
Java 8 之原理篇
1. Lambda實現原理
1.1 例項解析
先從一個例子開始
public class LambdaTest { public static void print(String name, Print print){ print.print(name); } public static void main(String [] args) { String name = "Chen Longfei"; String prefix = "hello, "; print(name, (t) -> System.out.println(t)); //與上一行不同的是,Lambda表示式的函式體中引用了外部變數‘prefix’ print(name, (t) -> System.out.println(prefix + t)); } } @FunctionalInterface interface Print { void print(String name); }
例子很簡單,定義了一個函式式介面Print ,main方法中有兩處程式碼以Lambda表示式的方式實現了print介面,分別打印出不帶字首與帶字首的名字。
執行程式,列印結果如下:
Chen Longfei
hello, Chen Longfei
而(t) -> System.out.println(t)與(t) -> System.out.println(prefix + t))之類的Lambda表示式到底是怎樣被編譯與呼叫的呢?
我們知道,編譯器編譯Java程式碼時經常在背地裡“搞鬼”比如類的全限定名的補全,泛型的型別推斷等,編譯器耍的這些小聰明可以幫助我們寫出更優雅、簡潔、高效的程式碼。鑑於編譯器的一貫作風,我們有理由懷疑,新穎而另類的Lambda表示式在編譯時很可能會被改造過了。
下面通過javap反編譯class檔案一探究竟。
javap
用法如下:
-help --help -? 輸出此用法訊息
-version 版本資訊
-v -verbose 輸出附加資訊
-l 輸出行號和本地變量表
-public 僅顯示公共類和成員
-protected 顯示受保護的/公共類和成員
-package 顯示程式包/受保護的/公共類
和成員 (預設)
-p -private 顯示所有類和成員
-c 對程式碼進行反彙編
-s 輸出內部型別簽名
-sysinfo 顯示正在處理的類的
系統資訊 (路徑, 大小, 日期, MD5 雜湊)
-constants 顯示最終常量
-classpath指定查詢使用者類檔案的位置
-cp指定查詢使用者類檔案的位置
-bootclasspath覆蓋引導類檔案的位置
javap -p Print.class
結果如下:
interface test.Print {
public abstract void print(java.lang.String);
}
javap -p LambdaTest.class
結果如下:
Compiled from "LambdaTest.java"
public class test.LambdaTest {
public test.LambdaTest();
public static void print(java.lang.String, test.Print);
public static void main(java.lang.String[]);
private static void Lambda$main$1(java.lang.String);
private static void Lambda$main$0(java.lang.String, java.lang.String);
}
可見,編譯器對Print介面的改造比較小,只是為print方法添加了public abstract關鍵字,而對LambdaTest的變化就比較大了,添加了兩個靜態方法:
private static void Lambda$main
main$0(java.lang.String, java.lang.String);
對比原生的java程式碼,很容易做出推測,這兩個靜態方法與兩處Lambda表示式相關:
print(name, (t) -> System.out.println(t));
print(name, (t) -> System.out.println(prefix + t));
到底有什麼關聯呢?使用javap -p -v -c LambdaTest.class檢視更加詳細的反編譯結果:
public class test.LambdaTest
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #15.#30 // java/lang/Object."<init>":()V
#2 = InterfaceMethodref #31.#32 // test/Print.print:(Ljava/lang/String;)V
#3 = String #33 // Chen Longfei
#4 = String #34 // hello,
#5 = InvokeDynamic #0:#39 // #0:print:(Ljava/lang/String;)Ltest/Print;
#6 = Methodref #14.#40 // test/LambdaTest.print:(Ljava/lang/String;Ltest/Print;)V
#7 = InvokeDynamic #1:#42 // #1:print:()Ltest/Print;
#8 = Fieldref #43.#44 // java/lang/System.out:Ljava/io/PrintStream;
#9 = Methodref #45.#46 // java/io/PrintStream.println:(Ljava/lang/String;)V
#10 = Class #47 // java/lang/StringBuilder
#11 = Methodref #10.#30 // java/lang/StringBuilder."<init>":()V
#12 = Methodref #10.#48 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder
;
#13 = Methodref #10.#49 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#14 = Class #50 // test/LambdaTest
#15 = Class #51 // java/lang/Object
#16 = Utf8 <init>
#17 = Utf8 ()V
#18 = Utf8 Code
#19 = Utf8 LineNumberTable
#20 = Utf8 print
#21 = Utf8 (Ljava/lang/String;Ltest/Print;)V
#22 = Utf8 main
#23 = Utf8 ([Ljava/lang/String;)V
#24 = Utf8 Lambda$main$1
#25 = Utf8 (Ljava/lang/String;)V
#26 = Utf8 Lambda$main$0
#27 = Utf8 (Ljava/lang/String;Ljava/lang/String;)V
#28 = Utf8 SourceFile
#29 = Utf8 LambdaTest.java
#30 = NameAndType #16:#17 // "<init>":()V
#31 = Class #52 // test/Print
#32 = NameAndType #20:#25 // print:(Ljava/lang/String;)V
#33 = Utf8 Chen Longfei
#34 = Utf8 hello,
#35 = Utf8 BootstrapMethods
#36 = MethodHandle #6:#53 // invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/inv
oke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/M
ethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
#37 = MethodType #25 // (Ljava/lang/String;)V
#38 = MethodHandle #6:#54 // invokestatic test/LambdaTest.Lambda$main$0:(Ljava/lang/String;Ljava/lang/St
ring;)V
#39 = NameAndType #20:#55 // print:(Ljava/lang/String;)Ltest/Print;
#40 = NameAndType #20:#21 // print:(Ljava/lang/String;Ltest/Print;)V
#41 = MethodHandle #6:#56 // invokestatic test/LambdaTest.Lambda$main$1:(Ljava/lang/String;)V
#42 = NameAndType #20:#57 // print:()Ltest/Print;
#43 = Class #58 // java/lang/System
#44 = NameAndType #59:#60 // out:Ljava/io/PrintStream;
#45 = Class #61 // java/io/PrintStream
#46 = NameAndType #62:#25 // println:(Ljava/lang/String;)V
#47 = Utf8 java/lang/StringBuilder
#48 = NameAndType #63:#64 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#49 = NameAndType #65:#66 // toString:()Ljava/lang/String;
#50 = Utf8 test/LambdaTest
#51 = Utf8 java/lang/Object
#52 = Utf8 test/Print
#53 = Methodref #67.#68 // java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHan
dles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;L
java/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
#54 = Methodref #14.#69 // test/LambdaTest.Lambda$main$0:(Ljava/lang/String;Ljava/lang/String;)V
#55 = Utf8 (Ljava/lang/String;)Ltest/Print;
#56 = Methodref #14.#70 // test/LambdaTest.Lambda$main$1:(Ljava/lang/String;)V
#57 = Utf8 ()Ltest/Print;
#58 = Utf8 java/lang/System
#59 = Utf8 out
#60 = Utf8 Ljava/io/PrintStream;
#61 = Utf8 java/io/PrintStream
#62 = Utf8 println
#63 = Utf8 append
#64 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;
#65 = Utf8 toString
#66 = Utf8 ()Ljava/lang/String;
#67 = Class #71 // java/lang/invoke/LambdaMetafactory
#68 = NameAndType #72:#76 // metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava
/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/
lang/invoke/CallSite;
#69 = NameAndType #26:#27 // Lambda$main$0:(Ljava/lang/String;Ljava/lang/String;)V
#70 = NameAndType #24:#25 // Lambda$main$1:(Ljava/lang/String;)V
#71 = Utf8 java/lang/invoke/LambdaMetafactory
#72 = Utf8 metafactory
#73 = Class #78 // java/lang/invoke/MethodHandles$Lookup
#74 = Utf8 Lookup
#75 = Utf8 InnerClasses
#76 = Utf8 (Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/
lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
#77 = Class #79 // java/lang/invoke/MethodHandles
#78 = Utf8 java/lang/invoke/MethodHandles$Lookup
#79 = Utf8 java/lang/invoke/MethodHandles
{
public test.LambdaTest();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 6: 0
public static void print(java.lang.String, test.Print);
descriptor: (Ljava/lang/String;Ltest/Print;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=2
0: aload_1
1: aload_0
2: invokeinterface #2, 2 // InterfaceMethod test/Print.print:(Ljava/lang/String;)V
7: return
LineNumberTable:
line 9: 0
line 10: 7
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: ldc #3 // String Chen Longfei
2: astore_1
3: ldc #4 // String hello,
5: astore_2
6: aload_1
7: aload_2
8: invokedynamic #5, 0 // InvokeDynamic #0:print:(Ljava/lang/String;)Ltest/Print;
13: invokestatic #6 // Method print:(Ljava/lang/String;Ltest/Print;)V
16: aload_1
17: invokedynamic #7, 0 // InvokeDynamic #1:print:()Ltest/Print;
22: invokestatic #6 // Method print:(Ljava/lang/String;Ltest/Print;)V
25: return
LineNumberTable:
line 13: 0
line 14: 3
line 16: 6
line 18: 16
line 19: 25
private static void Lambda$main$1(java.lang.String);
descriptor: (Ljava/lang/String;)V
flags: ACC_PRIVATE, ACC_STATIC, ACC_SYNTHETIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #8 // Field java/lang/System.out:Ljava/io/PrintStream;
3: aload_0
4: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
7: return
LineNumberTable:
line 18: 0
private static void Lambda$main$0(java.lang.String, java.lang.String);
descriptor: (Ljava/lang/String;Ljava/lang/String;)V
flags: ACC_PRIVATE, ACC_STATIC, ACC_SYNTHETIC
Code:
stack=3, locals=2, args_size=2
0: getstatic #8 // Field java/lang/System.out:Ljava/io/PrintStream;
3: new #10 // class java/lang/StringBuilder
6: dup
7: invokespecial #11 // Method java/lang/StringBuilder."<init>":()V
10: aload_0
11: invokevirtual #12 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
14: aload_1
15: invokevirtual #12 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
18: invokevirtual #13 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
21: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
24: return
LineNumberTable:
line 16: 0
}
SourceFile: "LambdaTest.java"
InnerClasses:
public static final #74= #73 of #77; //Lookup=class java/lang/invoke/MethodHandles$Lookup of class java/lang/invoke/MethodHandles
BootstrapMethods:
0: #36 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(
Ljava/lang/invoke/MethodHandles$Lookup;
Ljava/lang/String;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodHandle;
Ljava/lang/invoke/MethodType;)
Ljava/lang/invoke/CallSite;
Method arguments:
#37 (Ljava/lang/String;)V
#38 invokestatic test/LambdaTest.Lambda$main$0:(Ljava/lang/String;Ljava/lang/String;)V
#37 (Ljava/lang/String;)V
1: #36 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(
Ljava/lang/invoke/MethodHandles$Lookup;
Ljava/lang/String;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodHandle;
Ljava/lang/invoke/MethodType;)
Ljava/lang/invoke/CallSite;
Method arguments:
#37 (Ljava/lang/String;)V
#41 invokestatic test/LambdaTest.Lambda$main$1:(Ljava/lang/String;)V
#37 (Ljava/lang/String;)V
這個 class 檔案展示了三個主要部分:
- 常量池
- 構造方法和 main、print、Lambda$main main$1方法
- Lambda表示式生成的內部類
重點看下main方法的實現:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
// 將字串常量"Chen Longfei"從常量池壓棧到運算元棧
0: ldc #3 // String Chen Longfei
// 將棧頂引用型數值存入第二個本地變,即 String name = "Chen Longfei"
2: astore_1
// 將字串常量"hello,"從常量池壓棧到運算元棧
3: ldc #4 // String hello,
// 將棧頂引用型數值存入第三個本地變數, 即 String prefix = "hello, "
5: astore_2
//將第二個引用型別本地變數推送至棧頂,即 name
6: aload_1
//將第三個引用型別本地變數推送至棧頂,即 prefix
7: aload_2
//通過invokedynamic指令建立Print介面的實匿名內部類,實現 (t) -> System.out.println(prefix + t)
8: invokedynamic #5, 0 // InvokeDynamic #0:print:(Ljava/lang/String;)Ltest/Print;
//呼叫靜態方法print
13: invokestatic #6 // Method print:(Ljava/lang/String;Ltest/Print;)V
//將第二個引用型別本地變數推送至棧頂,即 name
16: aload_1
//通過invokedynamic指令建立Print介面的匿名內部類,實現 (t) -> System.out.println(t)
17: invokedynamic #7, 0 // InvokeDynamic #1:print:()Ltest/Print;
//呼叫靜態方法print
22: invokestatic #6 // Method print:(Ljava/lang/String;Ltest/Print;)V
25: return
……
兩個匿名內部類是通過BootstrapMethods方法建立的:
//匿名內部類
InnerClasses:
public static final #74= #73 of #77; //Lookup=class java/lang/invoke/MethodHandles$Lookup of class java/lang/invoke/MethodHandles
BootstrapMethods:
//呼叫靜態工廠LambdaMetafactory.metafactory建立匿名內部類1。實現了 (t) -> System.out.println(prefix + t)
0: #36 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(
Ljava/lang/invoke/MethodHandles$Lookup;
Ljava/lang/String;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodHandle;
Ljava/lang/invoke/MethodType;)
Ljava/lang/invoke/CallSite;
Method arguments:
#37 (Ljava/lang/String;)V
//該類會呼叫靜態方法LambdaTest.Lambda$main$0
#38 invokestatic test/LambdaTest.Lambda$main$0:(Ljava/lang/String;Ljava/lang/String;)V
#37 (Ljava/lang/String;)V
//呼叫靜態工廠LambdaMetafactory.metafactory建立匿名內部類2,實現了 (t) -> System.out.println(t)
1: #36 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(
Ljava/lang/invoke/MethodHandles$Lookup;
Ljava/lang/String;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodHandle;
Ljava/lang/invoke/MethodType;)
Ljava/lang/invoke/CallSite;
Method arguments:
#37 (Ljava/lang/String;)V
//該類會呼叫靜態方法LambdaTest.Lambda$main$1
#41 invokestatic test/LambdaTest.Lambda$main$1:(Ljava/lang/String;)V
#37 (Ljava/lang/String;)V
可以在執行時加上-Djdk.internal.Lambda.dumpProxyClasses=%PATH%,加上這個引數後,執行時,會將生成的內部類class輸出到%PATH%路徑下
Javap -p -c 反編譯兩個檔案
//print(name, (t) -> System.out.println(t))的例項
final class test.LambdaTest$$Lambda$1 implements test.Print {
private test.LambdaTest$$Lambda$1(); //構造方法
Code:
0: aload_0
1: invokespecial #10 // Method java/lang/Object."<init>":()V
4: return
//實現test.Print介面方法
public void print(java.lang.String);
Code:
0: aload_1
//呼叫靜態方法LambdaTest.Lambda$1
1: invokestatic #18 // Method test/LambdaTest.Lambda$1:(Ljava/lang/String;)V
4: return
}
//print(name, (t) -> System.out.println(prefix + t))的例項
final class test.LambdaTest$$Lambda$2 implements test.Print {
private final java.lang.String arg$1;
private test.LambdaTest$$Lambda$2(java.lang.String);
Code:
0: aload_0
1: invokespecial #13 // Method java/lang/Object."<init>":()V
4: aload_0
5: aload_1
//final變數arg$1由構造方法傳入
6: putfield #15 // Field arg$1:Ljava/lang/String;
9: return
//該方法返回一個 LambdaTest$$Lambda$2例項
private static test.Print get$Lambda(java.lang.String);
Code:
0: new #2 // class test/LambdaTest$$Lambda$2
3: dup
4: aload_0
5: invokespecial #19 // Method "<init>":(Ljava/lang/String;)V
8: areturn
//實現test.Print介面方法
public void print(java.lang.String);
Code:
0: aload_0
1: getfield #15 // Field arg$1:Ljava/lang/String;
4: aload_1
//呼叫靜態方法LambdaTest.Lambda$0
5: invokestatic #27 // Method test/LambdaTest.Lambda$0:(Ljava/lang/String;Ljava/lang/String;)V
8: return
}
print(name, (t) -> System.out.println(prefix + t))引用了局部變數prefix,LambdaTest$$Lambda$2類多了一個final引數:
private final java.lang.String arg$1
該引數由構造方法傳入,用來儲存main方法中的區域性變數prefix:
String prefix = "hello, ";
由於外部類的main方法與匿名內部類LambdaTest$$Lambda$2引用了同一份變數,該變數雖然在程式碼層面獨立儲存於兩個類當中,但是在邏輯上具有一致性,所以匿名內部類中加上了final關鍵字,而外部類中雖然沒有為prefix顯式地新增final,但是在被Lambda表示式引用後,該變數就自動隱含了final語意(再次更改會報錯)。
1.2 InvokeDynamic
通過上面的例子可以發現,Lambda表示式由虛擬機器指令InvokeDynamic實現方法呼叫。
1.2.1 方法呼叫
方法呼叫不等同於方法執行,方法呼叫階段的唯一任務就是確定被呼叫方法的版本(即確定具體呼叫那一個方法),不涉及方法內部具體執行。
java虛擬機器中提供了5條方法呼叫的位元組碼指令:
- invokestatic:呼叫靜態方法
- invokespecial:呼叫例項構造器方法、私有方法、父類方法
- invokevirtual:呼叫虛方法。
- invokeinterface:呼叫介面方法,在執行時再確定一個實現該介面的物件
- invokedynamic:執行時動態解析出呼叫的方法,然後去執行該方法
InvokeDynamic是 java 7 引入的一條新的虛擬機器指令,這是自 1.0 以來第一次引入新的虛擬機器指令。到了 java 8 這條指令才第一次在 java 應用,用在 Lambda 表示式中。InvokeDynamic與其他invoke指令不同的是它允許由應用級的程式碼來決定方法解析。
1.2.2 指令規範
根據JVM規範的規定,InvokeDynamic的操作碼是186(0xBA),格式是:
invokedynamic indexbyte1 indexbyte2 0 0
InvokeDynamic指令有四個運算元,前兩個運算元構成一個索引[ (indexbyte1 << 8) | indexbyte2 ],指向類的常量池,後兩個運算元保留,必須是0。
檢視上例中LambdaTest類的反編譯結果,第一處Lambda表示式
print(name, (t) -> System.out.println(t));
對應的指令為:
17: invokedynamic #7, 0 // InvokeDynamic #1:print:()Ltest/Print;
常量池中#7對應的常量為:
#7 = InvokeDynamic #1:#42 // #1:print:()Ltest/Print;
其型別為CONSTANT_InvokeDynamic_info,CONSTANT_InvokeDynamic_info結構是Java7新引入class檔案的,其用途就是給InvokeDynamic指令指定啟動方法(bootstrap method)、呼叫點call site()等資訊, 實際上是個 MethodHandle(方法控制代碼)物件。
#1代表BootstrapMethods表中的索引,即
BootstrapMethods:
//第一個
0: #36 ……
//第二個
1: #36 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(
Ljava/lang/invoke/MethodHandles$Lookup;
Ljava/lang/String;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodType;
Ljava/lang/invoke/MethodHandle;
Ljava/lang/invoke/MethodType;)
Ljava/lang/invoke/CallSite;
Method arguments:
#37 (Ljava/lang/String;)V
#41 invokestatic test/LambdaTest.Lambda$main$1:(Ljava/lang/String;)V
#37 (Ljava/lang/String;)V
也就是說,最終呼叫的是java.lang.invoke.LambdaMetafactory類的靜態方法metafactory()。
1.2.3 執行過程
為了更深入的瞭解InvokeDynamic,先來看幾個術語:
dynamic call site
程式中出現Lambda的地方都被稱作dynamic call site,CallSite 就是一個 MethodHandle(方法控制代碼)的 holder。方法控制代碼指向一個呼叫點真正執行的方法。
bootstrap method
java裡對所有Lambda的有統一的bootstrap method(LambdaMetafactory.metafactory),bootstrap執行期動態生成了匿名類,將其與CallSite繫結,得到了一個獲取匿名類例項的call site object
call site object
call site object持有MethodHandle的引用作為它的target,它是bootstrap method方法成功呼叫後的結果,將會與 dynamic call site永久繫結。call site object的target會被JVM執行,就如同執行一條invokevirtual指令,其所需的引數也會被壓入operand stack。最後會得一個實現了functional interface的物件。
InvokeDynamic首先需要生成一個 CallSite(呼叫點物件),CallSite 是由 bootstrap method 返回,也就是調(LambdaMetafactory.metafactory方法。
public static CallSite metafactory(MethodHandles.Lookup caller,
String invokedName,
MethodType invokedType,
MethodType samMethodType,
MethodHandle implMethod,
MethodType instantiatedMethodType)
throws LambdaConversionException {
AbstractValidatingLambdaMetafactory mf;
mf = new InnerClassLambdaMetafactory(caller, invokedType,
invokedName, samMethodType,
implMethod, instantiatedMethodType,
false, EMPTY_CLASS_ARRAY, EMPTY_MT_ARRAY);
mf.validateMetafactoryArgs();
return mf.buildCallSite();
}
前三個引數是固定的,由VM自動壓棧:
- MethodHandles.Lookup caller代表Indy 指令所在的類的上下文(在上例中就是LambdaTest),可以通過 Lookup#lookupClass()獲取這個類
- String invokedName表示要實現的方法名(在上例中就是Print介面的方法名”print”)
- MethodType invokedType call site object所持有的MethodHandle需要的引數和返回型別(signature)
接下來就是附加引數,這些引數是靈活的,由Bootstrap methods 表提供:
- MethodType samMethodType表示要實現functional interface裡面抽象方法的型別
- MethodHandle implMethod表示編譯器給生成的 desugar 方法,是一個 MethodHandle
- MethodType instantiatedMethodType即執行時的型別,因為方法定義可能是泛型,傳入時可能是具體型別String之類的,要做型別校驗強轉等等
LambdaMetafactory.metafactory 方法會建立一個匿名類,這個類是通過 ASM 編織位元組碼在記憶體中生成的,然後直接通過 UNSAFE 直接載入而不會寫到檔案裡。
1.2.4 MethodHandle
要讓invokedynamic正常執行,一個核心的概念就是方法控制代碼(method handle)。它代表了一個可以從invokedynamic呼叫點進行呼叫的方法。每個invokedynamic指令都會與一個特定的方法關聯(也就是bootstrap method或BSM)。當編譯器遇到invokedynamic指令的時候,BSM會被呼叫,會返回一個包含了方法控制代碼的物件,這個物件表明了呼叫點要實際執行哪個方法。
Java 7 API中加入了java.lang.invoke.MethodHandle(及其子類),通過它們來代表invokedynamic指向的方法。
一個Java方法可以視為由四個基本內容所構成:
- 名稱
- 簽名(包含返回型別)
- 定義它的類
- 實現方法的位元組碼
這意味著如果要引用某個方法,我們需要有一種有效的方式來表示方法簽名(而不是反射中強制使用的令人討厭的Class<?>[] hack方式)。
方法控制代碼首先需要的一個表達方法簽名的方式,以便於查詢。在Java 7引入的Method Handles API中,這個角色是由java.lang.invoke.MethodType類來完成的,它使用一個不可變的例項來代表簽名。要獲取MethodType,我們可以使用methodType()工廠方法。這是一個引數可變的方法,以class物件作為引數。
第一個引數所使用的class物件,對應著簽名的返回型別;剩餘引數中所使用的class物件,對應著簽名中方法引數的型別。例如:
//toString()的簽名
MethodType mtToString = MethodType.methodType(String.class);
// setter方法的簽名
MethodType mtSetter = MethodType.methodType(void.class, Object.class);
// Comparator中compare()方法的簽名
MethodType mtStringComparator = MethodType.methodType(int.class, String.class, String.class);
現在我們就可以使用MethodType,再組合方法名稱以及定義方法的類來查詢方法控制代碼。要實現這一點,我們需要呼叫靜態的MethodHandles.lookup()方法。這樣的話,會給我們一個“查詢上下文(lookup context)”,這個上下文基於當前正在執行的方法(也就是呼叫lookup()的方法)的訪問許可權。
查詢上下文物件有一些以“find”開頭的方法,例如,findVirtual()、findConstructor()、findStatic()等。這些方法將會返回實際的方法控制代碼,需要注意的是,只有在建立查詢上下文的方法能夠訪問(呼叫)被請求方法的情況下,才會返回控制代碼。這與反射不同,我們沒有辦法繞過訪問控制。換句話說,方法控制代碼中並沒有與setAccessible()對應的方法。例如
public MethodHandle getToStringMH() {
MethodHandle mh = null;
MethodType mt = MethodType.methodType(String.class);
MethodHandles.Lookup lk = MethodHandles.lookup();
try {
mh = lk.findVirtual(getClass(), "toString", mt);
} catch (NoSuchMethodException | IllegalAccessException mhx) {
throw (AssertionError)new AssertionError().initCause(mhx);
}
return mh;
}
MethodHandle中有兩個方法能夠觸發對方法控制代碼的呼叫,那就是invoke()和invokeExact()。這兩個方法都是以接收者(receiver)和呼叫變數作為引數,所以它們的簽名為:
public final Object invoke(Object... args) throws Throwable;
public final Object invokeExact(Object... args) throws Throwable;
兩者的區別在於,invokeExact()在呼叫方法控制代碼時會試圖嚴格地直接匹配所提供的變數。而invoke()與之不同,在需要的時候,invoke()能夠稍微調整一下方法的變數。invoke()會執行一個asType()轉換,它會根據如下的這組規則來進行變數的轉換:
- 如果需要的話,原始型別會進行裝箱操作
- 如果需要的話,裝箱後的原始型別會進行拆箱操作
- 如果必要的話,原始型別會進行擴充套件
- void返回型別會轉換為0(對於返回原始型別的情況),而對於預期得到引用型別的返回值的地方,將會轉換為null
- null值會被視為正確的,不管靜態型別是什麼都可以進行傳遞
接下來,我們看一下考慮上述規則的簡單呼叫樣例:
Object rcvr = "a";
try {
MethodType mt = MethodType.methodType(int.class);
MethodHandles.Lookup l = MethodHandles.lookup();
MethodHandle mh = l.findVirtual(rcvr.getClass(), "hashCode", mt);
int ret;
try {
ret = (int)mh.invoke(rcvr);
System.out.println(ret);
} catch (Throwable t) {
t.printStackTrace();
}
} catch (IllegalArgumentException | NoSuchMethodException | SecurityException e) {
e.printStackTrace();
} catch (IllegalAccessException x) {
x.printStackTrace();
}
上面的程式碼呼叫了Object的hashcode()方法,看到這裡,你肯定會說這不就是 Java 的反射嗎?
確實,MethodHandle 和 Reflection 實現的功能有太多相似的地方,都是執行時解析方法呼叫,理解方法控制代碼的一種方式就是將其視為以安全、現代的方式來實現反射的核心功能,在這個過程會盡可能地保證型別的安全。
但是,究其本質,兩者之間還是有區別的:
- MethodHandle 和 Reflection 都可以分派方法呼叫,但是 MethodHandle 比 Reflection 更強大,它是模擬位元組碼層次的方法分派。有興趣的同學可以對比 MethodHandles.Lookup 提供的findStatic、findVirtual、findSpecial三個方法和 Reflection 的反射呼叫;
- MethodHandle 是結合 invokedynamic 指令一起為動態語言服務的,也就是說MethodHandle (更準確的來說是其設計理念)是服務於所有執行在JVM之上的語言,而 Relection 則只是適用 Java 語言本身。
2. Stream實現原理
2.1 操作分類
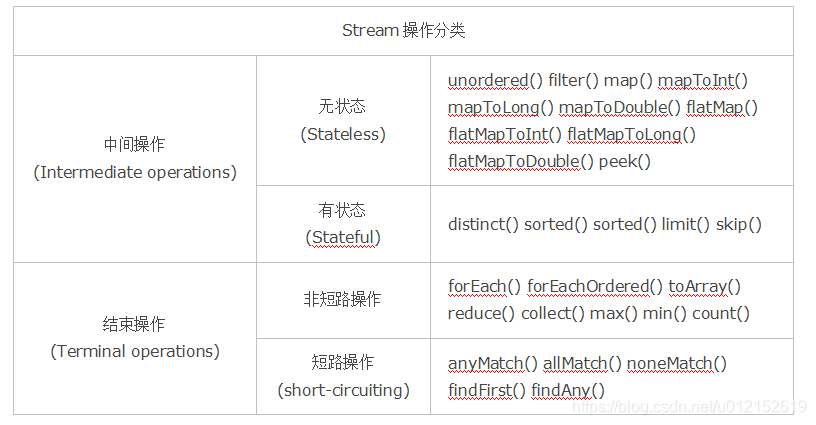
Stream中的操作可以分為兩大類:中間操作(Intermediate operations)與結束操作(Terminal operations),中間操作只是對操作進行了記錄,只有結束操作才會觸發實際的計算(即惰性求值),這也是Stream在迭代大集合時高效的原因之一。中間操作又可以分為無狀態(Stateless)操作與有狀態(Stateful)操作,前者是指元素的處理不受之前元素的影響;後者是指該操作只有拿到所有元素之後才能繼續下去。結束操作又可以分為短路(short-circuiting)與非短路操作,這個應該很好理解,前者是指遇到某些符合條件的元素就可以得到最終結果;而後者是指必須處理所有元素才能得到最終結果。
之所以要進行如此精細的劃分,是因為底層對每一種情況的處理方式不同。
2.2 包結構概覽
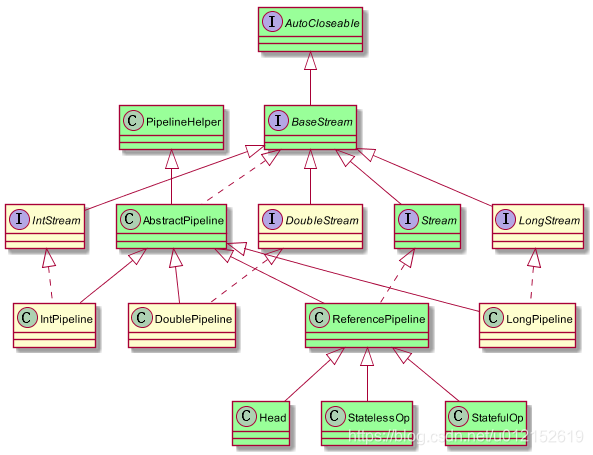
- BaseStream定義了流的迭代、並行、序列等基本特性;
- Stream中定義了map、filter、flatmap等使用者關注的常用操作;
- PipelineHelper用於執行管道流中的操作以及捕獲輸出型別、並行度等資訊
- Head、StatelessOp、StatefulOp為ReferencePipeline中的內部子類,用於描述流的操作階段。
2.3 原始碼分析
來看一個例子:
List<String> list = Arrays.asList("China", "America", "Russia", "Britain");
List<String> result = list.stream()
.filter(e -> e.length() >= 4)
.map(e -> e.charAt(0))
.map(e -> String.valueOf(e))
.collect(Collectors.toList());
上面List首先生成了一個stream,然後經過filter、map、map三次無狀態的中間操作,最後由最終操作collect收尾。
下面通過原始碼來一次庖丁解牛,看看一步步到底是怎麼實現的。
2.3.1 stream()
生成流的操作是通過呼叫StreamSupport類下面的方法實現的:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
方法很簡單,直接new了一個ReferencePipeline.Head物件並返回。Head是ReferencePipeline的子類,而ReferencePipeline是Stream的子類。也就是說,返回了一個由Head實現的Stream。
追溯原始碼可以發現,Head最終通過呼叫父類ReferencePipeline的構造方法完成例項化:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
//返回了一個由Head實現的Stream,三個引數分別代表流的資料來源、特性組合、是否並行
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
AbstractPipeline(Spliterator<?> source, int sourceFlags, boolean parallel) {
this.previousStage = null; //上一個stage指向null
this.sourceSpliterator = source;
this.sourceStage = this; //源頭stage指向自己
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
AbstractPipeline類中定義了三個稱為“stage”內部變數:
/**
* Backlink to the head of the pipeline chain (self if this is the source
* stage).
*/
@SuppressWarnings("rawtypes")
private final AbstractPipeline sourceStage;
/**
* The "upstream" pipeline, or null if this is the source stage.
*/
@SuppressWarnings("rawtypes")
private final AbstractPipeline previousStage;
/**
* The next stage in the pipeline, or null if this is the last stage.
* Effectively final at the point of linking to the next pipeline.
*/
@SuppressWarnings("rawtypes")
private AbstractPipeline nextStage;
當前節點同時持有前一個節點與後一個節點的指標,並且保留了頭結點的引用,這不是典型的雙端連結串列嗎?
基於此,分析上面的建構函式:
- 前一個節點為空
- 頭結點指向自己
- 後一個節點暫時未指定
很顯然,構造出的是一個雙端列表的頭結點
綜上所述,stream函式返回了一個由ReferencePipeline類實現的管道流,且該管道流為一個雙端連結串列的頭結點
2.3.2 filter()
再來看第二步,filter操作,具體實現在ReferencePipeline的如下方法:
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
//入參不能為空
Objects.requireNonNull(predicate);
//構建了一個StatelessOp物件,即無狀態的中間操作
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
//覆寫了父類的一個方法opWrapSink
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
StatelessOp與Head一樣,也是ReferencePipeline的內部子類,同樣通過呼叫父類ReferencePipeline的構造方法完成例項化,注意第一個引數,傳入的是this,就是將上一步建立的Head物件傳入,作為StatelessOp的previousStage。
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this; //前一個stage指向自己
this.previousStage = previousStage; //自己指向前一個stage
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage; //也保留了頭結點的引用
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
filter操作成為了雙端連結串列的第二環。
值得注意的是,構造StatelessOp時,覆寫了父類的一個方法opWrapSink,返回了一個Sink物件,作用暫時未知,猜測後面的操作應該會用到
2.3.3 map()
再來看接下來的map操作:
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
與filter類似,構造了一個StatelessOp物件,追加到雙端列表中的末尾。
不同的地方在於opWrapSink方法的實現,繼續猜測,通過覆寫opWrapSink,應該可以影響管道流的流程,實現定製化的操作
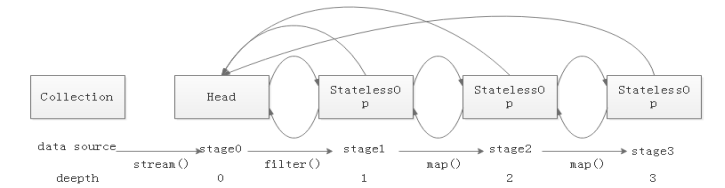
呼叫一系列操作後會形成如下所示的雙鏈表結構:
2.3.4 collect()
最後來看collect操作,不同於filter與map,collect為結束操作,肯定有特殊之處:
@Override
@SuppressWarnings("unchecked")
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
if (isParallel()
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
else { //序列模式
container = evaluate(ReduceOps.makeRef(collector)); //evaluate觸發
}
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}
ReduceOps.makeRef(collector) 會構造一個TerminalOp物件,傳入evaluate方法,追溯原始碼,發現最終是呼叫copyInto方法來啟動流水線:
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) { //無短路操作
wrappedSink.begin(spliterator.getExactSizeIfKnown());//通知開始遍歷
spliterator.forEachRemaining(wrappedSink); //依次處理每個元素
wrappedSink.end();//通知結束遍歷
}
else { //有短路操作
copyIntoWithCancel(wrappedSink, spliterator);
}
}
該方法從資料來源Spliterator獲取的元素,推入Sink進行處理,如果有短路操作,在每個元素處理後會通過Sink.cancellationRequested()判斷是否立即返回。
前面的filter、map操作只是做了一系列的準備工作,並沒有執行,真正的迭代是由結束操作collect來觸發的。
2.3.5 Sink
Stream中使用Stage的概念來描述一個完整的操作,將具有先後順序的各個Stage連到一起,就構成了整個流水線。
很多Stream操作會需要一個回撥函式(Lambda表示式),因此一個完整的操作是<資料來源,操作,回撥函式>構成的三元組。
Stage只是解決了操作記錄的問題,要想讓流水線起到應有的作用我們需要一種將所有操作疊加到一起的方案。你可能會覺得這很簡單,只需要從流水線的head開始依次執行每一步的操作(包括回撥函式)就行了。這聽起來似乎是可行的,但是你忽略了前面的Stage並不知道後面Stage到底執行了哪種操作,以及回撥函式是哪種形式。換句話說,只有當前Stage本身才知道該如何執行自己包含的動作。這就需要有某種協議來協調相鄰Stage之間的呼叫關係。
繼續從原始碼找答案。
filter、map原始碼中,都覆寫了一個名為opWrapSink的方法,該方法會返回一個Sink物件,而collect正是通過Sink來處理流中的資料。種種跡象表明,這個名為Sink的類在流的處理流程當中扮演了極其重要的角色。
interface Sink<T> extends Consumer<T> {
//開始遍歷元素之前呼叫該方法,通知Sink做好準備,size代表要處理的元素總數,如果傳入-1代表總數未知或者無限
default void begin(long size) {}
//所有元素遍歷完成之後呼叫,通知Sink沒有更多的元素了。
default void end() {}
//如果返回true,代表這個Sink不再接收任何資料
default boolean cancellationRequested() {
return false;
}
//還有一個繼承自Consumer的方法,用於接收管道流中的資料
//void accept(T t);
...
}
collect操作在呼叫copyInto方法時,傳入了一個名為wrappedSink的引數,就是一個Sink物件,由AbstractPipeline.wrapSin方法構造:
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
//自本身stage開始,不斷呼叫前一個stage的opWrapSink,直到頭節點
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}

opWrapSink()方法的作用是將當前操作與下游Sink結合成新Sink,試想,只要從流水線的最後一個Stage開始,不斷呼叫上一個Stage的opWrapSink()方法直到頭節點,就可以得到一個代表了流水線上所有操作的Sink。
而這個opWrapSink方法不就是前面filter、map原始碼中一直很神祕的未知操作嗎?
至此,任督二脈打通,豁然開朗!
有了上面的協議,相鄰Stage之間呼叫就很方便了,每個Stage都會將自己的操作封裝到一個Sink裡,前一個Stage只需呼叫後一個Stage的accept()方法即可,並不需要知道其內部是如何處理的。當然對於有狀態的操作,Sink的begin()和end()方法也是必須實現的。比如Stream.sorted()是一個有狀態的中間操作,其對應的Sink.begin()方法可能會建立一個盛放結果的容器,而accept()方法負責將元素新增到該容器,最後end()負責對容器進行排序。對於短路操作,Sink.cancellationRequested()也是必須實現的,比如Stream.findFirst()是短路操作,只要找到一個元素,cancellationRequested()就應該返回true,以便呼叫者儘快結束查詢。Sink的四個介面方法常常相互協作,共同完成計算任務。實際上Stream API內部實現的的本質,就是如何過載Sink的這四個介面方法。
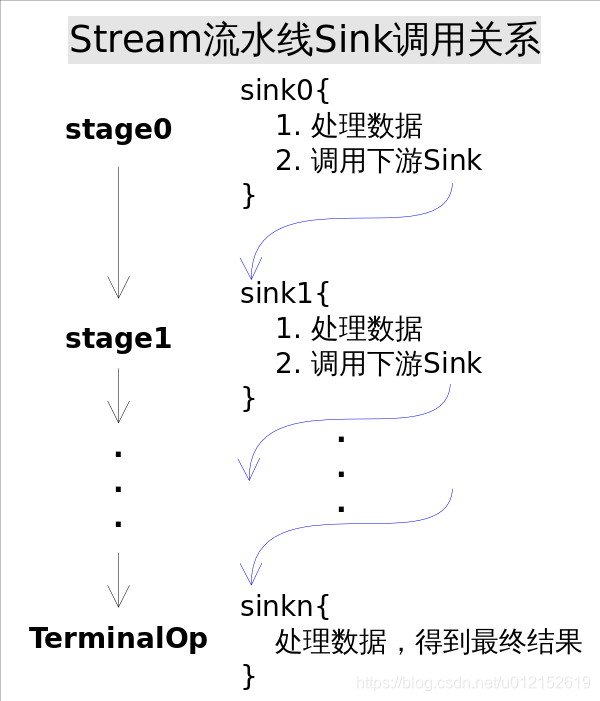
有了Sink對操作的包裝,Stage之間的呼叫問題就解決了,執行時只需要從流水線的head開始對資料來源依次呼叫每個Stage對應的Sink.{begin(), accept(), cancellationRequested(), end()}方法就可以了。一種可能的Sink.accept()方法流程是這樣的:
void accept(U u){
1. 使用當前Sink包裝的回撥函式處理u
2. 將處理結果傳遞給流水線下游的Sink
}
Sink介面的其他幾個方法也是按照這種[處理->轉發]的模型實現。下面我們結合具體例子看看Stream的中間操作是如何將自身的操作包裝成Sink以及Sink是如何將處理結果轉發給下一個Sink的。先看Stream.map()方法:
// Stream.map(),呼叫該方法將產生一個新的Stream
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
...
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override /*opWripSink()方法返回由回撥函式包裝而成Sink*/
Sink<P_OUT> opWrapSink(int flags, Sink<R> downstream) {
return new Sink.ChainedReference<P_OUT, R>(downstream) {
@Override
public void accept(P_OUT u) {
R r = mapper.apply(u);// 1. 使用當前Sink包裝的回撥函式mapper處理u
downstream.accept(r);// 2. 將處理結果傳遞給流水線下游的Sink
}
};
}
};
}
上述程式碼看似複雜,其實邏輯很簡單,就是將回調函式mapper包裝到一個Sink當中。由於Stream.map()是一個無狀態的中間操作,所以map()方法返回了一個StatelessOp內部類物件(一個新的Stream),呼叫這個新Stream的opWripSink()方法將得到一個包裝了當前回調函式的Sink。
再來看一個複雜一點的例子。Stream.sorted()方法將對Stream中的元素進行排序,顯然這是一個有狀態的中間操作,因為讀取所有元素之前是沒法得到最終順序的。拋開模板程式碼直接進入問題本質,sorted()方法是如何將操作封裝成Sink的呢?sorted()一種可能封裝的Sink程式碼如下:
// Stream.sort()方法用到的Sink實現
class RefSortingSink<T> extends AbstractRefSortingSink<T> {
private ArrayList<T> list;// 存放用於排序的元素
RefSortingSink(Sink<? super T> downstream, Comparator<? super T> comparator) {
super(downstream, comparator);
}
@Override
public void begin(long size) {
...
// 建立一個存放排序元素的列表
list = (size >= 0) ? new ArrayList<T>((int) size) : new ArrayList<T>();
}
@Override
public void end() {
list.sort(comparator);// 只有元素全部接收之後才能開始排序
downstream.begin(list.size());
if (!cancellationWasRequested) {// 下游Sink不包含短路操作
list.forEach(downstream::accept);// 2. 將處理結果傳遞給流水線下游的Sink
}
else {// 下游Sink包含短路操作
for (T t : list) {// 每次都呼叫cancellationRequested()詢問是否可以結束處理。
if (downstream.cancellationRequested()) break;
downstream.accept(t);// 2. 將處理結果傳遞給流水線下游的Sink
}
}
downstream.end();
list = null;
}
@Override
public void accept(T t) {
list.add(t);// 1. 使用當前Sink包裝動作處理t,只是簡單的將元素新增到中間列表當中
}
}
- 上述程式碼完美的展現了Sink的四個介面方法是如何協同工作的:
首先beging()方法告訴Sink參與排序的元素個數,方便確定中間結果容器的的大小; - 之後通過accept()方法將元素新增到中間結果當中,最終執行時呼叫者會不斷呼叫該方法,直到遍歷所有元素;
- 最後end()方法告訴Sink所有元素遍歷完畢,啟動排序步驟,排序完成後將結果傳遞給下游的Sink;
- 如果下游的Sink是短路操作,將結果傳遞給下游時不斷詢問下游cancellationRequested()是否可以結束處理。
2.4 結果收集
最後一個問題是流水線上所有操作都執行後,使用者所需要的結果(如果有)在哪裡?首先要說明的是不是所有的Stream結束操作都需要返回結果,有些操作只是為了使用其副作用(Side-effects),比如使用Stream.forEach()方法將結果打印出來就是常見的使用副作用的場景(事實上,除了列印之外其他場景都應避免使用副作用),對於真正需要返回結果的結束操作結果存在哪裡呢?
特別說明:副作用不應該被濫用,也許你會覺得在Stream.forEach()裡進行元素收集是個不錯的選擇,就像下面程式碼中那樣,但遺憾的是這樣使用的正確性和效率都無法保證,因為Stream可能會並行執行。大多數使用副作用的地方都可以使用歸約操作更安全和有效的完成。
// 錯誤的收集方式
ArrayList<String> results = new ArrayList<>();
stream.filter(s -> pattern.matcher(s).matches())
.forEach(s -> results.add(s)); // Unnecessary use of side-effects!
// 正確的收集方式
List<String>results =
stream.filter(s -> pattern.matcher(s).matches())
.collect(Collectors.toList()); // No side-effects!
回到流水線執行結果的問題上來,需要返回結果的流水線結果存在哪裡呢?這要分不同的情況討論,下表給出了各種有返回結果的Stream結束操作。
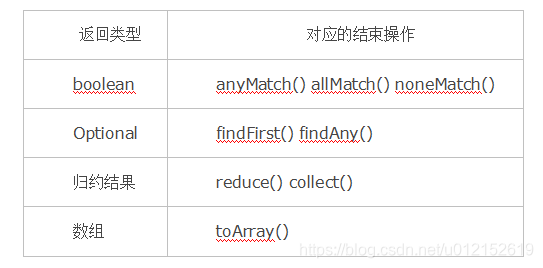
- 對於表中返回boolean或者Optional的操作的操作,由於值返回一個值,只需要在對應的Sink中記錄這個值,等到執行結束時返回就可以了。
- 對於歸約操作,最終結果放在使用者呼叫時指定的容器中(容器型別通過收集器指定)。collect(), reduce(), max(), min()都是歸約操作,雖然max()和min()也是返回一個Optional,但事實上底層是通過呼叫reduce()方法實現的。
- 對於返回是陣列的情況,在最終返回陣列之前,結果其實是儲存在一種叫做Node的資料結構中的。Node是一種多叉樹結構,元素儲存在樹的葉子當中,並且一個葉子節點可以存放多個元素。這樣做是為了並行執行方便。
2.5 並行流
如果將上面的例子改為如下形式,管道流將會以並行模式處理資料:
List<String> list = Arrays.asList("China", "America", "Russia", "Britain");
List<String> result = list.stream()
.parallel()
.filter(e -> e.length() >= 4)
.map(e -> e.charAt(0))
.map(e -> String.valueOf(e))
.collect(Collectors.toList());
parallel()方法的實現很簡單,只是將源stage的並行標記只為true:
@Override
@SuppressWarnings("unchecked")
public final S parallel() {
sourceStage.parallel = true;
return (S) this;
}
在結束操作通過evaluate方法啟動管道流時,會根據並行標記來判斷:
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
collect操作會通過ReduceTask來執行併發任務:
@Override
public <P_IN> R evaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
ReduceTask是ForkJoinTask的子類,其實Stream的並行處理都是基於Fork/Join框架的,相關類與介面的結構如下圖所示:
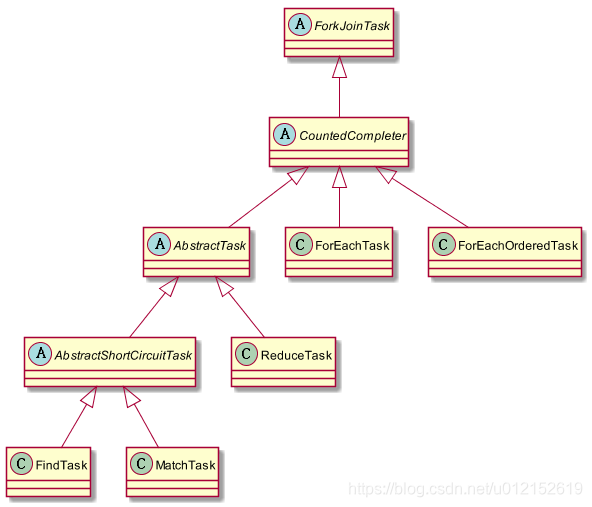
fork/join框架是jdk1.7引入的,可以以遞迴方式將並行的任務拆分成更小的任務,然後將每個子任務的結果合併起來生成整體結果。它是ExecutorService介面的一個實現,它把子任務分配執行緒池(ForkJoinPool)中的工作執行緒。要把任務提交到這個執行緒池,必須建立RecursiveTask的一個子類,如果任務不返回結果則是RecursiveAction的子類。
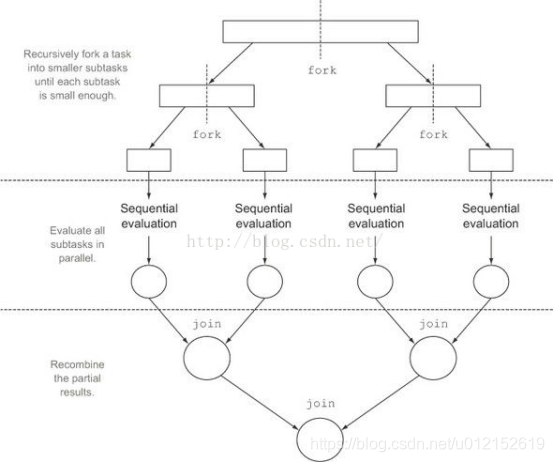
對於ReduceTask來說,任務分解的實現定義在其父類AbstractTask的compute()方法當中:
@Override
public void compute() {
Spliterator<P_IN> rs = spliterator, ls; // right, left spliterators
long sizeEstimate = rs.estimateSize();
long sizeThreshold = getTargetSize(sizeEstimate);
boolean forkRight = false;
@SuppressWarnings("unchecked") K task = (K) this;
while (sizeEstimate > sizeThreshold && (ls = rs.trySplit()) != null) {
K leftChild, rightChild, taskToFork;
task.leftChild = leftChild = task.makeChild(ls);
task.rightChild = rightChild = task.makeChild(rs);
task.setPendingCount(1);
if (forkRight) {
forkRight = false;
rs = ls;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
task = rightChild;
taskToFork = leftChild;
}
taskToFork.fork();
sizeEstimate = rs.estimateSize();
}
task.setLocalResult(task.doLeaf());
task.tryComplete();
}
主要邏輯如下:
先呼叫當前splititerator 方法的estimateSize 方法,預估這個分片中的資料量,根據預估的資料量獲取最小處理單元的閾值,即當資料量已經小於這個閾值的時候進行計算,否則進行fork 將任務劃分成更小的資料