
模型評估方法(混淆矩陣)
在資料探勘或機器學習建模後往往會面臨一個問題,就是該模型是否可靠?可靠性如何?也就是說模型的效能如何我們暫時不得而知。
如果模型不加驗證就使用,那後續出現的問題將會是不可估計的。所以通常建模後我們都會使用模型評估方法進行驗證,當驗證結果處於我們的可控範圍之內或者效果更佳,那該模型便可以進行後續的進一步操作。
這裡又將面臨一個新的問題——如何選擇評估方法,其實通常很多人都會使用比較簡單的錯誤率來衡量模型的效能,錯誤率指的是在所有測試樣例中錯分的樣例比例。實際上,這樣的度量錯誤掩蓋了樣例如何被分錯的事實。其實相對於不同的問題會有不同的評估思路:
迴歸模型:
對於迴歸模型的評估方法,我們通常會採用平均絕對誤差(MAE)、均方誤差(MSE)、平均絕對百分比誤差(MAPE)等方法。
聚類模型:
對於聚類模型的評估方法,較為常見的一種方法為輪廓係數(Silhouette Coefficient ),該方法從內聚度和分離度兩個方面入手,用以評價相同資料基礎上不同聚類演算法的優劣。
分類模型:
本篇文章將會主要描述分類模型的一種評估方法——混淆矩陣。對於二分類問題,除了計算正確率方法外,我們常常會定義正類和負類,由真實類別(行名)與預測類別(列名)構成混淆矩陣。
首先直觀的來看看(混淆矩陣圖):
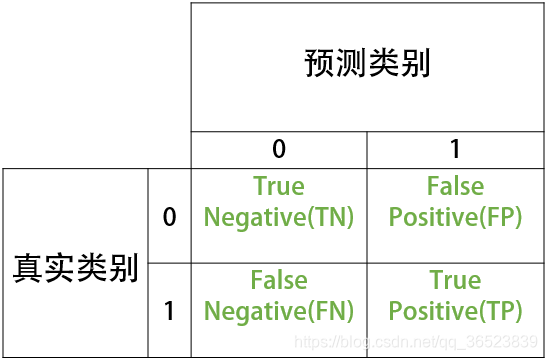
文字詳細說明:
- TN:將負類預測為負類(真負類)
- FN:將正類預測為負類(假負類)
- TP:將正類預測為正類(真正類)
- FP:將負類預測為正類(假正類)
最後根據混淆矩陣得出分類模型常用的分類評估指標:
準確率 Accuracy:
測試樣本中正確分類的樣本數佔總測試的樣本數的比例。公式如下:
scikit-learn 準確率的計算方法:sklearn.metrics.accuracy_score(y_true, y_pred)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)精確率 Precision:
準確率又叫查準率,測試樣本中正確分類為正類的樣本數佔分類為正類樣本數的比例。公式如下:
scikit-learn 精確率的計算方法:sklearn.metrics.precision_score(y_true, y_pred)
from sklearn.metrics import precision_score
precision_score(y_test, y_predict)召回率 Recall:
召回率又稱查全率,測試樣本中正確分類為正類的樣本數佔實際為正類樣本數的比例。公式如下:
scikit-learn 召回率的計算方法:sklearn.metrics.recall_score(y_true, y_pred)
from sklearn.metrics import recall_score
recall_score(y_test, y_predict)F1 值:
F1 值是查準率和召回率的加權平均數。F1 相當於精確率和召回率的綜合評價指標,對衡量資料更有利,更為常用。 公式如下:
scikit-learn F1的計算方法:sklearn.metrics.f1_score(y_true, y_pred)
from sklearn.metrics import f1_score
f1_score(y_test, y_predict)ROC 曲線:
在部分分類模型中(如:邏輯迴歸),通常會設定一個閾值如0.5,當大於0.5歸為正類,小於則歸為負類。因此,當減小閾值如0.4時,模型將會劃分更多測試樣本為正類。這樣的結果是提高了正類的分類率,但同時也會使得更多負類被錯分為正類。
在ROC 曲線中有兩個引數指標——TPR、FPR,公式如下:
TPR 代表能將正例分對的概率(召回率),而 FPR 則代表將負例錯分為正例的概率。
TPR作為ROC 曲線的縱座標,FPR作為ROC曲線的橫座標,如下圖:
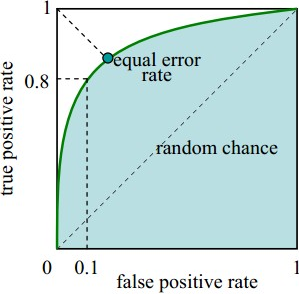
由圖可得:
-
當 FPR=0,TPR=0 時,意味著將每一個例項都預測為負例。
-
當 FPR=1,TPR=1 時,意味著將每一個例項都預測為正例。
-
當 FPR=0,TPR=1 時,意味著為最優分類器點。
所以一個優秀的分類器對應的ROC曲線應該儘量靠近左上角,越接近45度直線時效果越差。
scikit-learn ROC曲線的計算方法:sklearn.metrics.roc_curve(y_true, y_score)
AUC 值:
AUC 的全稱為 Area Under Curve,意思是曲線下面積,即 ROC 曲線下面積 。通過AUC我們能得到一個準確的數值,用來衡量分類器好壞。
-
AUC=1:最佳分類器。
-
0.5<AUC<1:分類器優於隨機猜測。
-
AUC=0.5:分類器和隨機猜測的結果接近。
-
AUC<0.5:分類器比隨機猜測的結果還差。
scikit-learn AUC的計算方法:sklearn.metrics.roc_curve(y_true, y_score)
from matplotlib import pyplot as plt
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
y_score = model.decision_function(X_test) # model訓練好的分類模型
fpr, tpr, _ = roc_curve(y_test, y_score) # 獲得FPR、TPR值
roc_auc = auc(fpr, tpr) # 計算AUC值
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend()
plt.show()