通俗理解神經網路的對抗攻擊及keras程式碼例項
上一篇轉載的博文《神經網路中的對抗攻擊與對抗樣本》幫助我理解了神經網路學習的本質,以及對抗攻擊的來龍去脈。接下來在這篇文章:《忽悠神經網路指南:教你如何把深度學習模型騙得七葷八素》中進一步理解了神經網路中白箱攻擊,本博文擬在加深學習印象,並結合自己的一些理解對該文章將的一些內容做一個重梳理。
因為本人也處於學習階段,博文中因考慮不全面或有欠缺的地方歡迎交流指正。
為什麼要進行對抗攻擊研究
未來我們的社會必定是一個自動化的環境,比如智慧家居,智慧安防,自動駕駛等,很多的崗位通過一個感測器,攝像頭、掃描器就可以直接完成,而不需要人來干預。神經網路技術目前在佔據重要的地位,如果目標檢測,人臉識別中。如果有不懷好心之人入侵你的系統中,利用神經網路的特點,將非法的輸入進行一些偽裝,從而騙過網路得到被網路認為是合法的輸出,那帶來的損失和危害也會是巨大的。
比如在以下場景中:
-
欺騙自動駕駛汽車使其認為看到的“停車”路標是一個綠燈——這可以引起車禍!
-
欺騙內容過濾系統使其無法識別出具有攻擊性的和非法的資訊。
-
欺騙ATM支票掃描系統使其錯誤的識別支票上面的實際金額資訊。(如果你被抓到的話還可以很合理的推卸掉自己的罪責!)
現在知名國際比賽NIPS中就有一個賽道是專門針對這種對抗性模型分類研究的,所以神經網路的對抗性研究至關重要。
神經網路的不穩定性
神經網路為什麼為什麼能取得很大的成功,除去它是擬在模仿人腦神經元工作這個酷炫的外衣外,對分類任務來講,本質也就是經過常見的線性變換、拉伸、旋轉將低維資料投影到高維空間,繼而凸顯放大了不同樣本之間的差異,也就是說學習到了資料的分佈特徵。
卷積神經網路(CNN)在2014年的ImageNet影象分類任務中大放異彩,如今被工業界廣泛使用。然而,一張影象的分類結果實際上是通過網路各個卷積層的權重值共同作用,因為有這麼多的值共同作用,所以一點點的改變可能對輸出結果影響不大,然而從全域性的思想來看,如果我們知道了影響輸出結果的那個閾值,進而通過對輸入影象的某些地方做一點點的改變,那麼引導一個錯誤的輸出就將會是一件很容易的事情了。所以說神經網路是可以被忽悠的,由此就有了神經網路中的對抗攻擊研究。
另一方面,我的研究課題是SAR影像的海冰分類(不同海冰型別在影象中很難辨識,而且有一個分類樣本兩種冰型共存現象),CNN網路作為我實驗的分類方法,我發現同樣的網路結構如果訓練多次就可以得到多個模型,每一次的網路的分類效能是一樣的,但是對同一張分類樣本的輸出結果(比如分類概率值)有時候區別還挺大。起初我總結這種現象是因為CNN進行優化器訓練方式的原因,每次尋找最優解的方向不同,所以得到的網路引數也會稍微不同。現在來看,可能神經網路學習本身就帶有了一種不穩定性,而我們的研究者也很早就針對這種現象進行了對抗攻擊研究,不得不讓人佩服他們的洞察能力。
如何欺騙一個分類器
機器學習分類器的工作原理就是找到一條區分事物之間的分界線。 以下圖示是一個簡單的二維分類器,它學習的目標是將綠球(合規)與紅球(違規)區分開來:

現在,分類器的精度達到100%。它找到了一條可以將所有的綠球與紅球完美分開的區隔線。但是,如果我們想要調整一下模型使得一個紅球被故意區分成綠球呢?我們最少要將紅球移動多少才會使得它被推到綠球的判定區域呢?
如果我們把分界線旁邊那個紅球的Y值少量增加,那麼我們就幾乎可以把它推到綠球的判定區域了:

所以要想欺騙一個分類器,我們只需要知道從哪個方向來推動這個點可以使它越過區隔線即可。如果我們不想使這個錯誤過於明顯,理想情況下我們會使這個移動儘可能的小,以至於其看起來就像是一個無心之過。
在使用深層神經網路進行影象分類時,我們分類的每個“點”其實是由成千上萬個畫素組成的完整影象。這就給了我們成千上萬個可以通過微調來使預測結果跨過決策線的可能值。如果我們可以確保自己對影象中畫素點的調整不是肉眼可見般的明顯,我們就可以做到在愚弄分類器的同時又不會使影象看起來是被人為篡改過的。
換句話說,我們可以選取一張真實物品的影象,通過對特定畫素點做出非常輕微地修改使得影象被神經網路完全識別為另一件物品—而且我們可以精準地控制這個替代品是什麼:

把一隻貓變成烤麵包機。影象檢測結果來自與Keras.js的Web演示:https://transcranial.github.io/keras-js/#/inception-v3
神經網路的白箱攻擊
白箱攻擊是指我們提前知道了分類網路的結構和引數,然後有針對性的對輸入影象畫素做一些小的調整,調整前後的影象對人的肉眼來說沒有區別,但是卻能得到一個與原本分類不同的、有引導性的網路輸出結果。
訓練神經網路以分類照片的基本過程:
- 新增一張訓練用圖片;
- 檢視神經網路的預測結果,看看其距離正確答案有多遠;
- 使用反向傳播演算法來調整神經網路中每一層的權重,使預測結果更接近於正確答案。
- 在數千張不同的訓練照片上重複步驟1-3。
相比於調整神經網路每一層的權重,如果我們直接修改輸入影象本身直到得到我們想要的答案為止呢?比如選用了已經訓練好的神經網路,並再次“訓練”它,不過這次我們將使用反向傳播演算法來直接調整輸入影象而不是神經網路層的權重:

新的演算法流程:
- 新增一張我們想要“黑”的照片。
- 檢查神經網路的預測結果,看看其距離我們想要的答案有多遠。
- 使用反向傳播演算法來調整照片本身,使預測結果更接近於我們想要的答案。
- 使用相同的照片重複步驟1-3上千次,直到神經網路輸出結果為我們想要的答案為止。
在此之後,我們將會得到一張可以欺騙神經網路的圖片,同時並不改變神經網路本身。就生成了一張白盒攻擊影象。
這樣做存在一個問題:由於演算法在調整上沒有任何限制,允許以任何尺度來調整任何畫素點,所以影象的最終更改結果可能會大到顯而易見:他們會出現變色光斑或者變形波浪區域。

一張被“黑”過的照片,由於沒有對畫素點可被調整的尺度做約束,你可以看到貓周圍有了綠色光斑和白色牆壁上出現的波浪形圖案。
為了防止這些明顯的圖形失真,我們可以將演算法加上一個簡單的限定條件。我們限定篡改的圖片中每一個畫素在原始的基礎上的變化幅度取一個微量值,譬如0.01%。這就使演算法在微調圖片的時候仍然能夠騙過神經網路卻不會與原始圖片差別太大。
在加入限定後重新生成的圖片如下:

在每個畫素只能在一定範圍內變化的限制條件下生成的被“黑”的圖片。即使這張圖對人眼來說篡改後沒有區別,卻可以騙過神經網路!
keras程式碼例項
理論和實踐總是要結合在一起的,此部分內容全部來自文章開頭講的對那篇忽悠神經網路指南,原作者給了用keras框架實現的程式碼。在這裡一併貼出。
原始影象的預測程式碼:
(原始碼地址:https://gist.github.com/ageitgey/8a010ee99f55fe2ef93cae7d02e170e8#file-predict-py)
import numpy as np
from keras.preprocessing import image
from keras.applications import inception_v3
# Load pre-trained image recognition model
model = inception_v3.InceptionV3()
# Load the image file and convert it to a numpy array
img = image.load_img("cat.png", target_size=(299, 299))
input_image = image.img_to_array(img)
# Scale the image so all pixel intensities are between [-1, 1] as the model expects
input_image /= 255.
input_image -= 0.5
input_image *= 2.
# Add a 4th dimension for batch size (as Keras expects)
input_image = np.expand_dims(input_image, axis=0)
# Run the image through the neural network
predictions = model.predict(input_image)
# Convert the predictions into text and print them
predicted_classes = inception_v3.decode_predictions(predictions, top=1)
imagenet_id, name, confidence = predicted_classes[0][0]
print("This is a {} with {:.4}% confidence!".format(name, confidence * 100))篡改一下圖片直到能夠騙過這個神經網路讓它認為圖片是一個烤麵包機。
原作者程式碼地址:https://gist.github.com/ageitgey/873e74b7f3a75b435dcab1dcf4a88131#file-generated_hacked_image-py
import numpy as np
from keras.preprocessing import image
from keras.applications import inception_v3
from keras import backend as K
from PIL import Image
# Load pre-trained image recognition model
model = inception_v3.InceptionV3()
# Grab a reference to the first and last layer of the neural net
model_input_layer = model.layers[0].input
model_output_layer = model.layers[-1].output
# Choose an ImageNet object to fake
# The list of classes is available here: https://gist.github.com/ageitgey/4e1342c10a71981d0b491e1b8227328b
# Class #859 is "toaster"
object_type_to_fake = 859
# Load the image to hack
img = image.load_img("cat2.png", target_size=(299, 299))
original_image = image.img_to_array(img)
# Scale the image so all pixel intensities are between [-1, 1] as the model expects
original_image /= 255.
original_image -= 0.5
original_image *= 2.
# Add a 4th dimension for batch size (as Keras expects)
original_image = np.expand_dims(original_image, axis=0)
# Pre-calculate the maximum change we will allow to the image
# We'll make sure our hacked image never goes past this so it doesn't look funny.
# A larger number produces an image faster but risks more distortion.
max_change_above = original_image + 0.01
max_change_below = original_image - 0.01
# Create a copy of the input image to hack on
hacked_image = np.copy(original_image)
# How much to update the hacked image in each iteration
learning_rate = 0.1
# Define the cost function.
# Our 'cost' will be the likelihood out image is the target class according to the pre-trained model
cost_function = model_output_layer[0, object_type_to_fake]
# We'll ask Keras to calculate the gradient based on the input image and the currently predicted class
# In this case, referring to "model_input_layer" will give us back image we are hacking.
gradient_function = K.gradients(cost_function, model_input_layer)[0]
# Create a Keras function that we can call to calculate the current cost and gradient
grab_cost_and_gradients_from_model = K.function([model_input_layer, K.learning_phase()], [cost_function, gradient_function])
cost = 0.0
# In a loop, keep adjusting the hacked image slightly so that it tricks the model more and more
# until it gets to at least 80% confidence
while cost < 0.80:
# Check how close the image is to our target class and grab the gradients we
# can use to push it one more step in that direction.
# Note: It's really important to pass in '0' for the Keras learning mode here!
# Keras layers behave differently in prediction vs. train modes!
cost, gradients = grab_cost_and_gradients_from_model([hacked_image, 0])
# Move the hacked image one step further towards fooling the model
hacked_image += gradients * learning_rate
# Ensure that the image doesn't ever change too much to either look funny or to become an invalid image
hacked_image = np.clip(hacked_image, max_change_below, max_change_above)
hacked_image = np.clip(hacked_image, -1.0, 1.0)
print("Model's predicted likelihood that the image is a toaster: {:.8}%".format(cost * 100))
# De-scale the image's pixels from [-1, 1] back to the [0, 255] range
img = hacked_image[0]
img /= 2.
img += 0.5
img *= 255.
# Save the hacked image!
im = Image.fromarray(img.astype(np.uint8))
im.save("hacked-image.png")備註:
原始影象預測的程式碼中需要外網連線imageNet 的classes列表,我的電腦總連不上,於是直接把那個列表下載到了本地,程式碼稍做了一點改變。有需要可以在百度雲上自取:連結:https://pan.baidu.com/s/1sNMEUj3mTnT7PlzL2efVQQ ,提取碼:gs0s
本人實驗中原始影象用InceptionV3預測為波斯貓的可能性是:84.01%。生成的攻擊影象輸入網路預測為toaster的可能性是89.8%,人直觀的看兩張影象並沒有區別,實在是太可怕了!

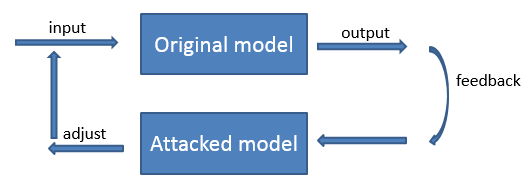
神經網路的黑箱攻擊
黑箱攻擊是指並不知道原始網路的內部構造
上面我們的操作需要有能夠直接進入神經網路的許可權,因為我們實際上是“訓練”神經網路來欺騙自身,我們需要它的拷貝版。在實際生活中,沒有公司會讓你下載的到他們受過訓練的神經網路的程式碼,這也就意味著我們無法來進行這個攻擊性的操作了……對嗎?
並沒有!研究者發現,我們可以通過探測另一個神經網路的運轉訓練一個自己的神經網路替代品以此映象這個網路。然後,使用我們的替代品神經網路來生成通用的欺騙原來神經網路的黑客影象!這被稱為黑箱攻擊(black-box attack)。
我覺得黑箱攻擊就是指我們不停的改變輸入影象進入到擬攻擊網路,根據擬攻擊網路的輸出獲取到該網路的一定規律,然後建立一個該網路的映象網路(即對抗網路)改變我們的輸入,這樣就能夠達到欺騙擬攻擊網路的目的了。但是這樣也需要拿大量的樣本去試錯,類似窮舉了。公司應該會對這樣的使用者採取一些反攻擊策略吧。