
爬取新浪新聞
通過scrapy startproject xinlang爬蟲專案:
通過scrapy genspider sina "sina.com.cn" 建立spider
建立Items
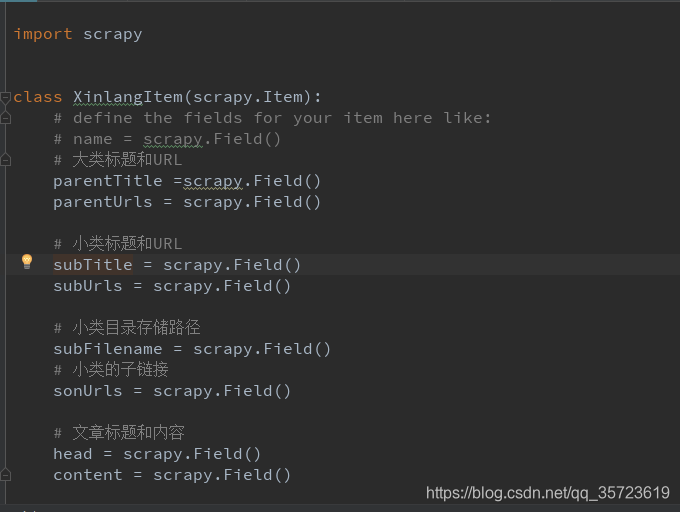
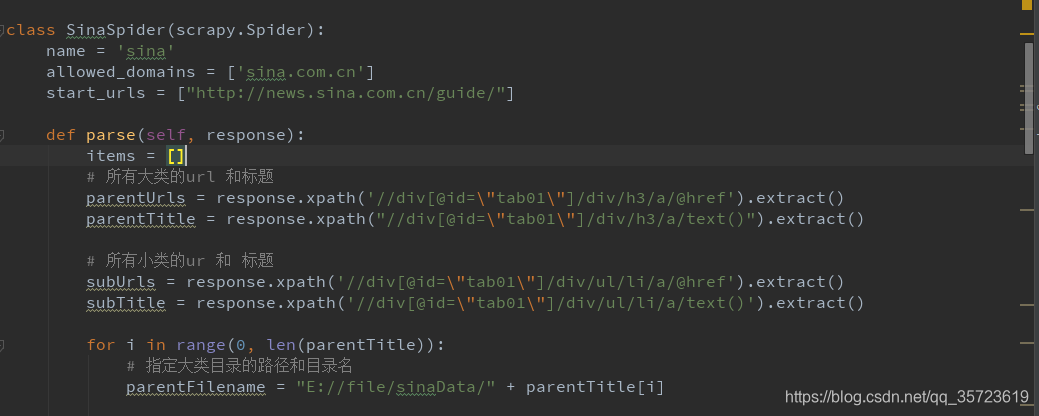
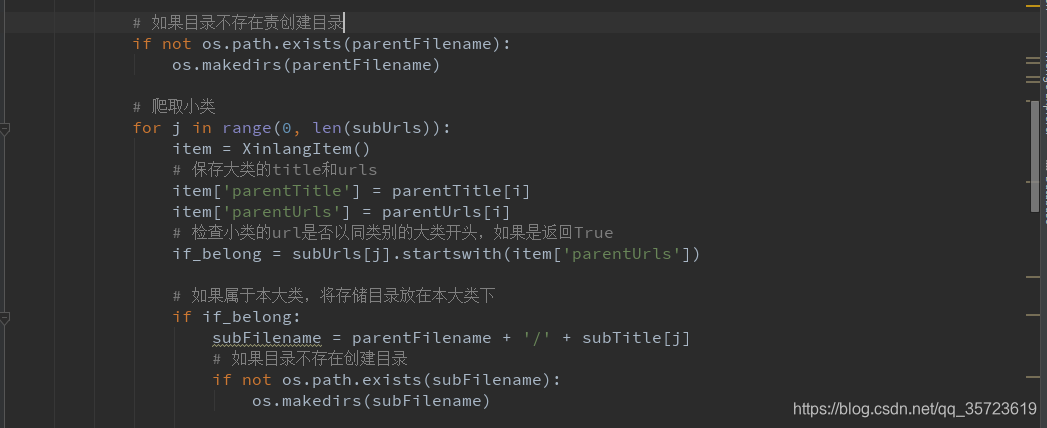
spider:

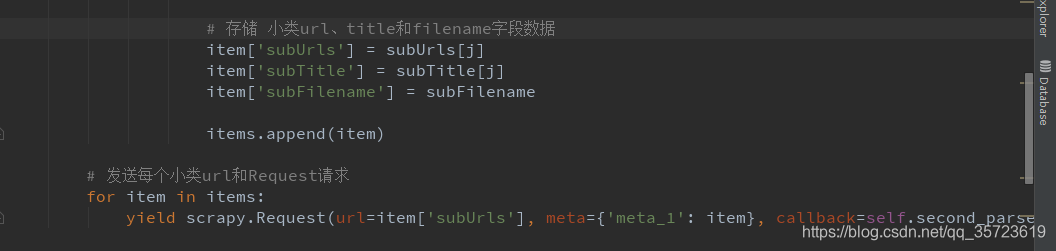
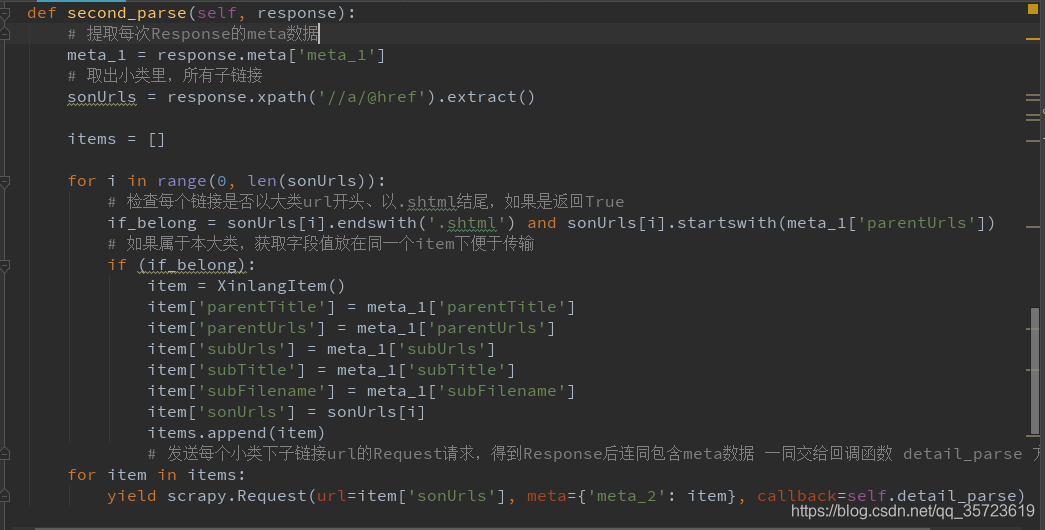
pipelines:
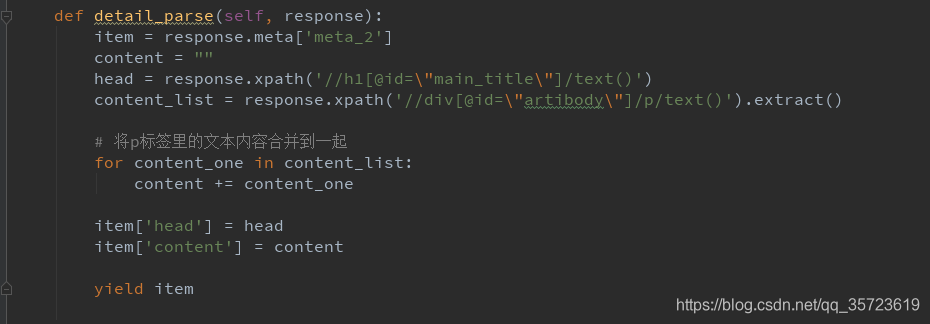
setting檔案設定:

執行結果:
檔案原始碼:
https://download.csdn.net/download/qq_35723619/10764923
相關推薦
requests, Beautifusoup 爬取新浪新聞資訊
int 爬取 eight tex import soup imp encoding 資訊 import requestsfrom bs4 import BeautifulSoupres = requests.get(‘http://news.sina.com.cn/chin
Python 爬蟲實例(7)—— 爬取 新浪軍事新聞
secure host agen cat hand .com cati ica sts 我們打開新浪新聞,看到頁面如下,首先去爬取一級 url,圖片中藍色圓圈部分 第二zh張圖片,顯示需要分頁,
4-15 爬取新浪網
xlsx size text num mos das rip bs4 page import requests 3 from bs4 import BeautifulSoup 4 from datetime import datetime 5 import re 6
python 爬取新浪網站 NBA球員最近2個賽季庫裡前20場資料
1. 分析新浪網站中球員資料的獲取方式(F12 開發者模式,除錯網頁): 一般網站儲存資料的方式分為2種:1. 靜態網頁儲存;2. 動態請求; 對於靜態網頁儲存來說,就是開啟瀏覽器中檢視原始碼,就可以從原始碼中獲取所需要的資料; 對於動態請求來說,採用F12的開發者模式中,才能從伺服器的
python爬蟲爬取新浪新聞的評論數以及部分評論
首先應該去找到評論數所對應的網頁元素: 可以大致猜測,這裡是用JavaScript·去計算評論數量的。 重新整理頁面,去觀測頁面的js部分,有沒有對應的連結,仔細檢視: 找到之後,點選Preview,看到內部結構: 可以看出count部分,total代表了參與人數,show欄位代
爬取新浪新聞
通過scrapy startproject xinlang爬蟲專案: 通過scrapy genspider sina "sina.com.cn" 建立spider 建立Items spider: pipelines:
【轉】寫一個簡單的爬蟲來批量爬取新浪網的新聞
工具:Anaconda 先進入該頁,新浪新聞:http://news.sina.com.cn/china/ 往下翻,找到這樣的最新訊息 先爬取單個頁面的資訊:(隨便點一個進去), 該新聞網址:http://news.sina.com.cn/c/nd/2018-06-08/doc-ihcscwxa1
Webdriver 爬取新浪滾動新聞
Webdriver 爬取新浪滾動新聞 初始想法 本人現在是國際關係學院2016級的本科生,學的是資訊管理與資訊系統。講道理不知道這個專業到底是幹啥的,現在選擇的後續方向是資料科學與工程,並且在老師的自然語言處理小組。爬蟲是做自然語言處理的基礎嘛,學習機器學習之前先學學怎麼爬取內容還是
Python爬取新浪微博用戶信息及內容
pro 目標 oss 來源 但是 blog .com 交流 exc 新浪微博作為新時代火爆的新媒體社交平臺,擁有許多用戶行為及商戶數據,因此需要研究人員都想要得到新浪微博數據,But新浪微博數據量極大,獲取的最好方法無疑就是使用Python爬蟲來得到。網上有一些關於使用Py
python:爬取新浪新聞的內容
import requests import json from bs4 import BeautifulSoup import re import pandas import sqlite3 commenturl='https://comment.sina.com.cn/page/info?
selenium爬取新浪滾動新聞新聞
selenium安裝方法 pip3 install selenium chromedriver安裝方法 chromedriver版本 支援的Chrome版本 v2.41 v67-69 v2.40 v66-68 v2.39 v66-68
python爬取新浪股票資料—繪圖【原創分享】
目標:不做蠟燭圖,只用折線圖繪圖,繪出四條線之間的關係。 注:未使用介面,僅爬蟲學習,不做任何違法操作。 1 """ 2 新浪財經,爬取歷史股票資料 3 """ 4 5 # -*- coding:utf-8 -*- 6 7 import num
關於爬取新浪微博,記憶體耗用過高的問題
最近在做網際網路輿情分析時,需要爬取新浪微博做相關實驗。雖然新浪微博開放了相關輿論的API,然而申請什麼的,並不想做,而且輿情變化快,最終還是自己爬取,相關輿情。 在用selenium的時候,有時候經常發現記憶體耗
scrapy爬取新浪微博並存入MongoDB中
spider.pyimport json from scrapy import Request, Spider from weibo.items import * class WeiboSpider(Spider): name = 'weibocn'
python3[爬蟲實戰] 爬蟲之requests爬取新浪微博京東客服
爬取的內容為京東客服的微博及評論 思路:主要是通過手機端訪問新浪微博的api介面,然後進行資料的篩選, 這個主要是登陸上去的微博的url連結, 可以看到的介面: 這裡主要爬取的內容為: 說說,說說下面的評論條目 雖然很簡單,但是,不得不說句mmp,爬
用python寫網路爬蟲-爬取新浪微博評論
新浪微博需要登入才能爬取,這裡使用m.weibo.cn這個移動端網站即可實現簡化操作,用這個訪問可以直接得到的微博id。 分析新浪微博的評論獲取方式得知,其採用動態載入。所以使用json模組解析json程式碼 單獨編寫了字元優化函式,解決微博評論中的嘈雜干擾
70行python程式碼爬取新浪財經中股票歷史成交明細
最近在研究股票量化,想從每筆成交的明細著手,但歷史資料的獲取便是一個大問題,一些股票證券軟體又不能批量匯出成交資料。所以,我花了兩天時間,成功的從新浪財經爬取了我要的資料 下面開始 新浪股票明細資料介面為 格式不用多說symbol=股票程式碼 date=日期 pa
用網路爬蟲爬取新浪新聞----Python網路爬蟲實戰學習筆記
今天學完了網易雲課堂上Python網路爬蟲實戰的全部課程,特在此記錄一下學習的過程中遇到的問題和學習收穫。 我們要爬取的網站是新浪新聞的國內版首頁 下面依次編寫各個功能模組 1.得到某新聞頁面下的評論數 評論數的資料是個動態內容,應該是存在伺服器
爬蟲爬取新浪微博
這周的第一個小任務:爬取動態網頁,拿新浪微博做例子,我爬取了指定使用者微博的基本資訊,包括暱稱,性別,粉絲數,關注人數和主頁地址,還有發過的所有微博的地址和資訊內容,如果轉發時沒有說任何內容的話只會顯示轉發了微博。 需要注意的是網頁版資訊量太大,用手機端的也就
Python利用xpath和正則re爬取新浪新聞
今天我們來進行簡單的網路爬蟲講解:利用用from lxml import html庫+Xpath以及requests庫進行爬蟲 1.我們將爬取新浪微博首頁要聞 我們摁F12檢視網頁原始碼查詢要聞內容所對應的HTML的程式碼 通過觀察我們可以發現每個標題都在<h1 data-client