
影象檢索(6):區域性敏感索引(LSH)
影象檢索中,對一幅影象編碼後的向量的維度是很高。以VLAD為例,基於SIFT特徵點,設視覺詞彙表的大小為256,那麼一幅影象編碼後的VLAD向量的長度為128×256=32768128×256=32768。通常要對編碼後的VLAD向量進行降維,降維後的向量長度應該根據影象庫中影象量的大小來,如果只是幾百張的小的影象庫,那麼可以降維到128甚至是64維,在這種情況下降維後的VLAD向量仍然有很好的區分度;但是如果圖片庫的數量是幾千,幾萬張,如果VLAD降維的維度太低,損失的資訊過多,就不能有很好的區分度,維度過低檢索的精度就會低很多。為了保證檢索的精度,VLAD向量要有1024或者2048的維度。
以上資料是筆者經歷的專案的經驗值
,並不一定適合所有的情況。
如果是在低維度的小資料集中,可以使用線性查詢(Linear Search)的方法,但是在高緯度大資料集中,線性查詢的效率很低,顯然是不可行的。如何的從大的高維資料集中找到與某個向量最相似的一個或多個向量,是影象檢索中一個難點。
在這種高緯度大資料集中的檢索,通常需要使用最近鄰最相似查詢(Approximate Nearest Neighbor,ANN)的方法。ANN的相似性檢索演算法,大體可以分為三大類:
- 基於樹的方法,KD-樹為代表。對於低維度的資料,KD樹的查詢效能還是比較高效的;但當空間維度較高時,該方法會退化為暴力列舉,效能較差,這時一般會採用下面的雜湊方法或者向量量化方法。
- 雜湊方法
- LSH Locality Sensitive Hashing 為代表,對於小資料集和中等資料集效果不錯
- 向量量化
- vector quantization,在向量量化編碼中,關鍵是碼本的建立和碼字搜尋演算法。比如常見的聚類演算法,就是一種向量量化方法。而在相似搜尋中,向量量化方法又以PQ方法為代表
- 對於大規模資料集,向量量化是個很好的選擇
LSH
LSH(Locality Sensitive Hashing)位置敏感雜湊,區域性敏感雜湊
最近鄰最相似搜尋演算法的一種,有比較可靠的理論根據且在高維資料中表現比較好,很適合應用在影象檢索中。
與一般的雜湊演算法不同的是其位置敏感性
LSH和普通雜湊的區別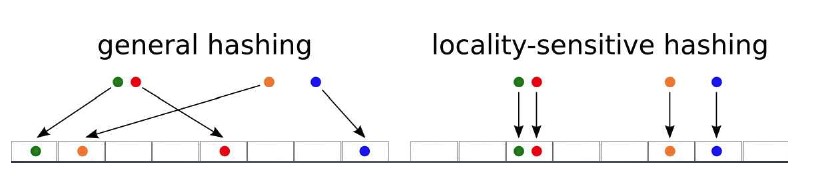
基本思想
LSH不像樹形結構的方法可以得到精確的結果,LSH所得到的是一個近似的結果,因為在很多領域中並不需非常高的精確度。即使是近似解,但有時候這個近似程度幾乎和精準解一致。
LSH的主要思想是,高維空間的兩點若距離很近,那麼設計一種雜湊函式對這兩點進行雜湊值計算,使得他們雜湊值有很大的概率是一樣的。同時若兩點之間的距離較遠,他們雜湊值相同的概率會很小。
LSH雜湊函式要滿足的性質
一個雜湊函式滿足以下性質時,被稱為(R,cR,P1,P2)(R,cR,P1,P2)-sensive,對於高維空間的任意兩點x,yx,y
- 如果d(x,y)≤Rd(x,y)≤R,則h(x)=h(y)h(x)=h(y)的概率不小於P1P1
- 如果d(x,y)≥cRd(x,y)≥cR,則h(x)=h(y)h(x)=h(y)的概率不大於P2P2
其中d(x,y)d(x,y)是兩個點x,yx,y之間的距離,hh是雜湊函式,h(x)h(x)和h(y)h(y)是對點x,yx,y的雜湊變換,並且需要滿足:
- c>1c>1
- P1>P2P1>P2
LSH的原理是挺簡單的,其核心有兩個:
- 兩個高維向量的相似性的度量
- (R,cR,P1,P2)(R,cR,P1,P2)-sensive雜湊函式的選擇
LSH的雜湊函式的選擇取決於其選擇的相似性度量方法,當然並不是所有向量相似性度量的方法都能找到相應的LSH函式,比如LSH最初提出的時候時候基於歐式距離的度量方法就沒有找到合適的LSH函式。
Origin LSH
最初設計的LSH應該是想基於歐式距離(L2L2),但是對於歐式距離當時沒有找到合適的LSH函式;但是在曼哈頓距離(L1L1)下找到了合適的LSH函式。所以,就有了一個假設,向量所在的原始空間中L1L1和L2L2度量的效果相差不大,也就是說用L1L1來代替L2L2。
所以就有兩個準則:
- 使用L1L1也就是曼哈頓距離進行度量。 基於假設L1L1和L2L2的度量效果相差不大。
- 向量的各個分量,要被正整數化,方便進行01編碼。
為什麼要進行01編碼呢,因為在L1L1的度量下也不是很容易找到合適的LSH函式,而在Hamming距離下有合適的LSH函式。最初在提出LSH的時候,使用一種方法將向量從L1L1準則下的歐幾裡空間嵌入(Embedding)到Hamming空間。
Hamming距離下的LSH
Hamming距離指的是兩個相同長度的二進位制資料中相同位置處位元位值不同的個數。 例如,8和5使用長度為4的二進位制表示分別為: 8=(1000),5=(0101)8=(1000),5=(0101),那麼8和5的Hamming距離就是:3。
假如有兩個二進位制表示的向量x,yx,y,向量的每個分量的值不是0就是1,使用Hamming距離計算這兩個向量的距離。假設有一組雜湊函式HH,其定義為:每一個雜湊函式h隨機的選擇向量特定位置的bit值返回,HH中包含了所有從{0,1}d{0,1}d對映到{0,1}{0,1}函式,其中hi(x)=xihi(x)=xi。
從HH中隨機的選擇雜湊函式hihi應用到向量xx上,則hi(x)=xihi(x)=xi,返回向量xx特定位置的bit值。那麼h(x)=h(y)h(x)=h(y)的概率就為向量x,yx,y中bit位相同的所佔的比例,即有:
P1=1−Rd,P2=1−cRdP1=1−Rd,P2=1−cRd
其中,dd為向量二進位制的長度。則對於任意的c>1c>1,都有P1>P2P1>P2,滿足以上提到的LSH函式的條件。
假設兩個點x=(1000),y=(0101)x=(1000),y=(0101),則x,yx,y的Hamming距離為3,則通過上述的雜湊函式對映後具有相同雜湊值的概率,
P(h(x)=h(y))=1−34=14P(h(x)=h(y))=1−34=14
曼哈頓距離(L1L1)轉換為Hamming距離
Hamming距離只能應用於二進位制表示的向量,這就有很大侷限性。所以Origin LSH 就提出了一種方法稱為Embedding,將向量的表示從L1L1準則下的歐幾裡空間Embedding到Hamming空間,並且保證轉換前後兩個向量的距離是不變的。
Embedding演算法:
- 找到資料集中所有向量的所有分量的最大值CC。
- 對於向量x=(x1,x2,⋯,xn)x=(x1,x2,⋯,xn),nn是向量的維度。將向量每個分量xixi轉換為長度為CC的二進位制序列,二進位制序列為前xixi個1,剩餘的為0。假設xi=5,C=10xi=5,C=10,轉換後的二進位制序列為11111000001111100000。
- 這樣一個dd維的向量就轉變為nCnC長度的二進位制串。
Embedding操作是保持距離的,轉換後兩個向量的距離是不變的。轉變為Hamming距離後,就可以利用Hamming距離下的LSH函數了
LSH的雜湊函式要滿足以下兩個條件,
- 如果d(x,y)≤Rd(x,y)≤R,則h(x)=h(y)h(x)=h(y)的概率不小於P1P1
- 如果d(x,y)≥cRd(x,y)≥cR,則h(x)=h(y)h(x)=h(y)的概率不大於P2P2
設向量的二進位制表示的長度為nCnC,如果向量x,yx,y的Hamming距離為dd,則通過上面雜湊函式的變換後,
P(h(x)=h(y))=nC−dnCP(h(x)=h(y))=nC−dnC
則有:
- 如果d(x,y)≤Rd(x,y)≤R,則h(x)=h(y)h(x)=h(y)的概率不小於P1P1,P1=nC−RnC=1−RnCP1=nC−RnC=1−RnC
- 如果d(x,y)≥cRd(x,y)≥cR,則h(x)=h(y)h(x)=h(y)的概率不大於P2P2,P2=nC−cRnC=1−cRnCP2=nC−cRnC=1−cRnC
向量的Hamming距離和其對映後相等的概率之間的關係如下圖:
當兩個向量的Hamming距離為0,對映後其相等的概率為1;兩個向量的二進位制完全不同,Hamming距離為nCnC則其對映後相同的概率為0。
LSH引數
再來回顧下LSH的思想:在原空間中很近(相似)的兩個點,經過LSH雜湊函式的對映後,有很大概率它們的雜湊是一樣的;而兩個離的很遠(不相似)的兩個點,對映後,它們的雜湊值相等的概率很小。
從上面這句話可以看出LSH需要的四個引數:
- 原空間中兩向量的距離RR
在原空間中,如果兩個向量的距離小於RR,表示這兩個向量相似,經過對映後,其雜湊值有有很大的概率是相同的。 - 相似的向量對映後雜湊值相等的概率P1P1
- 常數cc
在原空間中,如果兩個向量的距離大於cRcR,表示這兩個向量不相似,經過對映後,其雜湊值相等的概率很小 - 不相似的向量對映後雜湊值的概率相等的概率P2P2
也就是說,對於任意向量x,yx,y,如果在原空間中其距離d(x,y)≤Rd(x,y)≤R,則認為其是相似的。經過LSH雜湊函式對映後,其雜湊值相等的概率很大(P1P1);而對於在原空間中距離d(x,y)≥cRd(x,y)≥cR,則認為其是不相似的,經過LSH雜湊函式對映後u,其雜湊值相等的概率很小(P2P2)。
對於Origin LSH 已Hamming距離來度量向量的相似性來說,概率
P1=nC−RnC=1−RnCP2=nC−cRnC=1−cRnCP1=nC−RnC=1−RnCP2=nC−cRnC=1−cRnC
P1,P2P1,P2可以通過上述公式求得,也就是說,只需要指定兩個引數
- 向量相似的距離RR
- 常數c(c>1)c(c>1),向量大於距離cRcR則表示不相似
概率增大
LSH的核心思想是,通過雜湊變換後,變換前相似的向量在變換後有很大的概率(P1P1)雜湊值是相同的;不相似的呢,其雜湊值只有很小的概率(P2P2)是相同的。這樣,兩個概率P1,P2P1,P2就是影響LSH檢索的關鍵。理想的情況下,是相似的向量,其雜湊值相同的概率是P1=1P1=1;不相似的向量,其雜湊值相同的概率P2=0P2=0。 理想情況畢竟是理想嘛,面對實際問題還是要現實一點的,對於P1,P2P1,P2的關係:P1P1儘可能的大,P2P2較小,P1,P2P1,P2有足夠大的間隔。
通過上面的分析知道,P1,P2P1,P2可以通過設定較大的相似距離RR和一個小的常數cc,來保證P1,P2P1,P2有足夠大的間隔。在極端情況下,可以設定相似距離RR等於二進位制串的長度nCnC,這樣只有兩個向量二進位制串是完全相同情況下,P1=1P1=1。 但這會導致相似檢索的精度變的不那麼可靠,對資料的噪聲比較敏感。
所以對於指定了相似距離RR以及常數cc來說,可能其P1,P2P1,P2之間的間隔不是足夠的大,可以使用增加雜湊鍵長度KK以及雜湊表的個數LL來增大P1,P2P1,P2之間的差。
增加雜湊表個數LL和雜湊鍵長KK實際上是不同雜湊函式的組合。
-
增加雜湊鍵長KK
設hihi是雜湊函式簇HH中的任意函式,對於任意向量p,qp,q滿足P(hi(p)=hi(q))=P1P(hi(p)=hi(q))=P1
從HH中隨機的挑選KK個雜湊函式將向量對映為KK長度的串,g(p)=[h1(p),h2(p),⋯,hk(p)]g(p)=[h1(p),h2(p),⋯,hk(p)] 則有:P(g(p)=g(q))=P(h1(p)=h1(q))⋅P(h2(p)=h2(q))⋯P(hk(p)=hk(q))=PK1P(g(p)=g(q))=P(h1(p)=h1(q))⋅P(h2(p)=h2(q))⋯P(hk(p)=hk(q))=P1K
由於0<P1<10<P1<1,則PK1<P1P1K<P1,也就是說縮小了概率。 -
增加雜湊表LL
設現在有LL個雜湊表(也就是LL個雜湊函式簇HH),每個雜湊表都使用上面的方法產生一個組合的雜湊函式gg,
這樣可以得到LL個雜湊函式g1,g2,⋯,glg1,g2,⋯,gl,將這幾個組合的雜湊函式再組合到一起得到雜湊函式GG。G=[g1(p),g2(p),⋯,gl(p)]G=[g1(p),g2(p),⋯,gl(p)]
由於使用一個雜湊表找到最近鄰的概率為PK1P1K,招不到最相似的概率是1−PK11−P1K。那麼使用LL個雜湊表找到最相似的概率
P(G(p)=G(q))=1−[1−P(g1(p)=g2(q))⋯P(gl(p)=gl(q))]=1−(1−pk1)lP(G(p)=G(q))=1−[1−P(g1(p)=g2(q))⋯P(gl(p)=gl(q))]=1−(1−p1k)l
上面公式給出了,使用LL個雜湊表,KK個雜湊函式的情況下,查詢到最近鄰的概率P=1−(1−Pk1)lP=1−(1−P1k)l,下表給出了K=4,L=4K=4,L=4的情況下,查詢到最相似向量的概率
| P1P1 | 1−(1−P41)41−(1−P14)4 |
|---|---|
| 0.9 | 0.9860 |
| 0.8 | 0.8785 |
| 0.7 | 0.6666 |
| 0.5 | 0.2275 |
| 0.4 | 0.0985 |
| 0.3 | 0.0320 |
| 0.2 | 0.0064 |
LSH 編碼例項
下面看一個例項,假設有資料集合中有6個點:
A=(1,1) B=(2,1) C=(1,2)
D=(2,2) E=(4,2) F=(4,3)
首先進行Embedding操作點表示為二進位制串,上述座標的最大值為4,所以C=4C=4,維度為2,則n=2n=2,所以二進位制串的長度為8.
v(A)=10001000
v(B)=11001000
v(C)=10001100
v(D)=11001100
v(E)=11111100
v(F)=11111110
採用K=2,L=3K=2,L=3的雜湊函式組合,G=[g1,g2,g3]G=[g1,g2,g3],其中gi=[h1,h2]gi=[h1,h2]。
假設隨機選擇的雜湊函式組合如下:
- g1g1分別取第2位,第4位,也就是h1(p)=p2,h2(p)=p4h1(p)=p2,h2(p)=p4
- g2g2分別取第1位,第6位,也就是h1(p)=p1,h2(p)=p6h1(p)=p1,h2(p)=p6
- g3g3分別取第3位,第8位,也就是h1(p)=p3,h2(p)=p8h1(p)=p3,h2(p)=p8
利用上面的雜湊函式將6個點對映到三個雜湊表中,結果如下: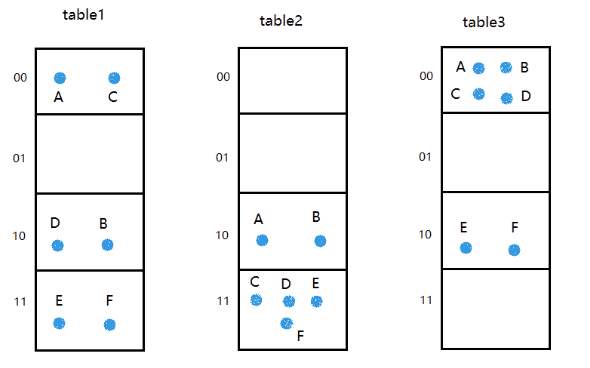
設查詢向量q=(4,4)=(11111111)q=(4,4)=(11111111),可以計算出
g1(q)=[11]g2(q)=[11]g3(q)=[11]g1(q)=[11]g2(q)=[11]g3(q)=[11]
將上面3個雜湊表中對映到[11][11]號的向量取出來為(C,D,E,F)(C,D,E,F),接下來將這四個向量分別與qq計算距離,距離最近的向量,即為最相似的向量,也就是向量F=(4,3)F=(4,3)。
上述例子引用自區域性敏感雜湊深度解析
LSH的檢索過程
從上面的例子中可以總結處LSH檢索過程。
- 離線建立索引
- 選擇滿足(R,cR,P1,P2)(R,cR,P1,P2)-sensive的雜湊函式
- 根據對查詢結果的準確率(即相鄰的資料被查詢到的概率)確定雜湊表的個數LL,每個table內的hash functions的個數,也就雜湊的鍵長KK,以及跟LSH hash function自身有關的引數
- 利用上面的雜湊函式組,將集合中的所有資料對映到一個或多個雜湊表中,完成索引的建立。
- 線上的查詢
- 將查詢向量qq通過雜湊函式對映,得到相應雜湊表中的編號
- 將所有雜湊表中相應的編號的向量取出來,為了保證查詢速度,通常只需要取出來前2L2L個。
- 對這2L2L個向量進行線性查詢,返回與查詢向量最相似的向量。
總結
在做影象檢索時,搜尋資料發現使用KD樹做索引效果不是很好,由於使用的是OpenCV的庫,就像改為使用LSH的索引,但是OpenCV整合的LSH只支援整型的,而且對其中一些引數的設定不是很明白,蒐集了些資料,形成了該篇文章。
蒐集資料的過程才發現雜湊函式的應用之廣泛,就LSH這個點來說,蒐集資料形成的本篇文章也也只是冰山一角,奈何沒有太多的精力,目前僅止於瞭解。
相似性度量及LSH雜湊函式
可以使用不同的方法來度量兩個點的相似性,針對不同的度量方法,在進行區域性雜湊時使用的雜湊函式也是不同的。
兩個向量的相似性度量的方式很多,這裡僅列舉幾個在計算機視覺中常用的幾個度量方法,當然並不是所有的度量方式都能夠找到相應的LSH雜湊函式。例如,在LSH最初提出的時候,就沒有找到基於歐式距離的LSH函式。
Hamming距離的LSH雜湊函式
這也是Origin LSH,本文描述使用的距離度量。
在對影象進行匹配時,通常是將影象的描述子與資料中的影象描述子進行匹配實現的。在實時應用中,通常是使用二進位制描述子,比如BIREF、BRISK、ORB等。對於二進位制描述子使用的是Hamming距離。
對於二進位制描述子,雜湊函式就是直接選擇描述子的某一個位元位,通過若干個雜湊函式選擇出來的位的級聯,就形成了一個雜湊鍵了。通過對這個雜湊鍵對資料庫中的描述子進行索引,即形成了一個雜湊表,選擇若干個雜湊表來增大找到近似最近鄰的概率。
Hamming距離指的是兩個具有相同長度的向量中對應位置處值不同的次數。
Hamming距離的LSH雜湊上面已經有描述,這裡不再重複。
向量的夾角餘弦的LSH雜湊函式
用兩個向量的夾角來衡量兩個向量是不是相似,向量的夾角越小,表示它們越相似。
向量夾角的計算公式
cos(θ)=x⋅y∥x∥⋅∥y∥cos(θ)=x⋅y‖x‖⋅‖y‖
其中,∥⋅∥‖⋅‖表示向量的L2−normL2−norm.
例如,兩個向量x=(1,2,−1),y=(2,1,1)x=(1,2,−1),y=(2,1,1),則有
cos(θ)=1×2+2×1+(−1)×16–√⋅6–√=12cos(θ)=1×2+2×1+(−1)×16⋅6=12
cos(θ)cos(θ)的取值範圍是[0,π][0,π],僅在兩個相同的方向相同時,其夾角的餘弦值為0;當兩個向量的方向相反時,其 夾角的餘弦值為ππ。
適應向量的夾角餘弦度量,對應的LSH hash function為:H(V)=sign(V⋅R)H(V)=sign(V·R),RR是一個隨機向量。V⋅RV·R可以看做是將VV向RR上進行投影操作,其是(d1,d2,(180−d1)180,(180−d2)/180)(d1,d2,(180−d1)180,(180−d2)/180)-sensitive的。
歐氏距離的LSH雜湊
兩個向量相似性度量,歐氏距離應該是比較常用的方法,但是在LSH才提出的時候,在歐氏距離下並沒有找到合適的LSH函式。
關於更多E2LSH的資訊可參考http://www.mit.edu/~andoni/LSH/
來源:https://www.cnblogs.com/wangguchangqing/p/9796226.html