
MySQL資料庫學習(一)SQL語言基本語法
一、什麼是資料庫
資料庫(Database)是按照資料結構來組織、儲存和管理資料的倉庫。
每個資料庫都有一個或多個不同的API用於建立,訪問,管理,搜尋和複製所儲存的資料。
通常使用關係型資料庫管理系統(RDBMS)來儲存和管理的大資料量。
所謂的關係型資料庫,是建立在關係模型基礎上的資料庫,藉助於集合代數等數學概念和方法來處理資料庫中的資料。
RDBMS即關係資料庫管理系統(Relational Database Management System)的特點:
1.資料以表格的形式出現
2.每行為各種記錄名稱
3.每列為記錄名稱所對應的資料域
4.許多的行和列組成一張表單
5.若干的表單組成database
SQL(結構化查詢語言)是關係型資料庫的標準語言。SQL集資料查詢、資料操縱、資料定義、資料控制為一體。
MySQL 是一個關係型資料庫管理系統又是一種關聯資料庫管理系統(將資料儲存在不同的表中,而不是將所有資料放在一個大倉庫內。增加了速度並提高了靈活性)。
二、管理MySQL的基本命令
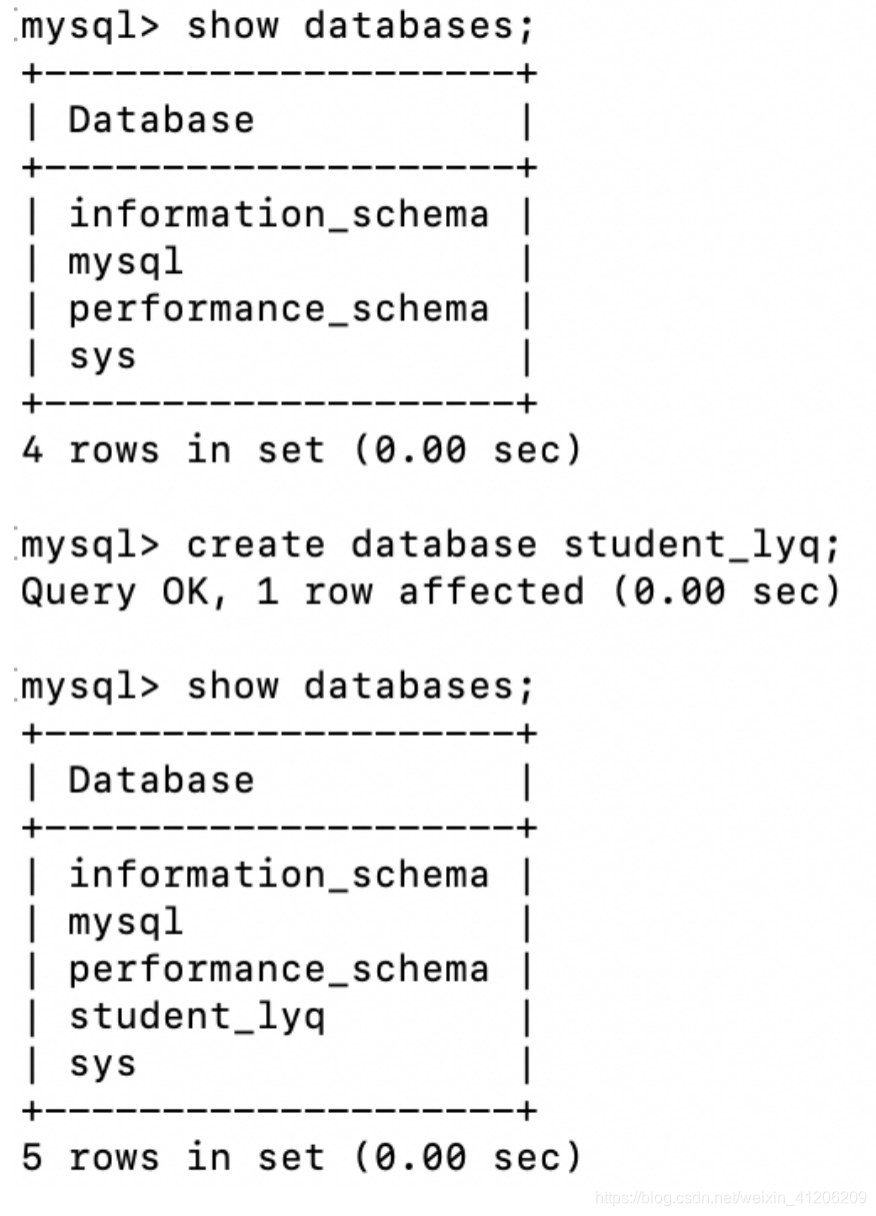
1.顯示資料庫列表

2.顯示指定資料庫的所有表,使用該命令前需要使用 use 命令來選擇要操作的資料庫。
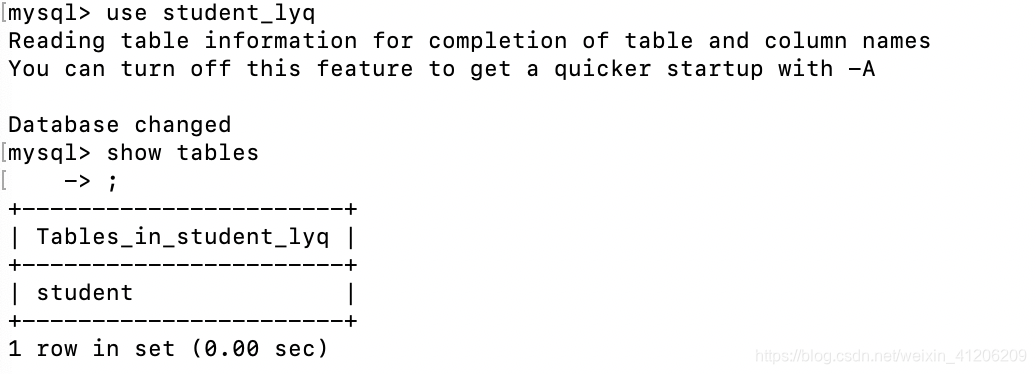
3.顯示資料表的屬性,屬性型別,主鍵資訊 ,是否為 NULL,預設值等其他資訊。

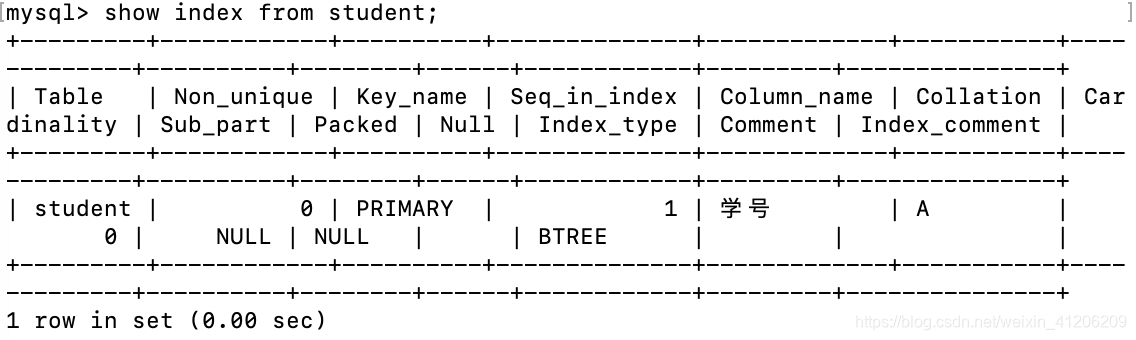
4.顯示資料表的詳細索引資訊,包括PRIMARY KEY(主鍵)
四、資料定義
下面將以一個典型的學生-課程資料庫來進行示例:
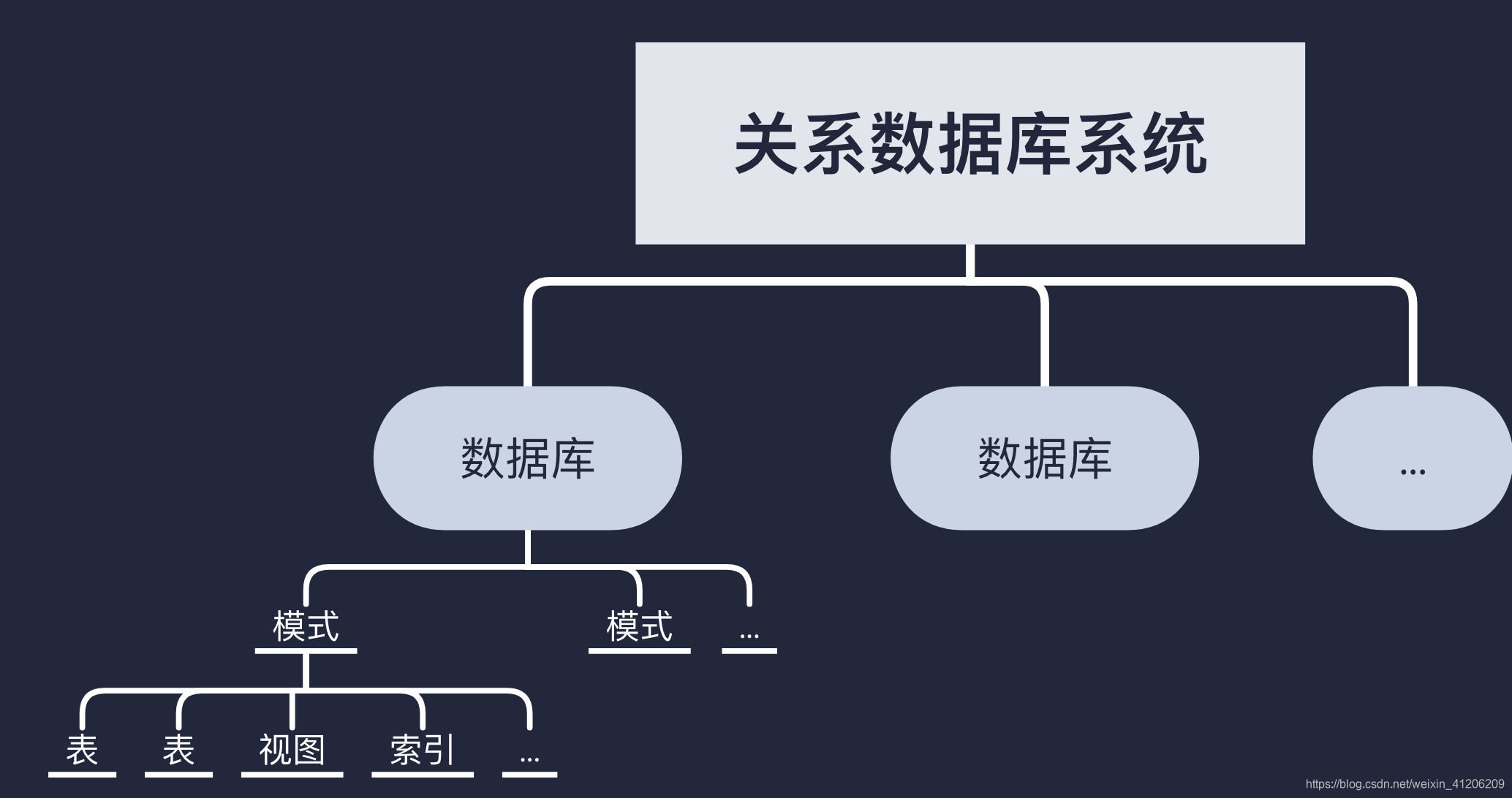
首先,因為關係資料庫支援三級模式結構,且每種模式中的基本物件都包含模式、表、檢視和索引等。因此SQL的資料定義如下表:
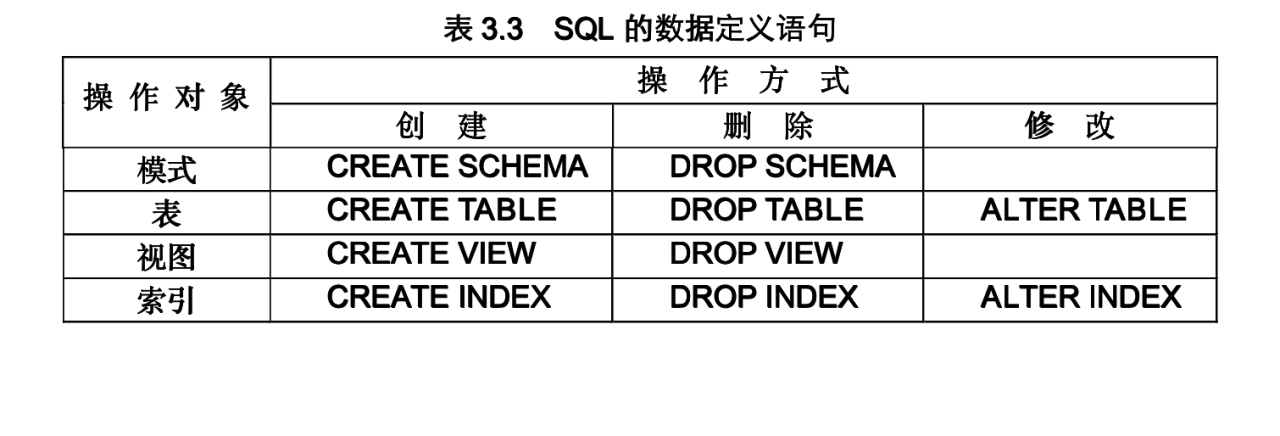
他們之間的關係如下:
1.模式的定義與刪除
//為使用者wang定義一個S-T模式
create schema S-T authorization wang;
//刪除該模式所有
drop schema S-T cascade
2.基本表的定義、刪除、修改
建立3張表:

批量插入記錄:
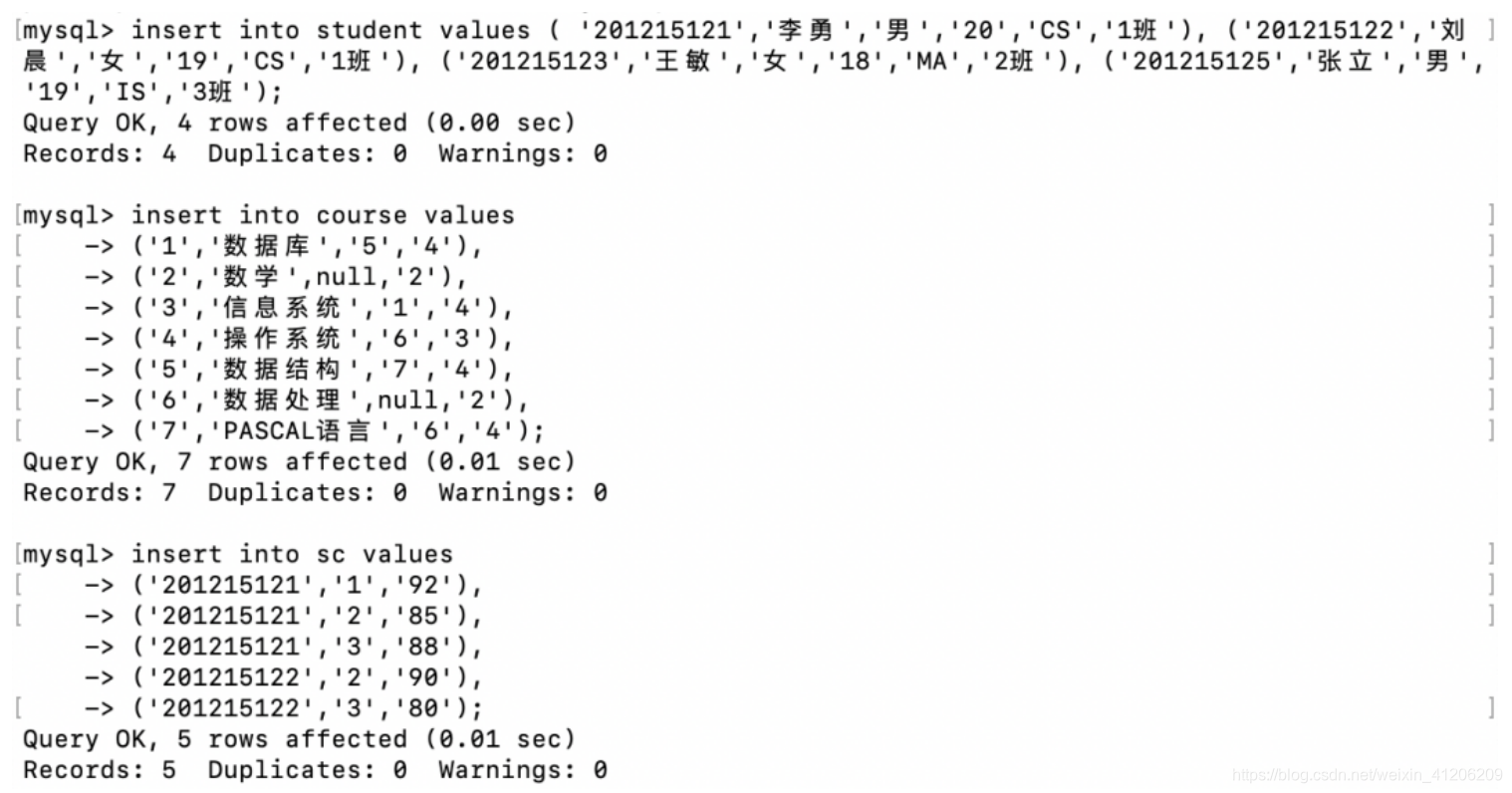
然後ding !
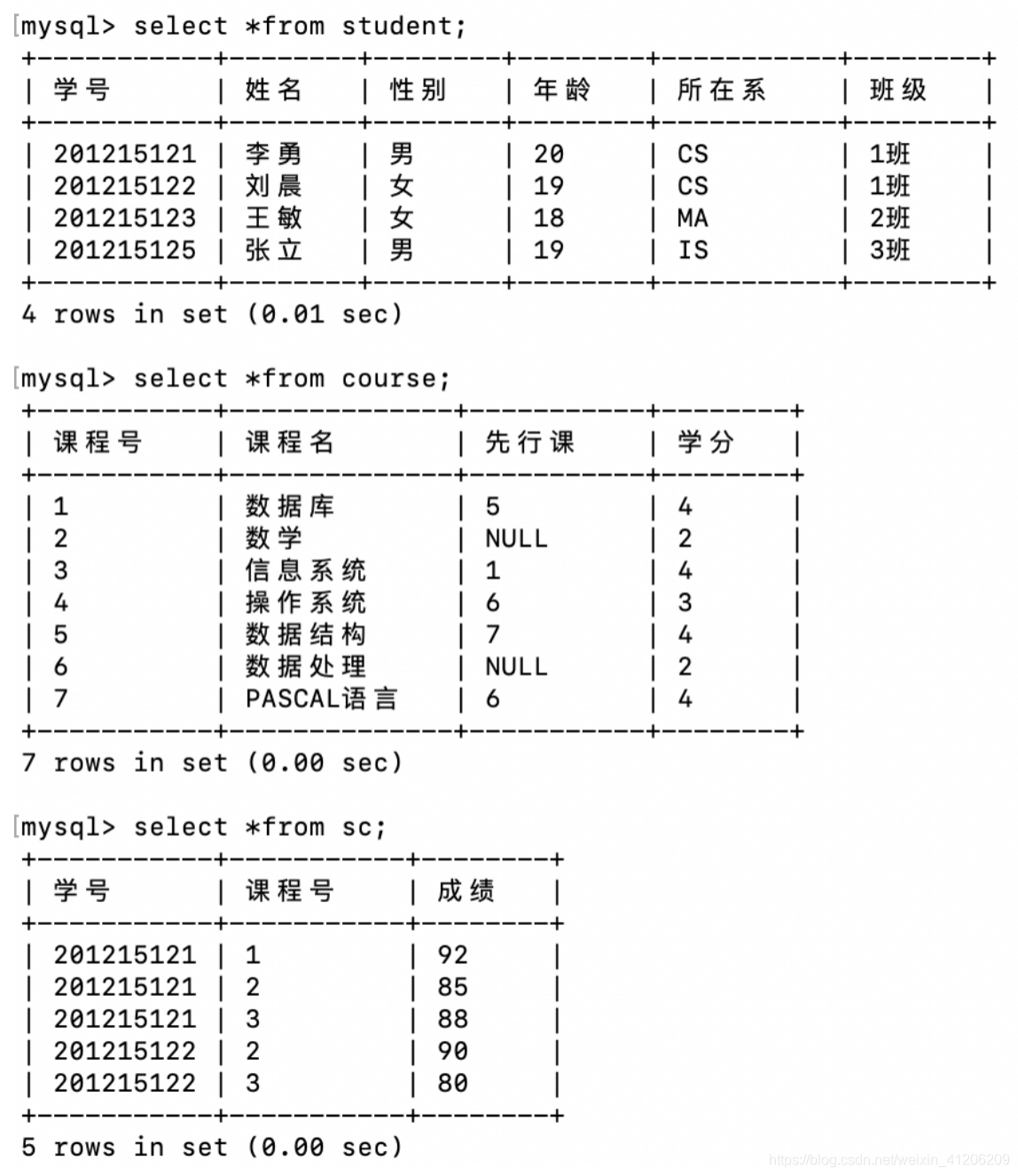
刪除:
drop table student cascade;
3.索引的建立與刪除
當表的資料量過大時,查詢操作會比較耗時。此時,建立索引能加快查詢速度。但是索引需要佔用一定的記憶體空間,且當表更新時,索引需要維護,會對資料庫造成一定的負擔。
索引有多種型別,包括:順序檔案上的索引、B+樹索引、雜湊(hash)索引、位示圖索引等。
為student 和course表按升序建立唯一索引:

刪除索引(這裡我不知道他為毛刪不掉):
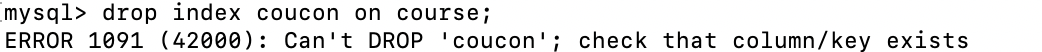
五、資料查詢
核心語句:
select 某列,某列(*表示全部)
from 某表,某表
where 某條件
group by 某列 (having 某條件)
order by 某列 (asc/升序,desc/降序)
用口水話解釋下就是:根據where的條件——從from中指定的表、檢視中找出滿足條件的元祖——按select中的目標列 選出滿足條件的屬性值得出結果表。
若是有group by的話,則先按 某列 的值進行分組,屬性相等為一組。若同時還帶having,則只挑選滿足指定條件的組輸出。
若是有order by的話,結果還要排序一下。
1.單表查詢
- 查詢全體學生的學號與姓名:
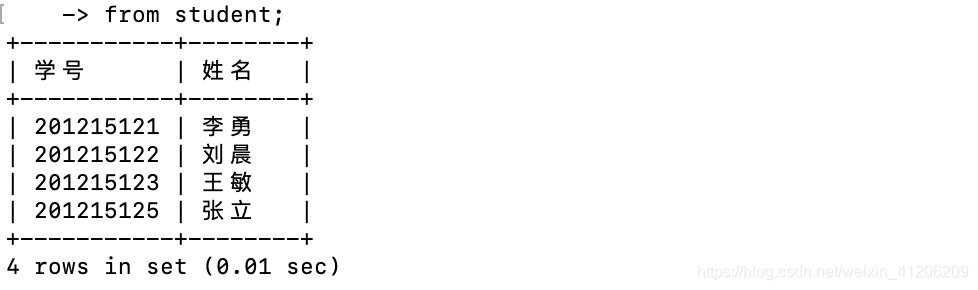
- 查詢全部列:

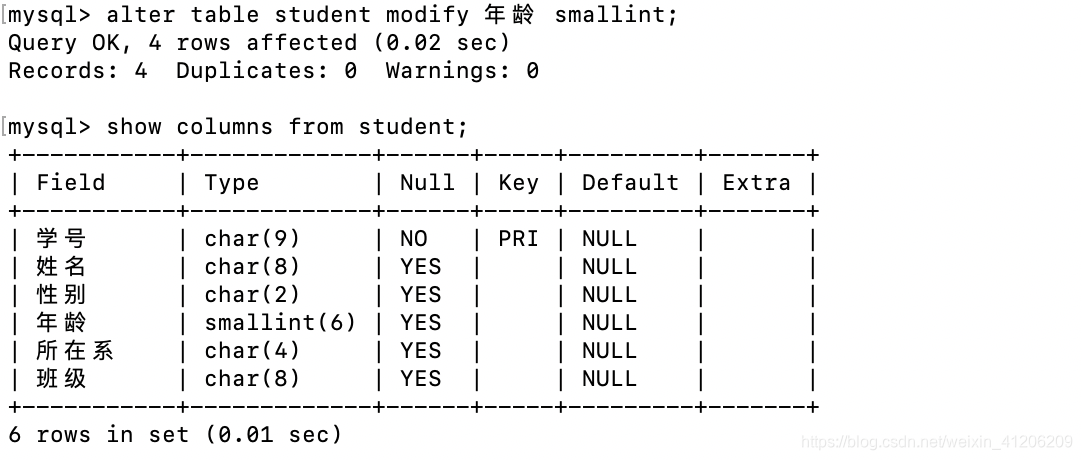
- 查詢全體學生的姓名及出生年份:
因為需要計算,先改下年齡的欄位型別為smallint,因為char無法參與計算

欄位名看上去不是很好看?可以自己定義哦
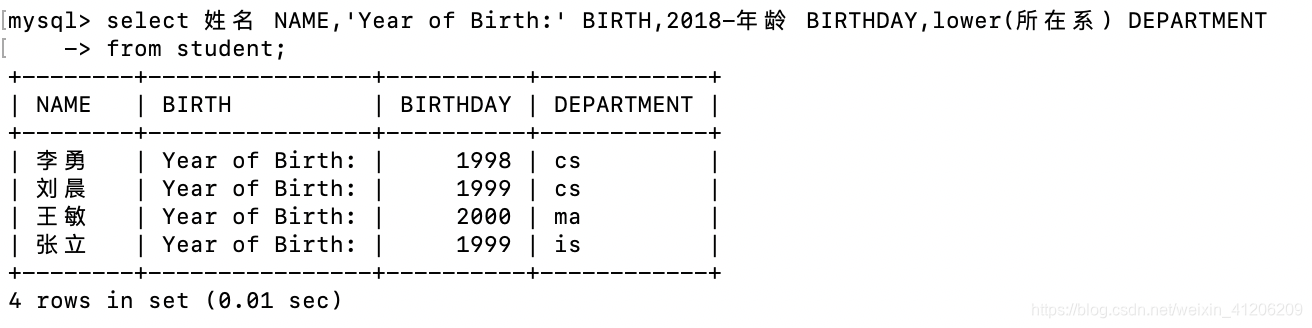
- 查詢選修了課程的學生學號:
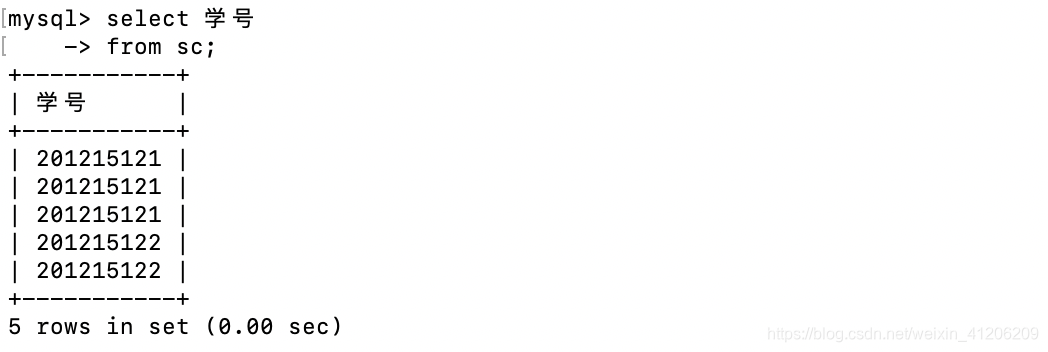
重複太多?

- 查詢計算機科學系全體學生的名單:

- 查詢所有20歲以下的學生姓名及學號:
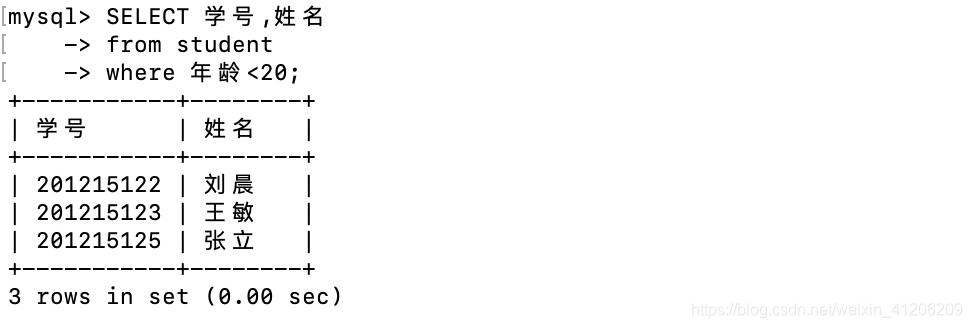
- 查詢不及格的學生姓名:(看來大家成績都很好嘛)

- 查詢年齡在19-20歲之間的學會姓名,系別和年齡:

反之:

- 查詢數學系和資訊系學生的姓名和性別:

- 查詢所有姓劉的學生姓名,學號:
%代表任意長度的字串,_代表任意單個字串
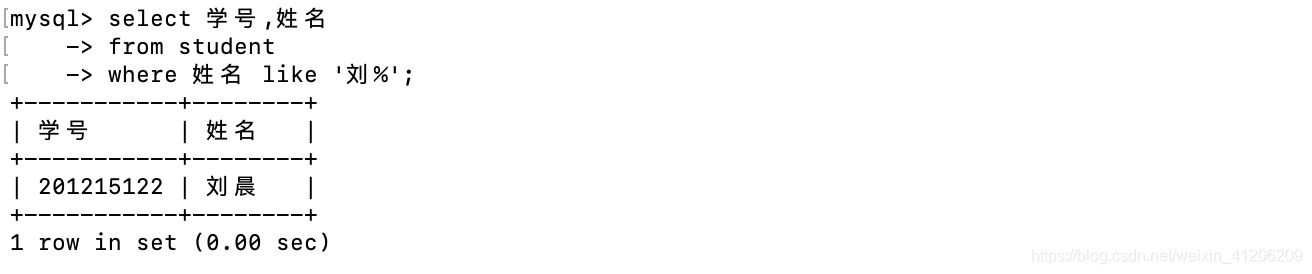
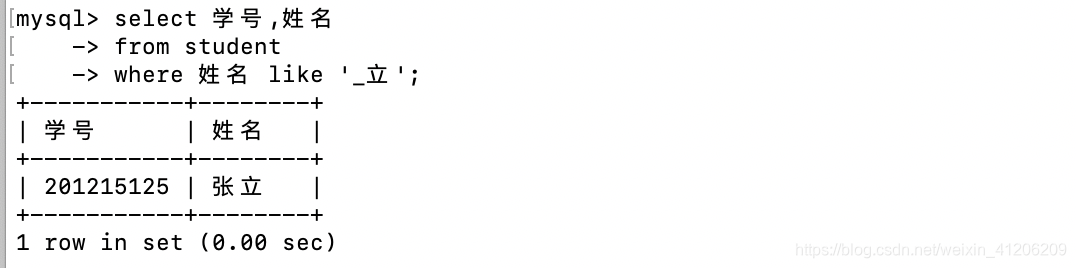
-
查詢D_B課程的課程號(假裝有D_B課)
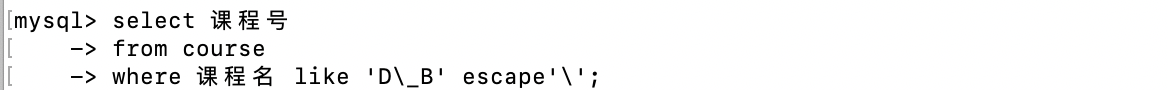
-
查詢沒參加考試的學生姓名:

-
查詢計算機科學系年齡在20歲以下的學生姓名:

-查詢選修了3號課程的學號和成績,按成績降序輸出:

-
查詢學生總人數:
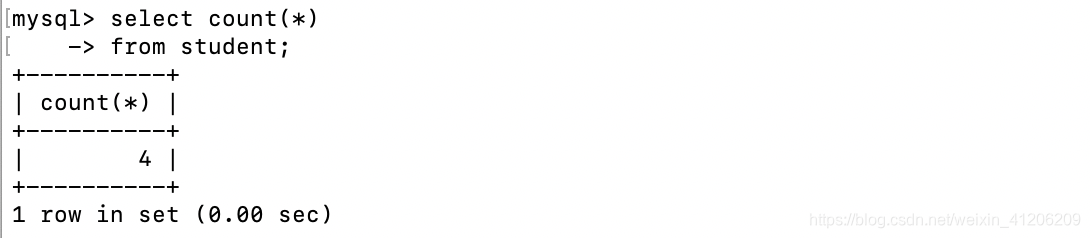
-
查詢選修了課程的學生人數:
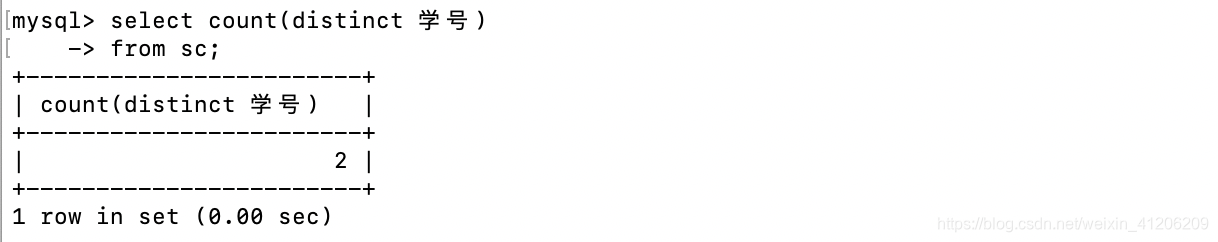
-
計算選修1號課程的學生平均成績
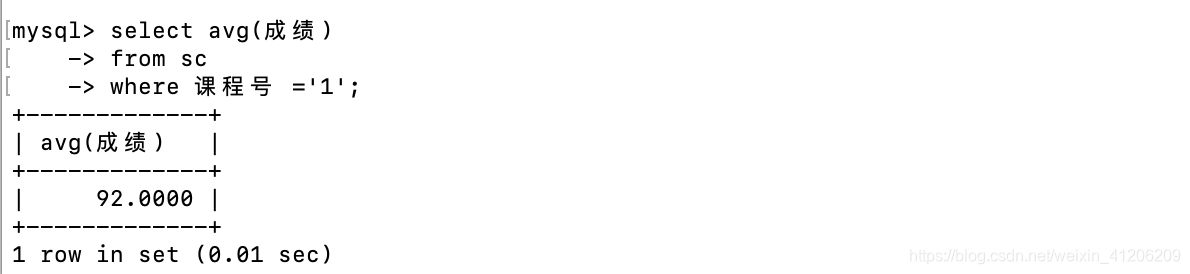
-
查詢選修2號課程的學生最高分數:

- 查詢學生201215121選修課程的總學分數:

- 查詢各個課程號及相應的選課人數:

- 查詢選修了1門以上課程的學生學號:

- 查詢平均成績大於90分的學生學號

2.連線查詢
包括等值連線查詢、自然連線查詢、非等值連線查詢、自身連線查詢、外連線查詢、複合條件連線查詢等。
- 查詢每個學生及其選修課程的情況
等值連線:
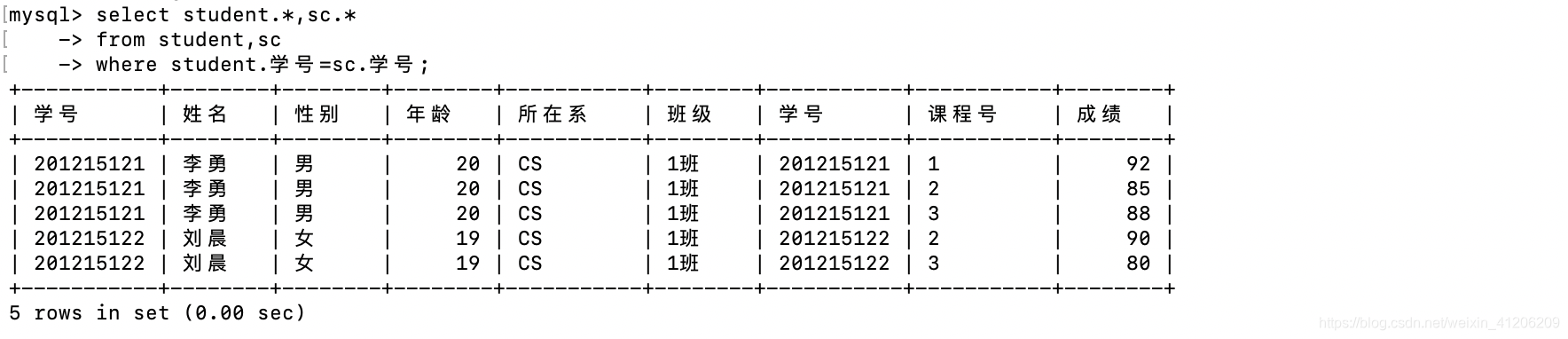
自然連線(去掉重複屬性的列):
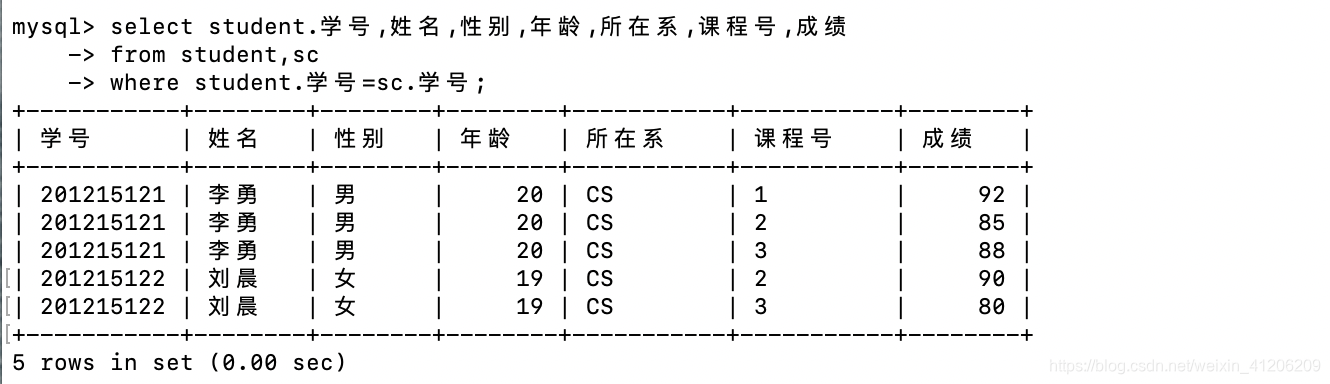
- 查詢選修2號課程且成績在80分以上的所有學生的學號和姓名:

- 查詢每一門課程的間接先修課(即先修課的先修課):

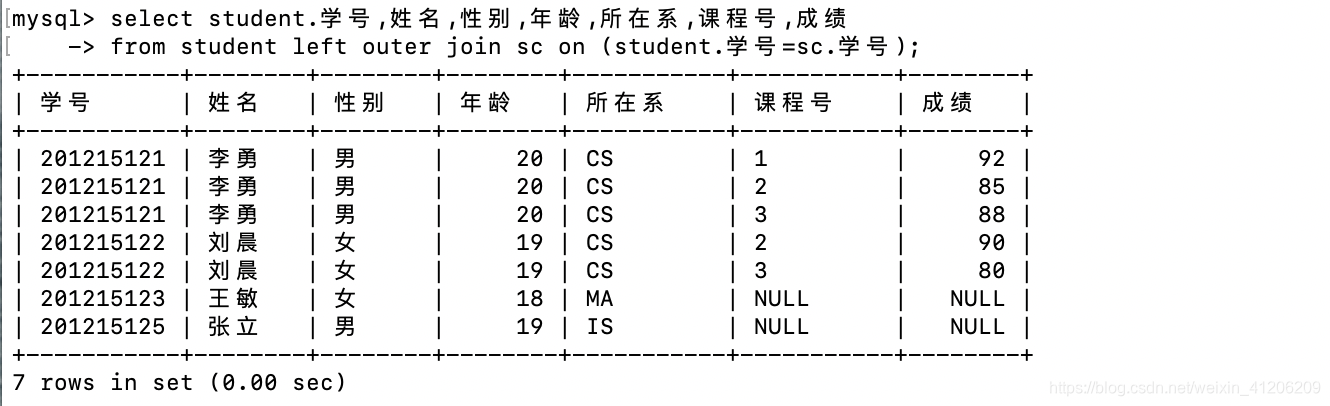
- 外連線(左外連線,右外連線):
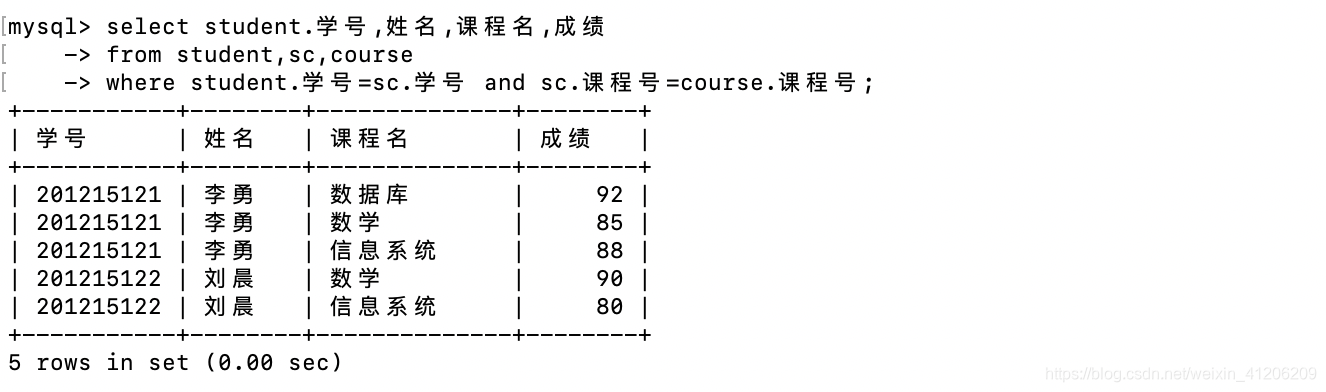
- 多表連線(查詢每個學生的學號,姓名,選修的課程及成績:
3.巢狀查詢
SQL語句中,一個 select-from-where 語句稱為一個查詢塊。將一個查詢塊巢狀在另一個查詢塊的where子句或having語句中的查詢稱為巢狀查詢。
- 帶in的子查詢:查詢與“劉晨”在同一個系的學生

這題也可以用自然連線來做:

查詢選修了課程名為“資訊系統”的學生學號和姓名:

方法二:(現實生活中,能用連線運算儘量連線運算)

- 帶有比較運算子的子查詢
找出每個學生超過他自己選修課程平均成績的課程號:

即從sc中取一行與所有行作比較。
注:求解相關子查詢不能像求解不相關子查詢一樣將子查詢求解出來,然後求解父查詢。
- 帶有any (some) all 的子查詢
子查詢返回單值時可以用比較運算子,但返回多值時要用any(some)或者all修飾符。且使用any或all是必須同時使用比較運算子。
查詢非計算機科學系中比計算機科學系任意一個學生年齡小的學生姓名和年齡:

也可以用聚集函式來做:

- 查詢非計算機科學系中比計算機科學系所有學生年齡小的學生姓名和年齡:
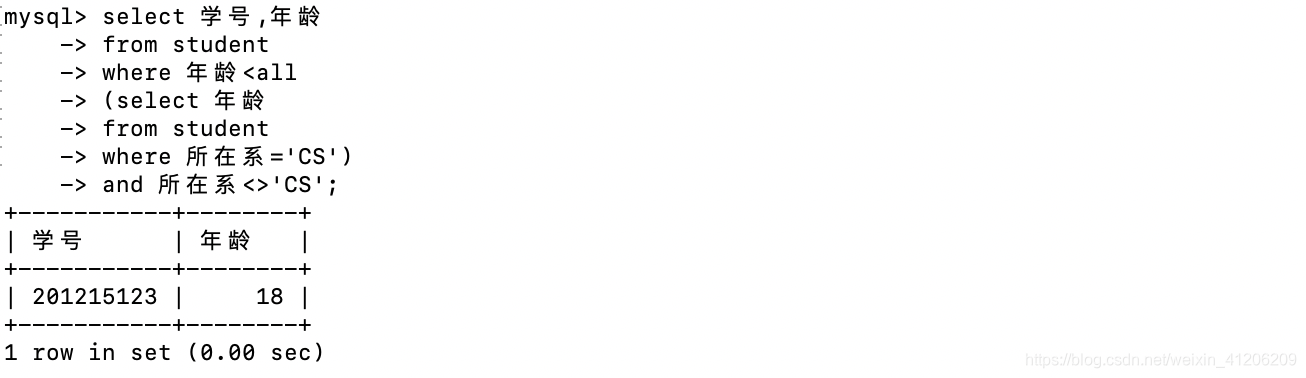
聚集函式:

- 帶有exists的子查詢
帶有exists的子查詢不返回任何資料,只產生"true"和"false".
查詢了所有選修了1號課程的學生姓名:

注:由exists引出的子查詢,其目標列表達式通常為*,因為帶exists的子查詢只返回其真值或假值,給出列名無實際意義。
所有帶IN、比較運算子、ANY和ALL的子查詢都能用帶EXISTS子查詢替代。
例如,查詢選修了所有課程的學生姓名:
換言之,即沒有一門課是他沒有選修的

再舉個栗子:查詢至少選修了學生201215122選修的全部課程的學生學號
即:不存在這樣的課程y,學生201215122選修了y,而學生x沒有選。
4.集合查詢
集合操作主要包括:並操作UNION、交操作INTERSECT、差操作EXCEPT (mysql只支援UNION)
注:參加集合查詢的各查詢結果的列數必須相同,對應項的資料型別也必須相同。
- 查詢計算機科學系的學生及年齡不大於19歲的學生:
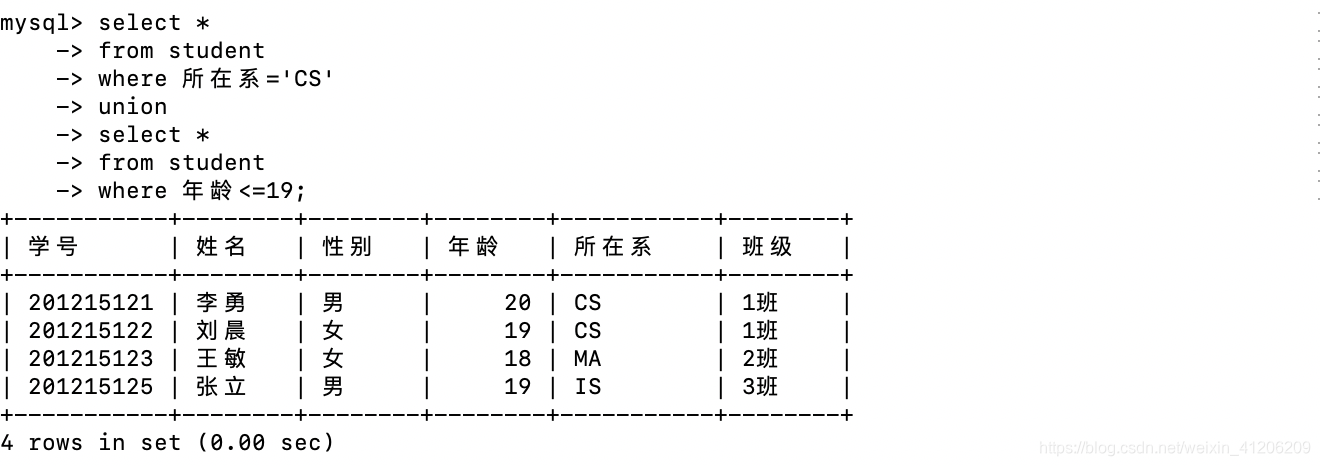
5.基於派生表的查詢
子查詢不僅可以出現在where語句中,還可以出現在from 語句中,這是子查詢生成的臨時派生表成為主查詢的查詢物件。
六、資料更新(即增刪改)
1.插入資料
插入有兩種:一是插入元組,二是插入子查詢結果。
插入元組:
inset
into student(學號,姓名,性別,所在系,年齡)
values('201215218','陳東','男','IS','18');
插入子查詢結果:
對於每一個系,求學生的平均年齡,並把結果存入資料庫:
首先在資料庫新建一個表,再對student分組求平均年齡,填入新表。

2.修改資料(更新)
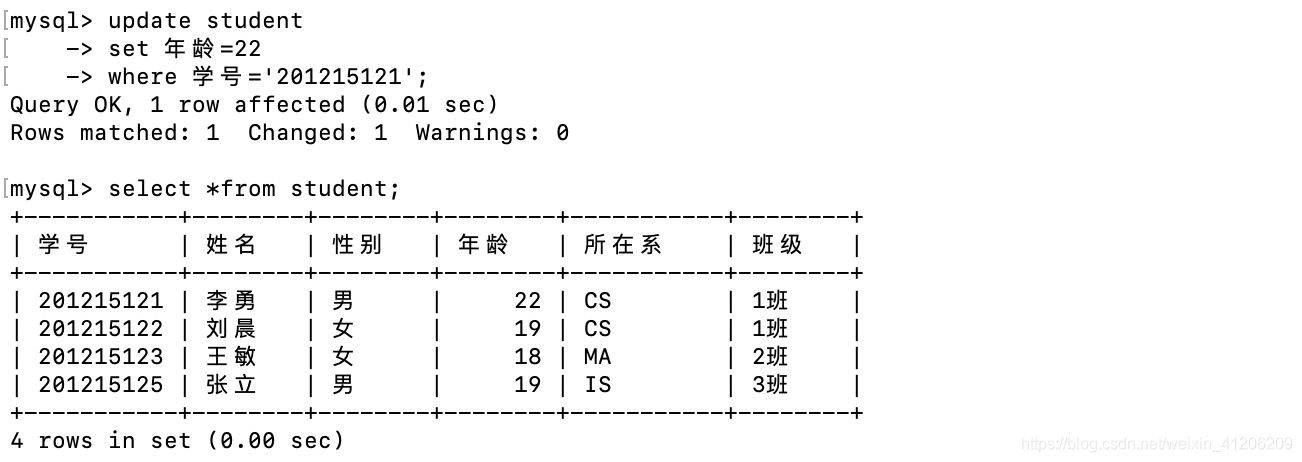
- 修改某一元組的值
例:將學生201215121的年齡改為22歲
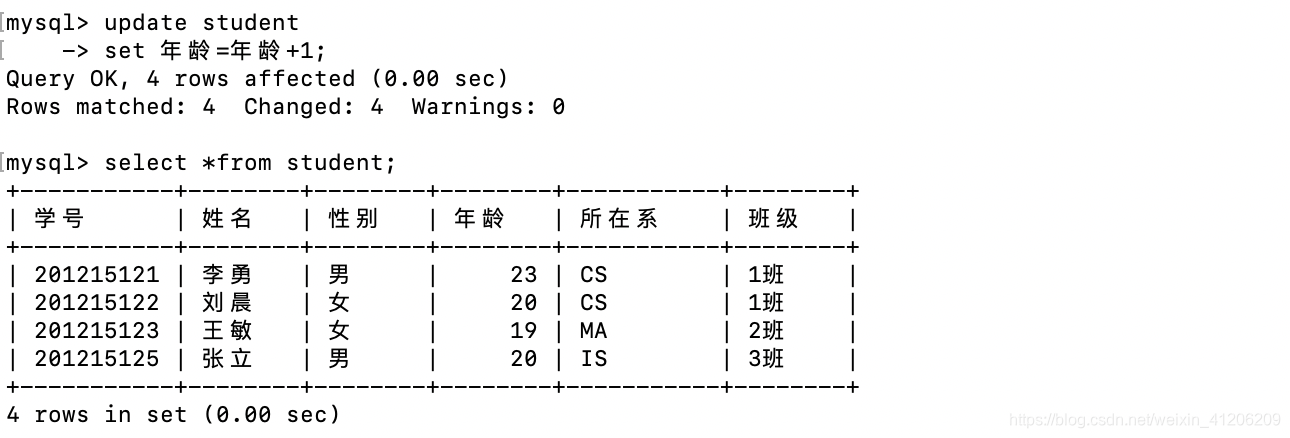
- 修改多個元組的值
例:將所有學生的年齡增加2歲。
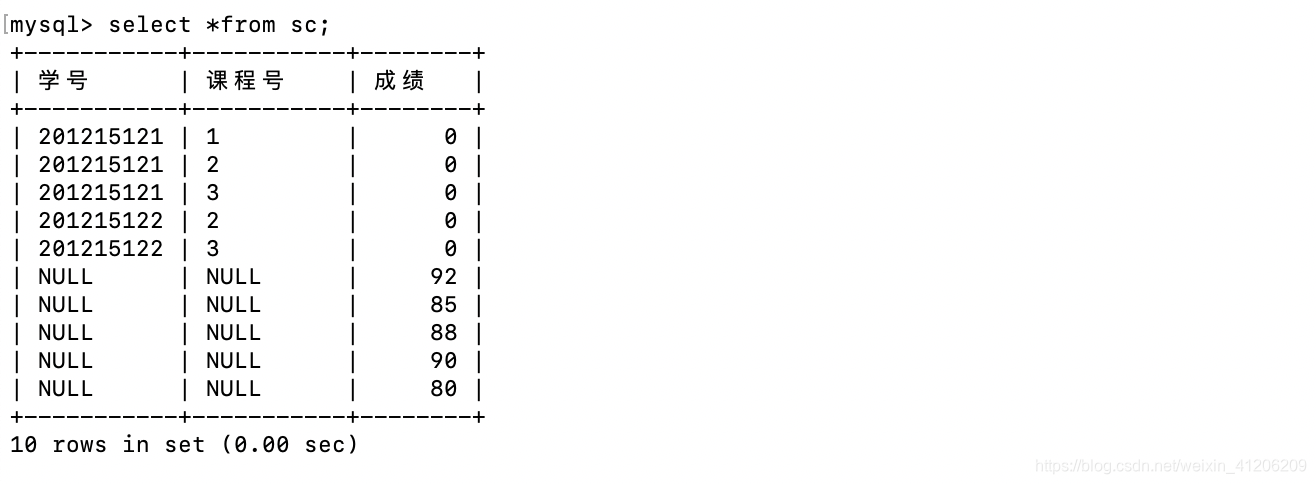
- 修改帶子查詢的值
例:將計算機科學系全體學生的成績置0

3.刪除資料

七、空值的處理
三種不能取空值的情況:NOT NULL, UNION, KEY;
空值與一個值的運算結果為空值,與一個值的比較結果為UNKNOWN;
所在在查詢表時,要考慮到空值的情況:
查詢1號課程不及格的學生(包括缺考)
select 學號
from sc
where 成績<60 and 課程號 = '1';
上面的查詢若是有缺考就查不出來,UNKNOWN,改為:
select 學號
from sc
where 課程號 = '1'and (成績<60 or 成績 is null);
打了一遍,感覺MySQL的基本語法算是熟悉了…也花了我好多時間鴨~
趕資料庫的實驗報告去了~