動物體的雙重輪廓、“鬼影”、空洞現象改善明顯。
2. 背景模型對環境的變化非常敏感,比如光照的變化、背景模型建立之後監控中加入的靜止的物體、或背景模型中原本的物體位置被挪動等等,這些因素都會造成靜止的物體被當做運動物體檢測出來。造成誤檢,
還以上一個視訊為例,當背景模型中原本靜止的物體位置被挪動:
 |
建立背景模型時視訊中彩帶的位置在下圖用藍色線段標示出,之後由於一些原因綵帶的位置發生了改變,用紅色線段標示,位置改變後,即使綵帶一直保持靜止,在檢測結果中仍然會錯誤的檢測出靜止的綵帶。
現實情況中,想要消除以上兩點影響,一次性建立一個理想的背景模型,幾乎是不可能的。基於此,我們可以建立一個動態的背景模型,這個動態模型實現以下兩個功能:
1. 如果初始建立的背景模型中包含有前景物體,動態模型應該能夠快速將前景物體的影響降低或消除掉;
2. 對於背景模型中靜止的物體位置改變或者新加入視訊畫面中靜止的物體,動態模型應該能夠快速覺察到這種變化, 並把這種改變納入到下一輪的背景模型構建中。
基於這兩個基本的要求,構建動態背景模型的步驟如下:
1. 以初始第一幀作為第一個背景模型
2. 檢測第二幀中運動物體,得到前景影象
3. 把第二幀影象摳除檢測到的前景物體後,以一定比例係數累加到上一輪構建的背景模型中
4. 更新背景模型,在隨後幀上,重複1,2,3
Opencv中,accumulateWeighted方法可以實現以上構建動態模型的要求。
方法原型:
void accumulateWeighted( InputArray src, InputOutputArray dst,
double alpha, InputArray mask=noArray() );
第一個引數:src,新加入的構建背景模型的影象矩陣;
第二個引數:dst,累計新元素src後生成的新的背景模型;
第三個引數:alpha,新加入原型src的係數,公式表述為:
dst = dst*(1-alpha) + src*alpha;
即alpha越大,當前新元素對構建動態模型的影響越大如下,當alpha取值為0.9時,背景模型為,此時新加入背景模型的新元素佔比較大,對新的背景模型的影響也大,從上圖可以看到,除有少許拖影外 ,基本跟上一幀影象特徵一致;當alpha取值為0.2時,背景模型為,此時,新加入背景模型的元素佔比較小,意味著之前加入的元素比重相應較大,累計的背景模型有很 重的“鬼影”,每一個虛影代表了最近新加入背景模型的一個元素。
 |
 |
第四個引數:mask,英文釋義“面具”,顧名思義,指在背景模型中需要減去的,不予考慮的部分,可以使用在當前背景模型下檢出的前景物體作為mask,進一步減少對背景模型的干擾,可以為空。
累積權重構建背景模型程式碼實現:
#include "core/core.hpp"
#include "highgui/highgui.hpp"
#include "imgproc/imgproc.hpp"
#include "iostream"
using namespace std;
using namespace cv;
int main(int argc,char *argv[])
{
VideoCapture videoCap(argv[1]);
if(!videoCap.isOpened())
{
return -1;
}
Mat image;
Mat imageBackground; //動態背景模型
Mat imageFront; //前景
double videoFPS=videoCap.get(CV_CAP_PROP_FPS); //獲取幀率
double videoPause=1000/videoFPS;
videoCap>>imageBackground; //第一幀作為初始背景模型
cvtColor(imageBackground,imageBackground,CV_RGB2GRAY);
Mat element=getStructuringElement(0,Size(3,3)); //腐蝕核
while(true)
{
videoCap>>image;
if(image.empty()||waitKey(videoPause)==27) //視訊播放完成,或Esc鍵退出
{
break;
}
Mat image1;
cvtColor(image,image1,CV_RGB2GRAY);
absdiff(image1,imageBackground,imageFront);
imageBackground.convertTo(imageBackground,CV_32FC1); //擴充套件至32位做運算
accumulateWeighted(image1,imageBackground,0.6,imageFront);
imageBackground.convertTo(imageBackground,CV_8UC1); //轉換回8位
threshold(imageFront,imageFront,0,255,CV_THRESH_OTSU); //閾值分割
morphologyEx(imageFront,imageFront,CV_MOP_OPEN,element); //消除孤立的點
//膨脹操作,消除孔洞
dilate(imageFront,imageFront,element);
dilate(imageFront,imageFront,element);
dilate(imageFront,imageFront,element);
dilate(imageFront,imageFront,element);
dilate(imageFront,imageFront,element);
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
findContours(imageFront,contours,hierarchy,RETR_EXTERNAL,CHAIN_APPROX_NONE,Point());
for(int i=0;i<contours.size();i++)
{
//繪製輪廓的最小外結矩形
RotatedRect rect=minAreaRect(contours[i]);
Point2f P[4];
rect.points(P);
for(int j=0;j<=3;j++)
{
line(image,P[j],P[(j+1)%4],Scalar(0,0,255),2);
}
}
imshow("Video",image);
imshow("Detection",imageFront);
imshow("背景模型",imageBackground);
}
return 0;
}
測試效果:
 |
 |
 |
2. 演算法原始碼
筆者已經將把原始碼上傳到GitHub網站上,地址如下:
https://github.com/upcAutoLang/BackgroundSplit-OpenCV/tree/master/src/GaussBGDifference
三. ViBe背景提取演算法
ViBe - a powerful technique for background detection and subtraction in video sequences
——摘自ViBe演算法官網
ViBe是一種畫素級視訊背景建模或前景檢測的演算法,效果優於所熟知的幾種演算法,對硬體記憶體佔用也少。該演算法主要不同之處是背景模型的更新策略,隨機選擇需要替換的畫素的樣本,隨機選擇鄰域畫素進行更新。在無法確定畫素變化的模型時,隨機的更新策略,在一定程度上可以模擬畫素變化的不確定性。
參考地址:
《ViBe演算法原理和程式碼解析 》
《背景建模–Vibe 演算法優缺點分析》
《第一次總結報告——Vibe 》
《運動檢測(前景檢測)之(一)ViBe 》
《VIBE改進演算法》
參考論文:
《O. Barnich and M. Van Droogenbroeck. ViBe: a powerful random technique to estimate the background in video sequences.》
《O. Barnich and M. Van Droogenbroeck. ViBe: A universal background subtraction algorithm for video sequences.》
演算法官網:
http://www.telecom.ulg.ac.be/research/vibe/
1. 一般背景提取演算法存在的問題
前文提到的幀間差分法、背景差分法中存在若干問題如下:
- 對於環境變化的適應並不友好(如光照的變化造成色度的變化);
- 相機抖動導致畫面抖動
- 物體檢測中常出現的Ghost區域;
其中值得一提的是Ghost區域:Ghost區域常常出現於幀間差分法,當一個原本靜止的物體開始運動時,幀間差分法檢測時,可能會將原本該物體覆蓋區域錯誤的檢測為運動的,這塊被錯誤檢測到的區域被稱為Ghost。同樣的,原本正在運動的物體變成靜止物體時,也會出現Ghost區域。
例如下圖,原影象中只有三個正在運動的人,但由於幀間差分法取得的背景圖中包含這三個運動的人的某一幀運動狀態,後面的一系列幀序列與背景圖相減,都會存在背景圖中三個人所在的位置,這時候取得的前景會多出三個被檢測區域,即Ghost區域。 
Ghost區域在檢測中,一定要儘快消除。
2. ViBe演算法原理
ViBe比較特殊的地方它的思想:它為所有畫素點儲存了一個樣本集,樣本集裡面儲存的取樣值是該畫素點過去的畫素值與其鄰居點的畫素值。後面每一幀的新畫素值和樣本集裡的樣本歷史值進行比較,判斷是否屬於背景點。
下面從幾點講解ViBe演算法:
(1) 背景、前景模型
模型中,背景就是靜止的,或者移動非常緩慢的物體;前景就是相對於背景的物體,即正在移動的物體。所以背景提取演算法也可以看成是一個分類問題,遍歷畫素點的過程中,來確定一個畫素點是屬於前景點,還是屬於背景點。
在ViBe模型中,背景模型為每個畫素點儲存了樣本集,樣本集大小一般為20個點。對於採入的新一幀影象,該幀的某個畫素點與該畫素點的樣本集內取樣值比較接近時,就可以判斷其是一個背景點。
用公式表示,我們可以認為:
- v(x,y):畫素點(x, y)處的當前畫素值;
- M(x,y)={v1(x,y),v2(x,y),...vN(x,y)}:畫素點(x, y)的背景樣本集(樣本集大小為N);
- R:上下取值範圍;
將v(x,y)與M(x,y)中所有樣本值作差,所有差值中,在±R範圍內的個數為Nb,若Nb大於一個給定的閾值min,就說明當前畫素值與該點歷史樣本中的多個值相似,那麼就認為(x,y)點屬於背景點。
(2) 背景模型初始化
初始化是建立背景模型的過程,一般的檢測演算法需要一定長度的視訊序列學習完成,影響了檢測的實時性,而且當視訊畫面突然變化時,重新學習背景模型需要較長時間。
ViBe演算法建立背景模型只需要一幀,即使用單幀視訊序列初始化背景模型。將視訊的第一幀作為背景模型的同時,演算法也將該幀中每一個畫素點周圍隨機取多個畫素點,填充該畫素點的樣本集,這樣樣本集中就包含了畫素點的時空分佈資訊。
用公式表示,我們可以認為:
- M0(x,y):初始背景模型中的畫素點(x, y);
- NG:鄰居點;
- v0(x,y):初始原影象中畫素點(x, y)的畫素值;
於是有:
M0(x)={v0(y|y∈NG(x))},t=0
這種背景模型初始化的優缺點如下:
- 優點:
- 對於噪聲的反應比較靈敏;
- 計算量小速度快;
- 不僅減少了背景模型建立的過程,還可以處理背景突然變化的情況,當檢測到背景突然變化明顯時,只需要捨棄原始的模型,重新利用變化後的首幀影象建立背景模型。
- 缺點:
- 用於作平均的幾幀初始影象中可能採用了運動物體的畫素,這種條件下初始化樣本集,容易引入拖影(Ghost)區域;
初始背景模型建立完畢後,就可以進行前景的檢測和背景模型的更新了。
(3) 前景檢測
此時已經建立起了背景模型,便可以已經建立好的背景模型進行前景的檢測。
遍歷新一幀影象的所有畫素點。用公式表示,則有:
- v(x,y):新一幀的畫素點(x, y);
- M(x,y)={v1(x,y),v2(x,y),...vN(x,y)}:畫素點(x, y)的背景樣本集(樣本集大小為N);
- D(x,y)={d1(x,y),d2(x,y),...dN(x,y)}:畫素點(x, y)當前值與樣本集裡所有樣本值之差(樣本集大小為N)
- 其中,di=v(x,y)−vi(x,y);
- R:判斷畫素點與歷史樣本值是否相近的閾值;
- T:判斷前景點的閾值;
- 統計當前畫素點的值與歷史樣本值之差大於R的個數,若個數大於T,則判斷該點為前景點;
檢測前景的流程如下:
- 將某畫素點的當前畫素值v(x,y),與該畫素點的樣本集M(x,y)作差值,即得到D(x,y)。
- 遍歷D(x,y)中的元素di(x,y),比較它與閾值R的大小;並計滿足di(x,y)>R的個數為Nf;
- 若有Nf>T,則該點為前景點;
檢測過程的主要三個引數是:樣本集數目N,閾值R,與閾值T。一般設定N = 20, R = 20, T = 2;
(4) 背景模型更新策略
即使已經建立起了背景模型,也應該對背景模型進行不斷的更新,這樣才能使得背景模型能夠適應背景的不斷變化(如光照變化,背景物體變更等)。
A. 普通更新策略
對於其他的背景提取演算法,背景模型有兩種不同的更新策略:
- 保守更新策略:前景點永遠不會用來填充模型
- 這樣會引起死鎖,產生Ghost區域。比如初始化的時候如果一塊靜止的區域被錯誤的檢測為運動的,那麼在這種策略下它永遠會被當做運動的物體來對待;
- Blind策略:對死鎖不敏感,前景和背景都可以用來更新背景模型;
- 這樣的缺點在於,緩慢移動的物體會融入到背景中,無法檢測出來;
B. ViBe演算法更新策略
ViBe演算法中,使用的更新策略是:保守更新策略 + 前景點計數法 + 隨機子取樣。
- 前景點計數法:對畫素點進行統計,如果某個畫素點連續N次被檢測為前景,則將其更新為背景點;
- 隨機子取樣:在每一個新的視訊幀中都去更新背景模型中的每一個畫素點的樣本值是沒有必要的,當一個畫素點被分類為背景點時,它有1/φ的概率去更新背景模型。
這就決定了ViBe演算法的更新策略的其他屬性:
- 無記憶更新策略:每次確定需要更新畫素點的背景模型時,以新的畫素值隨機取代該畫素點樣本集的一個樣本值;
- 時間取樣更新策略:並非每處理一幀資料,都需要更新處理,而是按一定的更新率更新背景模型;
- 當一個畫素點被判定為背景時,它有1/φ的概率更新背景模型;
- φ是時間取樣因子,一般取值為16;
- 空間鄰域更新策略:針對需要更新畫素點,在該畫素點的鄰域中隨機選擇一個畫素點,以新選擇的畫素點更新被選中的背景模型;
C. ViBe演算法具體更新的方法:
- 每個背景點都有1/φ的概率更新該畫素點的模型樣本值;
- 有1/φ的概率去更新該畫素點鄰居點的模型樣本值;
- 前景點計數達到臨界值時,將其變為背景,並有1/ φ的概率去更新自己的模型樣本值。
更新鄰居的樣本值利用了畫素值的空間傳播特性,背景模型逐漸向外擴散,這也有利於Ghost區域的更快的識別。
在選擇要替換的樣本集中的樣本值時,我們是隨機選取一個樣本值進行更新。這樣就可以保證,樣本值的平滑的生命週期的原因是由於是隨機的更新,這種情況下一個樣本值在時刻t不被更新的概率是(N - 1) / N。假設時間是連續的,那麼在極小時間dt過去後,樣本值仍然保留的概率是:
P(t,t+dt)=(N−1N)(t+dt)−t
也可以寫作:
P(t,t+dt)=e−ln(NN−1)dt
上面的公式表明,樣本值在模型中是否被替換,與時間t無關,即更新策略是合適的。
3. ViBe演算法優缺點
(1) 優點
Vibe背景建模為運動目標檢測研究領域開拓了新思路,是一種新穎、快速及有效的運動目標檢測演算法。優點主要有兩點:
- 思想簡單,易於實現:
- 初始化背景影象時,Vibe演算法通常隨機選取鄰域20個樣本,作為每個畫素點建立一個基於樣本的背景模型,具有初始化速度快、記憶體消耗少和佔用資源少等優點;
- 隨後,利用一個二次抽樣因子φ,使有限的樣本基數能近似表示無限的時間視窗,即在較少樣本前提下,保證演算法的準確性;
- 最後,並採用一種鄰域傳播機制保證演算法的空間一致性。
- 樣本衰減最優:
- 有人通過增加樣本基數(上至200個)來處理複雜場景,也有人結合兩個子模型分別處理快速更新和緩慢更新的情況。其實,選取被替換樣本更新背景模型,實質上是樣本壽命問題。
- 傳統方式採用先進先出的替換策略,而Vibe背景模型中每個樣本被選中為替換樣本的概率是相等的,與樣本存在時間的長短無關,這種策略保證背景模型中的樣本壽命呈指數衰減,模型更新達到最佳狀態。
- 運算效率高:
- Vibe背景模型是基於少量樣本的背景模型;
- Vibe演算法優化了背景模型中的相似度匹配演算法;
關於運算效率的比較,《背景建模–Vibe 演算法優缺點分析》中做了實驗:為了得到最佳樣本數量N值,分別選取N為5、15、20、25進行了實驗對比:結果如圖所示: 
實驗結果表明,N取20、25時,檢測結果理想;考慮計算負載,N取20最優。與混合高斯的3-5個高斯模型的計算匹配比較,基於20個樣本的背景模型計算具有計算開銷低、檢測速度快等優點。
Vibe的背景模型相似度匹配函式只與判斷畫素點與歷史樣本值是否相近的閾值R,以及判斷前景點的閾值T有關(具體見本文三.2.(3))。背景模型中的樣本與待分類畫素的歐式距離小於R的個數超過T時,更新背景模型;而找到T個匹配樣本時,便立即判斷該畫素為背景畫素點,並停止計算,這樣提高了運算效率。
(2) 缺點
ViBe演算法自身也存在著侷限性。主要有靜止目標、陰影前景和運動目標不完整等問題。
A. 靜止目標
如下圖所示:

圖(a)紅框中的人在等地鐵,從圖(a)到圖(c)經過498幀,長時間駐留未運動,該人物運動目標逐漸被背景吸收。而在本視訊中,將在450幀以上都沒有明顯位移的運動目標區域定義成為靜止目標區域。
這樣可以總結產生靜止目標問題的原因有兩個:
- 運動目標從運動到靜止;
- 運動目標運動速度太過緩慢:當ViBe背景模型更新速度過快時,會將靜止或緩慢運動目標吸收成為背景的一部分;
B. 陰影前景
如下圖所示: 
圖(b)和圖(d)分別是用Vibe演算法對人體運動目標(a)和車體運動目標(c)的檢測結果。由於光線被人體或車體運動目標所遮擋,投射陰影區的背景被誤檢為運動目標前景。陰影的存在導致檢測出來的運動目標形狀不準確,影響後續目標分類、跟蹤、識別和分析等其他智慧視訊處理模組。
產生陰影前景問題的根源是:光線被運動目標前景遮擋,投射陰影區的顏色比背景的顏色暗,即陰影和背景顏色值的距離相差較大,背景差分後被誤檢為運動目標前景。
C. 運動目標不完整問題
如下圖所示:

- 圖(a)中的人內部出現空洞;
- 圖(b)中的人中間出現斷層;
- 圖(c)中的人上半身出現邊緣殘軀;
- 圖(d)車體的擋風玻璃出現空洞;
總結圖中的結果,可以將運動目標不完整現象大致分為三類:
- 運動目標內部有大量空洞(圖a);
- 運動目標邊緣殘缺,呈現C字形凹陷(圖d);
- 運動目標中間有斷層(圖b);
產生運動目標不完整問題的根源主要有兩點:
- ViBe演算法自身存在的缺陷;
- 基於統計學原理的Vibe樣本模型受限於模型的樣本個數,當樣本趨於無窮大時才能準確描述場景,這在實際應用中是不可能實現的;
- 場景或運動目標的複雜性和多變性;
- 瞬時的光線突變,背景模型來不及更新;
- 前景與背景顏色相近,將前景誤判為背景;
- 噪聲干擾,出現孤立噪聲點和連通噪聲區域;
4. ViBe演算法原始碼
筆者已經將把原始碼上傳到GitHub網站上,地址如下:
https://github.com/upcAutoLang/BackgroundSplit-OpenCV/tree/master/src/ViBe
5. ViBe的改進演算法ViBe+
筆者對ViBe+進行了學習研究,部落格地址如下:
《論文翻譯:ViBe+演算法(ViBe演算法的改進版本)》
筆者已經將把原始碼上傳到GitHub網站上,地址如下:
https://github.com/upcAutoLang/BackgroundSplit-OpenCV/tree/master/src/ViBe%2B
相關參考地址:
《ViBe演算法原理和程式碼解析 》
《VIBE改進演算法》
參考論文:
《M. Van Droogenbroeck and O. Paquot. Background Subtraction: Experiments and Improvements for ViBe.》