影象檢索入門:CVPR2016《Deep Supervised Hashing for Fast Image Retrieval》
TensorFlow程式碼:馬上新增
-
研究背景
在使用離散化時希望輸出的特徵的關於某個值對稱,所以如《Deep Learning of Binary Hash Codes for Fast Image Retrieval》用了 sigmoid 作為特徵層的輸出的啟用函式,但直接引用 sigmoid 這種非線性函式將不可避免地減慢甚至抑制網路的收斂。解決該問題就是使用正則的方法將輸出約束到某一個範圍內。
-
研究方法
本文設計了一個新的CNN模型,不是使用單張圖片進行訓練,而是通過輸入成對影象(我們線上的生成影象對,以便在訓練階段可以使用更多的影象對)和影象對應的標籤來進行訓練,輸出是這對影象的Hash值,並設計損失函式用於將相似影象的網路輸出拉到一起,並將不相似影象的輸出推送到很遠的位置,以使得學習到的漢明空間可以很好地逼近影象的語義結構。具體過程如下:
1.設定最後一層全連線層節點數為12,將訓練資料輸入到網路(如下圖所示)中進行預訓練,得到對應資料的12位Hash值;
2.設定最後一層全連線層節點數為24/36/48,利用上一步得到的權重微調,得到對應資料的24/36/48位Hash值;
3.根據得到的Hash值進行影象檢索。
為了避免優化海明空間中的不可微的損失函式,網路輸出放寬到實值,同時強制正則化器來使實值輸出逼近期望的離散值。

1.網路設定
本文的網路模型設定為3個卷積層(卷積層+池化層)和2個全連線層,具體如上圖所示:
conv1:卷積核為5*5*32,步數為1
max_pooling1:卷積核為3*3*32,步數為2
conv2:卷積核為5*5*32,步數為1
average_pooling2:卷積核為3*3*32,步數為2
conv3:卷積核為5*5*64,步數為1
average_pooling3:卷積核為3*3*64,步數為2
fc1:500個節點
fc2:k個節點(Hash值位數)
2.損失函式
初步設計
利用將相似影象的程式碼拉到一起,並且將不相似影象的程式碼彼此分開的思想,損失函式定義如下:
- 輸入的影象對
,經過網路模型後得到對應的Hash值
,
定義為該影象對
- 對於只有單標籤的影象,若該影象對
;若該影象對
的標籤不同,表示他們是不相似的並定義;
- 對於多標籤的影象,若該影象對
表示在
表示在
同時得到整體損失函式的矩陣表達形式:
鬆弛
我們的目標就是最小化損失函式,但是對於上面的約束和其他論文的hashcode約束一樣,都是二值的,離散的,不可導。所以在訓練的時候,不好反向傳播誤差。因此將損失函式更改為如下形式:
表示逐元素絕對值運算,α是控制正則化器強度的加權引數;
- 將原來的約束條件
更改為
;
表示L2距離,本文使用L2範數來測量Hash值之間的距離,因為由低階範數產生的子梯度同等地處理具有不同距離的影象對,因此不使用不同距離量級中涉及的資訊。 雖然高階規範也是可行的,但同時會產生更多的計算;
表示L1正則,對於正則化器,選擇L1範數而不是高階規範,因為其計算成本要低得多,這可以有利地加速訓練過程。
同時得到整體損失函式的矩陣表達形式:
3.模型訓練
本文使用資料集Cifar10(單標籤)和NUS-WIDE(多標籤),本文主要使用兩種方式來進行訓練網路:
線上生成影象對
為了更好地利用計算資源和儲存空間,本文通過利用每個小批量中的所有資料集來線上生成影象對。 為了覆蓋批次中的那些影象對,在每次迭代中,從整個訓練集中隨機選擇訓練影象。 通過這樣做,我們的方法減少了儲存整個成對相似性矩陣的需要,因此可以擴充套件到大規模資料集。
預訓練
先在輸出層節點數為12的網路中進行預訓練,再使用學習到的引數微調輸出層節點數為24/36/48的網路。
4.影象檢索
待檢測的影象通過訓練的模型得到對應的Hash值,根據Hash值計算該影象和資料庫中影象的漢明距離,距離越小表示兩影象越相似,否則越不相似。
-
實驗結果
正則引數實驗
在Hahs值位數k = 12基礎上實驗,可以看出當和
時mAP最高。
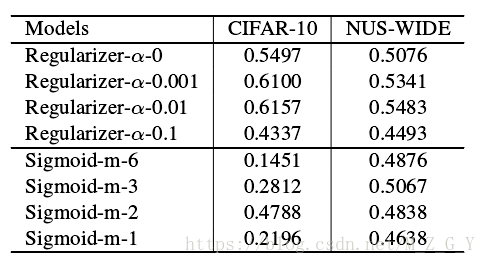
預訓練實驗
在和
前提下,預訓練可以有效的防止過擬合。


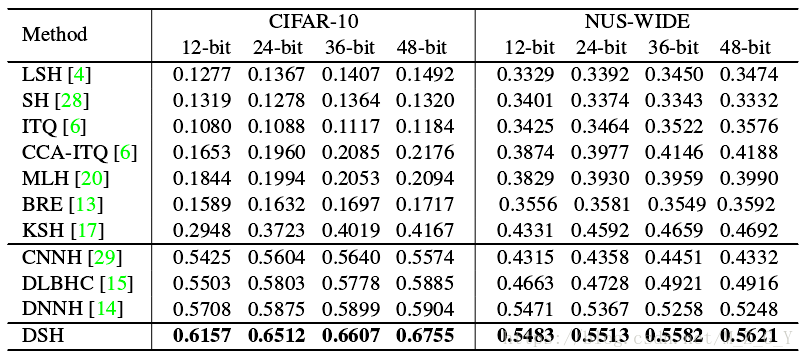
和其他實驗比較