
知識表示模型彙總分析--Trans系列
作者:孫天祥
連結:https://zhuanlan.zhihu.com/p/43436288
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
因為還根據自己的理解補充了點兒內容,就標為原創了。下面是正文:
近年來,以深度學習為代表的表示學習迅速發展,在很多領域都取得了巨大進展。簡而言之,表示學習將要描述的物件表示為低維稠密向量,這也被稱為分散式表示,從而有效解決了資料稀疏問題,並且便於在低維語義空間中進行計算。將表示學習應用於知識圖譜(Knowledge Graph, KG),即是知識表示學習。
在當前的主流知識庫中,知識被儲存為 的三元組形式,其中
目前,知識表示學習方法從實現形式上可以分為兩類:基於結構的方法和基於語義的方法。基於結構的嵌入表示方法包括TransE, TransH, TransR&CTransR, TransD等,這類方法從三元組的結構出發學習KG的實體和聯絡的表示;基於語義的嵌入表示方法包括NTN, SSP, DKRL等,這類方法從文字語義的角度出發學習KG的實體和聯絡的表示。
知識表示學習從發展來看可以分成兩個階段,以2013年Borders等人受Mikolov發現的語義空間中詞向量的平移不變現象啟發,從而提出了翻譯模型
作者:孫天祥
連結:https://zhuanlan.zhihu.com/p/43436288
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
TransE
我們用
顯然,對於正確的三元組,應該有較低的得分。在訓練過程中,使用等級損失函式,這是因為在當前情況下我們沒有就標籤而言的監督,只有一對正確項
上式中的
博主注:
我們的目標是讓f(h,t)最小,讓f(h',t')最大。開始我覺得上面的公式不對,因為應該是取上式的極小值作為目標函式。後來想了想,上式僅僅是損失函式,表示的是總體損失。式中的max不是對目標函式取max,而是對於每一對正反例,取f(h,t)+v-f(h',t')和0中的最大值,以免出現負值。
避免出現負值的原因:如果某一項是負的,那麼可以通過使得這個負值的模非常大,來使得整個公式的值是一個模非常大的負值。而這樣顯然不是我們想要的。這樣僅僅使得某一項符合要求,並不是全域性最優。
如果我自己設計一個公式,估計是不能想到這一點的。看來頂會論文的水平還是很高的,方法既新奇又滴水不漏。
事實上,將等級損失中的得分函式替換為樣本被預測為某個類別的概率,則上式的形式與多分類情形下的hinge損失一致。
TransE採取的生成負例三元組的方法是,將正確的三元組的頭實體、尾實體、關係三者之一隨機替換為其他實體或關係,從而構成負例集合 ,這種方法稱為均勻取樣(與後面的伯努利取樣相對比)。
在程式碼實現中,首先選取一個正例三元組 ,再從
中取樣得到一個負例三元組
,然後分別計算正例得分
和負例得分
,若
,則梯度下降更新
.
顯然,TransE模型在處理複雜關係建模(一對多、多對一、多對多關係)時會遇到困難,例如,對於一對多關係(美國,總統,奧巴馬)和(美國,總統,特朗普),TransE模型會使得尾實體向量奧巴馬和特朗普的表示非常相似。事實上,這是由於對於不同的關係 ,實體向量的表示總是相同的。
TransH
論文:Knowledge Graph Embedding by Translating on Hyperplanes. Zhen Wang, Jianwen Zhang, Jianlin Feng, Zheng Chen. AAAI 2014.
TransH方法由中山大學信科院馮劍琳團隊和MSRA聯合提出,克服了TransE模型的上述缺點,使得同一個實體向量在不同關係下有不同的表示。
TransH模型對於每一個關係 ,假設有一個對應的超平面(關係
落於該超平面上),其法向量為
,且有
. 關於超平面,可以參見這裡。
類似於TransE模型的翻譯在該超平面上進行,具體地,首先將頭實體 和尾實體
投影到該超平面上得到
和
,即
博主注:
上述公式可以將h和t進行投影。以h為例,其中的wT*h是一個數,是將h投影到w方向的向量的模。後面再乘一個w是為了把這個標量變成向量。這樣的話,h與這個向量的差就是h在超平面上的投影向量。
進而,我們定義得分函式為
原文中貼出了一張圖,很直觀的說明了TranH的工作原理,以及和TransE的區別。
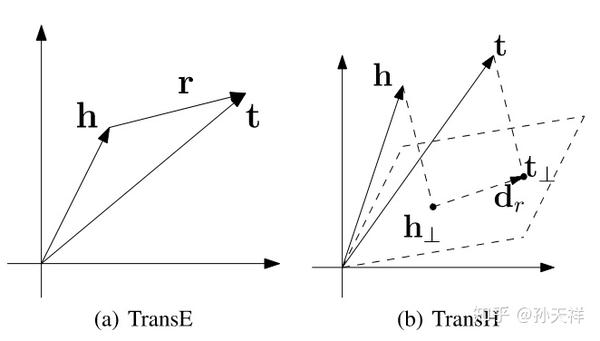
博主注:
考慮之前總統的例子,也就是一個一對多的問題。將關係表示成超平面後,這種問題得到了解決。如下圖所示,如果分別用t和t‘表示兩個總統,那麼將三元組對映到超平面之後,t和t‘都能滿足’(美國,總統,*)這個三元組。並且兩個向量在向量空間還是不同的。多對一,多對多的情況也可以這樣解決。

當然,投影后我們需要訓練的引數就不止是實體和關係向量了。還得訓練投影平面(其實就是每個關係對應的投影平面的法向量)。目標函式變為:


其中[]+表示的就是TransE公式中的max(*,0),即對於中括號中的值,返回0和它之間的最大值。
上式還得滿足三個限制。其中,限制(1)保證每個向量的模都小於1。限制(2)是dr到wr的投影長度/dr的長度,這個值非常小,保證了dr確實在投影平面上。限制(3)規定投影平面的法向量的模為1,這樣做是為了簡化公式。否則這個公式的形式就會更為複雜。
雖然TransH模型使得同一實體在不同關係下通過投影有了不同的表示,但投影之後仍然處於原來的空間 中,這裡
表示實體向量和關係向量均為
維。換言之,TransH模型假設實體和關係處於相同的語義空間中,這在一定程度上限制了它的表示能力。下面的TransR模型改進了這一缺陷,提高了模型的表示能力。
值得一提的是,在本篇論文中除了提出了TranH模型,另一貢獻是提出了基於伯努利分佈的取樣方法。在原來的均勻取樣中,容易將錯誤的負例引入到訓練過程中來,例如,對於正例(美國,總統,奧巴馬),隨機替換奧巴馬為羅斯福構成(美國,總統,羅斯福)作為負例,實際上由於羅斯福也是總統,這並不是一個負例。新的取樣方法的動機是,對於一對多關係,我們以更大的概率來替換其頭實體,對於多對一關係,我們以更大的概率來替換其尾實體。具體地,對於包含關係 的所有三元組,我們定義兩個統計量:
1. : 平均每個頭實體對應多少個尾實體
2. : 平均每個尾實體對應多少個頭實體
進而,取伯努利分佈的引數為 ,即以概率
替換三元組的頭實體,以概率
替換三元組的尾實體。實際上,
反映了一對多關係的失衡程度。
博主注:
可以先忽略分母(分母是用來歸一化的)。那麼,tph表示一個頭實體大概對應多少尾實體。這個值越大說明我們在構建負例時,固定頭實體,隨機選擇尾實體的過程中越可能出錯(一不小心就弄成正例了)。所以這時候我們應該替換頭實體。因此歸一化的tph就是替換頭實體的概率。相似地,歸一化的hpt就是替換尾實體的概率。
通過基於伯努利分佈的取樣,我們就降低了引入錯誤的負例的概率。在清華大學NLP組的開原始碼KB2E中,同時提供了兩種取樣方式,bern表示伯努利取樣,unif表示均勻取樣。
TransR & CTransR
TransR
TransR模型是由清華大學NLP組(林衍凱、劉知遠、孫茂松等)提出,TransR模型認為,不同的關係關注實體的不同屬性(實體向量的不同維度),因此不同的關係應具有不同的語義空間。
TransH模型是為每個關係假定一超平面,將實體投影到這個超平面上進行翻譯;而TransR模型是為每個關係假定一語義空間 ,將實體對映到這個語義空間上進行翻譯。這裡
表示關係向量的維度為
。
TransR模型可以形式化描述為
其中, . 約束條件為
的L2範數均不大於1.
CTransR
CTransR的意思是Cluster-based TransR. CTransR對於每一個特定的關係 ,首先根據實體對
進行AP聚類(一種不需要指定類別數的聚類方法),實際上是對實體對的差值向量
進行聚類,從而將關係
分解為更細粒度的子關係
,CTransR對每個
分別學習相應的向量表示。
形式化地,CTransR的得分函式可以描述為
上式中第二項使得 儘可能地接近
.
TransR & CTransR模型將原來的單個語義空間分離為實體空間和關係空間,提高了模型的表示能力,然而,TransR模型仍然存在一些缺點:
1. 在同一個關係 下,頭、尾實體使用相同的投影矩陣
,而頭、尾實體可能型別或屬性相差很大;
2. 投影矩陣僅與關係有關;
3. 引數多,計算複雜度高。
TransD
論文:Knowledge Graph Embedding via Dynamic Mapping Matrix. Guoliang Ji, Shizhu He, Liheng Xu, Kang Liu, Jun Zhao. ACL 2015.
TransD模型由中科院自動化所NLPR中趙軍、劉康組提出,一定程度上克服了TransR & CTransR的上述缺點。
CTransR模型相比於TransR模型,實際上就是考慮了同一個關係也有不同的型別,然而,實體也有不同的型別。舉個例子,在FB15k中,有關係location.location.partially containedby,它可以表示山川大河被某個國家包含,也可以表示山川大河被某個城市/州包含,也可以表示國家被大洲包含,還可以表示地區被國家包含。由於實體有不同的型別,因而使用相同的對映矩陣是不合理的,而且,對映矩陣不應只與關係有關,還應與頭尾實體有關。以上就是TransD模型的動機,這實際上是一個更細粒度的擴充套件模型,本質上還是由實體語義空間和關係語義空間兩個空間構成。
具體地,對於一個三元組 ,分別定義對應的投影向量
,其中
表示投影(projection),再定義兩個投影矩陣
來將實體從實體空間對映到關係空間。
這裡, ,
表示單位陣,它的意思是說用單位陣來初始化投影矩陣。
Tips: 如果你檢查過向量和矩陣的維度,可能會發現在TransD中,實體和關係向量均為列向量,而在前面的模型中實體和關係都是行向量。這裡尊重了原文中的形式,並未在本文中做統一。
可見,在上式中,對頭實體應用投影矩陣 ,它不僅與關係有關,還與頭實體有關;對尾實體應用投影矩陣
,它也不僅與關係有關,還與尾實體有關。利用這兩個投影矩陣,可以得到頭實體和尾實體在關係空間的投影
從而得分函式為
對比
理論對比
顯然,TransE是TransD的一個特例,當 且所有投影向量均為零時,TransD就退化為了TransE. 與TransH對比,顯然需先令TransD的
,再分別寫出TransH和TransD的實體投影后的向量:
因為 ,因此為便於格式上的對比,我們將TransD中的
寫成上述形式。可見,當
時,TransD與TransH唯一的區別在於TransD中的投影向量不僅與關係有關,還與實體有關。
對比TransR模型,TransD為頭實體和尾實體分別設定了投影矩陣,另外,注意到在TransD中公式經過展開之後沒有矩陣-向量乘法操作,這相比於TransR模型降低了計算複雜度,更適用於大規模知識圖譜的計算。
效能對比
評估不同知識表示學習方法的優劣的主要指標就是在知識圖譜的一些典型任務上的表現,比如三元組分類(triplet classification)和連結預測(link prediction)。下面貼出在WordNet和Freebase中各模型在兩任務上的表現,TransE, TransH, TransR, CTransR, TransD包括了使用bern和unif取樣的結果。圖片資料來源於TransD的論文。
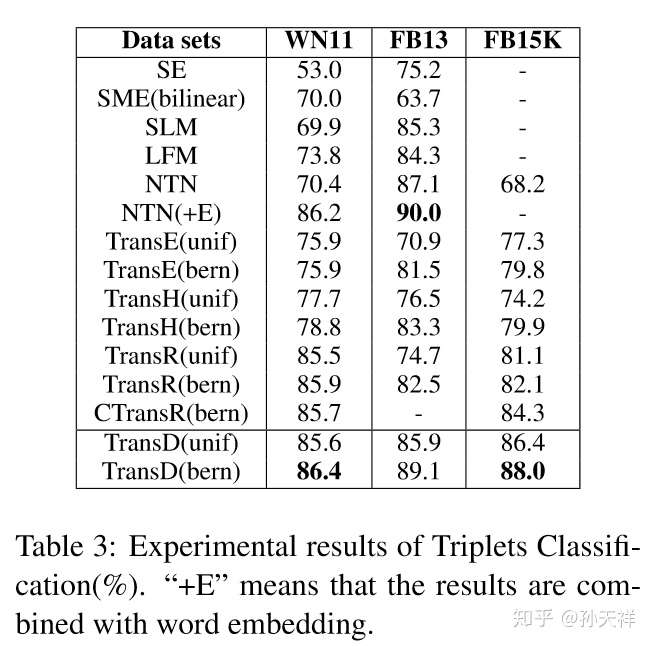
三元組分類結果對比
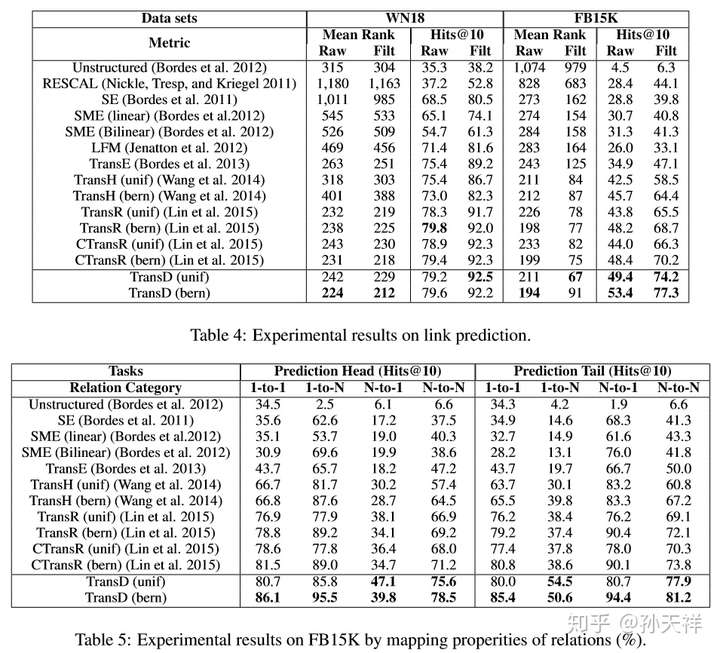
連結預測結果對比