
[JDK1.7]LinkedHashMap原始碼淺析
引言
HashMap 是一個無序的 Map,因為每次根據 key 的 hashcode 對映到 Entry 陣列上,所以遍歷出來的順序並不是寫入的順序。LinkedHashMap 的底層是繼承於 HashMap 實現的,由一個雙向連結串列所構成;
一、初識LinkedHashMap
HashMap是一種非常常見、非常有用的集合,但在多執行緒情況下使用不當會有執行緒安全問題。
大多數情況下,只要不涉及執行緒安全問題,Map基本都可以使用HashMap,不過HashMap有一個問題,就是迭代HashMap的順序並不是HashMap放置的順序,也就是無序。HashMap的這一缺點往往會帶來困擾,因為有些場景,我們期待一個有序的Map。
這個時候,LinkedHashMap就閃亮登場了,它雖然增加了時間和空間上的開銷,但是通過維護一個運行於所有條目的雙向連結串列,LinkedHashMap保證了元素迭代的順序。該迭代順序可以是插入順序(預設)或者是訪問順序。
二、四個關注點在LinkedHashMap上的答案
| 關 注 點 | 結 論 |
|---|---|
| LinkedHashMap是否允許空 | Key和Value都允許空 |
| LinkedHashMap是否允許重複資料 | Key重複會覆蓋、Value允許重複 |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否執行緒安全 | 非執行緒安全 |
三、LinkedHashMap基本結構
關於LinkedHashMap,先提兩點:
1、LinkedHashMap可以認為是HashMap+LinkedList,即它既使用HashMap操作資料結構,又使用LinkedList維護插入元素的先後順序。
2、LinkedHashMap的基本實現思想就是----多型。可以說,理解多型,再去理解LinkedHashMap原理會事半功倍;反之也是,對於LinkedHashMap原理的學習,也可以促進和加深對於多型的理解。
LinkedHashMap的定義:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
...
}
看到,LinkedHashMap是HashMap的子類,自然LinkedHashMap也就繼承了HashMap中所有非private的方法。再看一下LinkedHashMap中本身的方法:
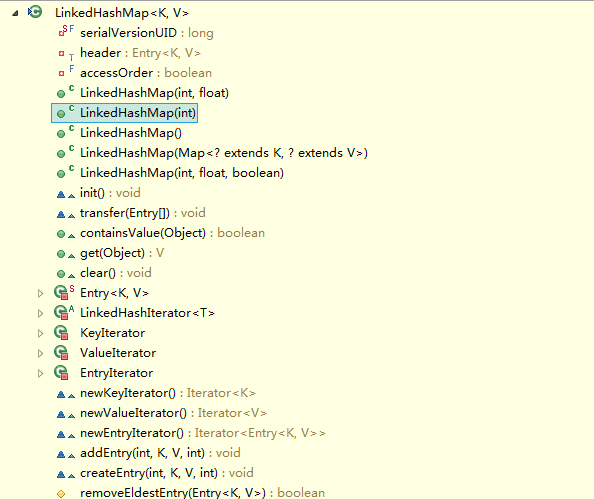
看到LinkedHashMap中並沒有什麼操作資料結構的方法,也就是說LinkedHashMap操作資料結構(比如put一個數據),和HashMap操作資料的方法完全一樣,無非就是細節上有一些的不同罷了。
LinkedHashMap只定義了兩個屬性:
/**
* The head of the doubly linked list.
* 雙向連結串列的頭節點
*/
private transient Entry<K,V> header;
/**
* The iteration ordering method for this linked hash map: true
* for access-order, false for insertion-order.
* true表示最近最少使用次序,false表示插入順序
*/
private final boolean accessOrder;
LinkedHashMap一共提供了五個構造方法:
// 構造方法1,構造一個指定初始容量和負載因子的、按照插入順序的LinkedList
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 構造方法2,構造一個指定初始容量的LinkedHashMap,取得鍵值對的順序是插入順序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 構造方法3,用預設的初始化容量和負載因子建立一個LinkedHashMap,取得鍵值對的順序是插入順序
public LinkedHashMap() {
super();
accessOrder = false;
}
// 構造方法4,通過傳入的map建立一個LinkedHashMap,容量為預設容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的較大者,裝載因子為預設值
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// 構造方法5,根據指定容量、裝載因子和鍵值對保持順序建立一個LinkedHashMap
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
從構造方法中可以看出,預設都採用插入順序來維持取出鍵值對的次序。所有構造方法都是通過呼叫父類的構造方法來建立物件的。
LinkedHashMap和HashMap的區別在於它們的基本資料結構上,看一下LinkedHashMap的基本資料結構,也就是Entry:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
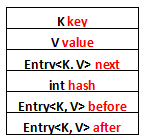
Entry裡面的屬性:
1、K key
2、V value
3、Entry<K, V> next
4、int hash
5、Entry<K, V> before
6、Entry<K, V> after
其中前面四個,也就是紅色部分是從HashMap.Entry中繼承過來的;後面兩個,也就是藍色部分是LinkedHashMap獨有的。不要搞錯了next和before、After,next是用於維護HashMap指定table位置上連線的Entry的順序的,before、After是用於維護Entry插入的先後順序的。
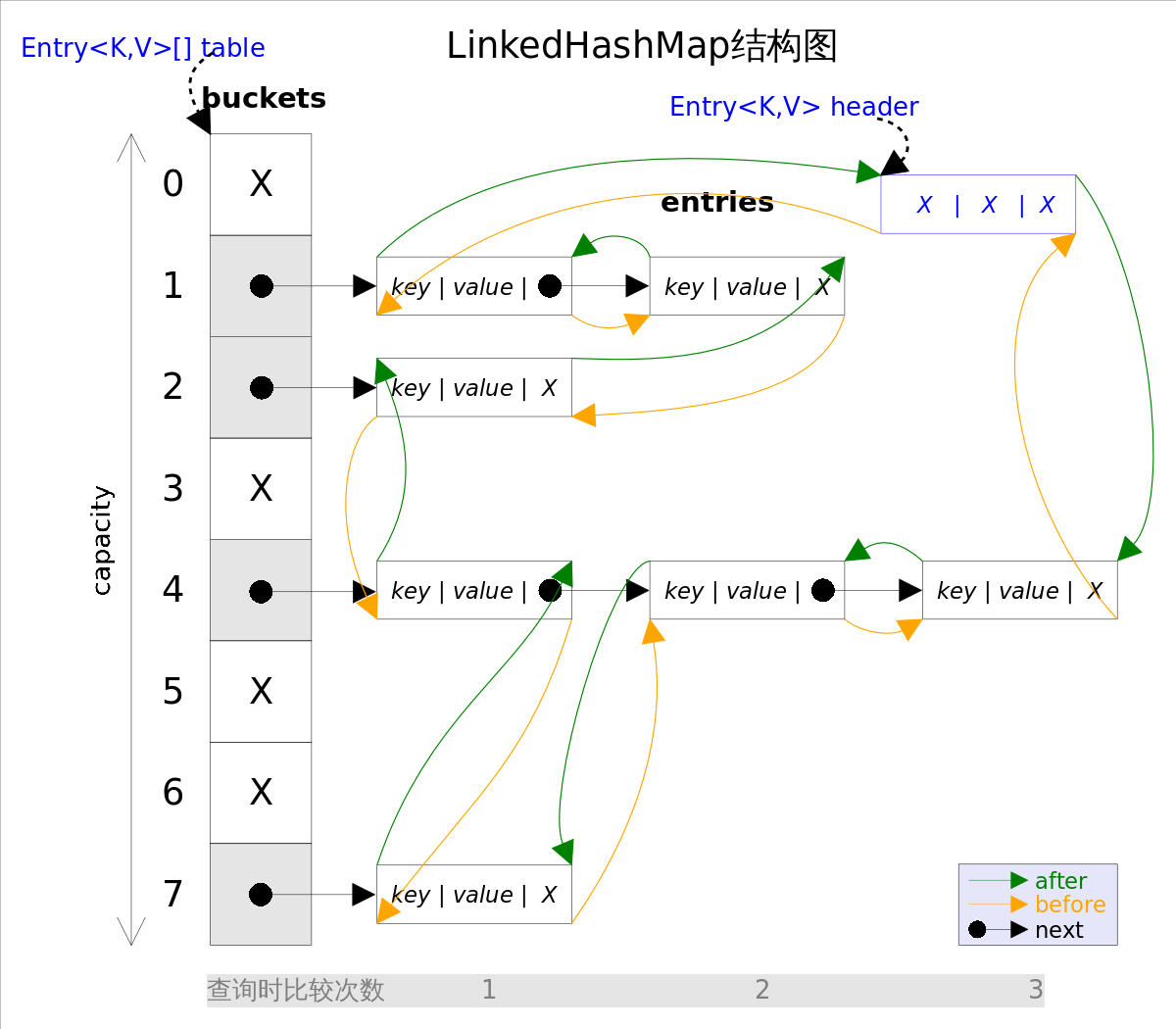
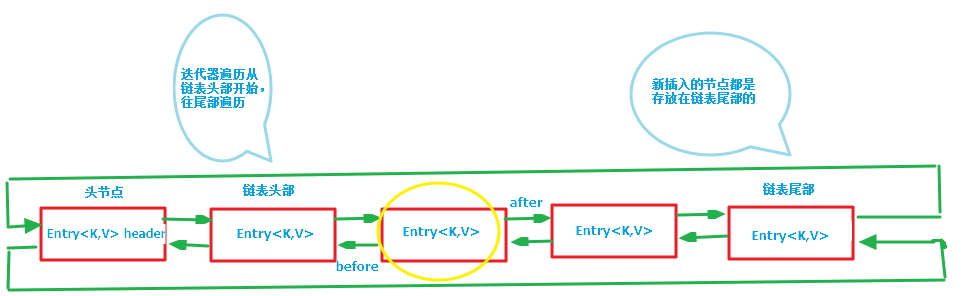
第一張圖為LinkedHashMap整體結構圖,第二張圖專門把迴圈雙向連結串列抽取出來,直觀一點,注意該迴圈雙向連結串列的頭部存放的是最久訪問的節點或最先插入的節點,尾部為最近訪問的或最近插入的節點,迭代器遍歷方向是從連結串列的頭部開始到連結串列尾部結束,在連結串列尾部有一個空的header節點,該節點不存放key-value內容,為LinkedHashMap類的成員屬性,迴圈雙向連結串列的入口。
四、初始化LinkedHashMap
假如有這麼一段程式碼:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =new LinkedHashMap<String, String>();
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
}
通過原始碼可以看出,在LinkedHashMap的構造方法中,實際呼叫了父類HashMap的相關構造方法來構造一個底層存放的table陣列.
public LinkedHashMap() {
super();
accessOrder = false;
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
我們已經知道LinkedHashMap的Entry元素繼承HashMap的Entry,提供了雙向連結串列的功能。在上述HashMap的構造器中,最後會呼叫init()方法,進行相關的初始化,這個方法在HashMap的實現中並無意義,只是提供給子類實現相關的初始化呼叫。(jdk1.8中這個方法被取消了,就是說linkedhashmap的演算法也會有區別)
LinkedHashMap重寫了init()方法,在呼叫父類的構造方法完成構造後,進一步實現了對其元素Entry的初始化操作。
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}
這裡出現了第一個多型:init()方法。儘管init()方法定義在HashMap中,但是由於:
1、LinkedHashMap重寫了init方法
2、例項化出來的是LinkedHashMap
因此實際呼叫的init方法是LinkedHashMap重寫的init方法。假設header的地址是0x00000000,那麼初始化完畢,實際上是這樣的:

注意這個header,hash值為-1,其他都為null,也就是說這個header不放在陣列中,就是用來指示開始元素和標誌結束元素的。
header的目的是為了記錄第一個插入的元素是誰,在遍歷的時候能夠找到第一個元素。
五、LinkedHashMap儲存元素
LinkedHashMap並未重寫父類HashMap的put方法,而是重寫了父類HashMap的put方法呼叫的子方法void recordAccess(HashMap m) ,void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的雙向連結列表的實現。
繼續看LinkedHashMap儲存元素,也就是put(“111”,“111”)做了什麼,首先當然是呼叫HashMap的put方法:
//這個方法應該挺熟悉的,如果看了HashMap的解析的話
public V put(K key, V value) {
//key為null的情況
if (key == null)
return putForNullKey(value);
//通過key算hash,進而算出在陣列中的位置,也就是在第幾個桶中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//檢視桶中是否有相同的key值,如果有就直接用新值替換舊值,而不用再建立新的entry了
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//上面度是熟悉的東西,最重要的地方來了,就是這個方法,LinkedHashMap執行到這裡,addEntry()方法不會執行HashMap中的方法,
//而是執行自己類中的addEntry方法,
addEntry(hash, key, value, i);
return null;
}
addEntry(hash, key, value, i);又是一個多型,因為LinkedHashMap重寫了addEntry方法,因此addEntry呼叫的是LinkedHashMap重寫了的方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
//呼叫create方法,將新元素以雙向連結串列的的形式加入到對映中
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
// 刪除最近最少使用元素的策略定義
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}
因為LinkedHashMap由於其本身維護了插入的先後順序,因此LinkedHashMap可以用來做快取,第7行~第9行是用來支援FIFO演算法的,這裡暫時不用去關心它。看一下createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//將該節點插入到連結串列尾部
e.addBefore(header);
size++;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
createEntry(int hash,K key,V value,int bucketIndex)方法覆蓋了父類HashMap中的方法。這個方法不會拓展table陣列的大小。該方法首先保留table中bucketIndex處的節點,然後呼叫Entry的構造方法(將呼叫到父類HashMap.Entry的構造方法)新增一個節點,即將當前節點的next引用指向table[bucketIndex] 的節點,之後呼叫的e.addBefore(header)是修改連結串列,將e節點新增到header節點之前。
第2行~第4行的程式碼和HashMap沒有什麼不同,新新增的元素放在table[i]上,差別在於LinkedHashMap還做了addBefore操作,這四行程式碼的意思就是讓新的Entry和原連結串列生成一個雙向連結串列。假設字串111放在位置table[1]上,生成的Entry地址為0x00000001,那麼用圖表示是這樣的:

如果熟悉LinkedList的原始碼應該不難理解,還是解釋一下,注意下existingEntry表示的是header:
1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000
2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此時是0x00000000,因此新增的Entry的before=0x00000000
3、before.after=this,新增的Entry的before此時為0x00000000即header,header的after=this,即header的after=0x00000001
4、after.before=this,新增的Entry的after此時為0x00000000即header,header的before=this,即header的before=0x00000001
這樣,header與新增的Entry的一個雙向連結串列就形成了。再看,新增了字串222之後是什麼樣的,假設新增的Entry的地址為0x00000002,生成到table[2]上,用圖表示是這樣的:

注意,這裡的插入有兩重含義:
1.從table的角度看,新的entry需要插入到對應的bucket裡,當有雜湊衝突時,採用頭插法將新的entry插入到衝突連結串列的頭部。
2.從header的角度看,新的entry需要插入到雙向連結串列的尾部(雙向連結串列的頭與尾是有連線的)。
總得來看,再說明一遍,LinkedHashMap的實現就是HashMap+LinkedList的實現方式,以HashMap維護資料結構,以LinkList的方式維護資料插入順序。
六、LinkedHashMap讀取元素
LinkedHashMap重寫了父類HashMap的get方法,實際在呼叫父類getEntry()方法取得查詢的元素後,再判斷當排序模式accessOrder為true時(即按訪問順序排序),先將當前節點從連結串列中移除,然後再將當前節點插入到連結串列尾部。由於的連結串列的增加、刪除操作是常量級的,故並不會帶來效能的損失。
/**
* 通過key獲取value,與HashMap的區別是:當LinkedHashMap按訪問順序排序的時候,會將訪問的當前節點移到連結串列尾部(頭結點的前一個節點)
*/
public V get(Object key) {
// 呼叫父類HashMap的getEntry()方法,取得要查詢的元素。
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 記錄訪問順序。
e.recordAccess(this);
return e.value;
}
/**
* 在HashMap的put和get方法中,會呼叫該方法,在HashMap中該方法為空
* 在LinkedHashMap中,當按訪問順序排序時,該方法會將當前節點插入到連結串列尾部(頭結點的前一個節點),否則不做任何事
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//當LinkedHashMap按訪問排序時
if (lm.accessOrder) {
lm.modCount++;
//移除當前節點
remove();
//將當前節點插入到頭結點前面
addBefore(lm.header);
}
}
/**
* 移除節點,並修改前後引用
*/
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
七、利用LinkedHashMap實現LRU演算法快取
前面講了LinkedHashMap新增元素,刪除、修改元素就不說了,比較簡單,和HashMap+LinkedList的刪除、修改元素大同小異,下面講一個新的內容。
LinkedHashMap可以用來作快取,比方說LRUCache,看一下這個類的程式碼,很簡單,就十幾行而已(LRU是Least Recently Used的縮寫,即最近最少使用):
public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
}
private static final long serialVersionUID = 1L;
protected int maxElements;
}
顧名思義,LRUCache就是基於LRU演算法的Cache(快取),這個類繼承自LinkedHashMap,而類中看到沒有什麼特別的方法,這說明LRUCache實現快取LRU功能都是源自LinkedHashMap的。LinkedHashMap可以實現LRU演算法的快取基於兩點:
1、LinkedList首先它是一個Map,Map是基於K-V的,和快取一致
2、LinkedList提供了一個boolean值可以讓使用者指定是否實現LRU
LRU即Least Recently Used,最近最少使用,也就是說,當快取滿了,會優先淘汰那些最近最不常訪問的資料。比方說資料a,1天前訪問了;資料b,2天前訪問了,快取滿了,優先會淘汰資料b。
我們看一下LinkedList帶boolean型引數的構造方法:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
就是這個accessOrder,它表示:
(1)false,所有的Entry按照插入的順序排列
(2)true,所有的Entry按照訪問的順序排列
第二點的意思就是,如果有1 2 3這3個Entry,那麼訪問了1,就把1移到尾部去,即2 3 1。每次訪問都把訪問的那個資料移到雙向佇列的尾部去,那麼每次要淘汰資料的時候,雙向佇列最頭的那個資料不就是最不常訪問的那個資料了嗎?換句話說,雙向連結串列最頭的那個資料就是要淘汰的資料。
“訪問”,這個詞有兩層意思:
1、根據Key拿到Value,也就是get方法
2、修改Key對應的Value,也就是put方法
首先看一下get方法,它在LinkedHashMap中被重寫:
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
然後是put方法,沿用父類HashMap的:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
修改資料也就是第6行~第14行的程式碼。看到兩端程式碼都有一個共同點:都呼叫了recordAccess方法,且這個方法是Entry中的方法,也就是說每次的recordAccess操作的都是某一個固定的Entry。
recordAccess,顧名思義,記錄訪問,也就是說你這次訪問了雙向連結串列,我就把你記錄下來,怎麼記錄?把你訪問的Entry移到尾部去。這個方法在HashMap中是一個空方法,就是用來給子類記錄訪問用的,看一下LinkedHashMap中的實現:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
看到每次recordAccess的時候做了兩件事情:
1、把待移動的Entry的前後Entry相連
2、把待移動的Entry移動到尾部
當然,這一切都是基於accessOrder=true的情況下。最後用一張圖表示一下整個recordAccess的過程吧:

void recordAccess(HashMap<K,V> m) 這個方法就是我們一開始說的,accessOrder為true時,就是使用的訪問順序,訪問次數最少到訪問次數最多,此時要做特殊處理。處理機制就是訪問了一次,就將自己往後移一位,這裡就是先將自己刪除了,然後在把自己新增,這樣,近期訪問的少的就在連結串列的開始,最近訪問的元素就會在連結串列的末尾。如果為false。那麼預設就是插入順序,直接通過連結串列的特點就能依次找到插入元素,不用做特殊處理。
八、程式碼演示LinkedHashMap按照訪問順序排序的效果
最後程式碼演示一下LinkedList按照訪問順序排序的效果,驗證一下上一部分LinkedHashMap的LRU功能:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>(16, 0.75f, true);
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
linkedHashMap.put("333", "333");
linkedHashMap.put("444", "444");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.get("111");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.put("222", "2222");
loopLinkedHashMap(linkedHashMap);
}
public static void loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap)
{
Set<Map.Entry<String, String>> set = inkedHashMap.entrySet();
Iterator<Map.Entry<String, String>> iterator = set.iterator()