
Java面試之基礎篇(上)
題目來源於網路
後面是筆者自己提供的答案,僅供參考,如有錯誤,歡迎指正
一、基礎篇
1.1、Java基礎
-
面向物件的特徵:繼承、封裝和多型
-
final, finally, finalize 的區別
-
Exception、Error、執行時異常與一般異常有何異同
-
請寫出5種常見到的runtime exception
-
int 和 Integer 有什麼區別,Integer的值快取範圍
-
包裝類,裝箱和拆箱
-
String、StringBuilder、StringBuffer
-
過載和重寫的區別
-
抽象類和介面有什麼區別
-
說說反射的用途及實現
-
說說自定義註解的場景及實現
-
HTTP請求的GET與POST方式的區別
-
Session與Cookie區別
-
列出自己常用的JDK包
-
MVC設計思想
-
equals與==的區別
-
hashCode和equals方法的區別與聯絡
-
什麼是Java序列化和反序列化,如何實現Java序列化?或者請解釋Serializable 介面的作用
-
Object類中常見的方法,為什麼wait notify會放在Object裡邊?
-
Java的平臺無關性如何體現出來的
-
JDK和JRE的區別
Java 8有哪些新特性
1.2、Java常見集合
-
List 和 Set 區別
-
Set和hashCode以及equals方法的聯絡
-
List 和 Map 區別
-
Arraylist 與 LinkedList 區別
-
ArrayList 與 Vector 區別
-
HashMap 和 Hashtable 的區別
-
HashSet 和 HashMap 區別
-
HashMap 和 ConcurrentHashMap 的區別
-
HashMap 的工作原理及程式碼實現,什麼時候用到紅黑樹
-
多執行緒情況下HashMap死迴圈的問題
-
HashMap出現Hash DOS攻擊的問題
-
ConcurrentHashMap 的工作原理及程式碼實現,如何統計所有的元素個數
-
手寫簡單的HashMap
-
看過那些Java集合類的原始碼
1.3、程序和執行緒
-
執行緒和程序的概念、並行和併發的概念
-
建立執行緒的方式及實現
-
程序間通訊的方式
-
說說 CountDownLatch、CyclicBarrier 原理和區別
-
說說 Semaphore 原理
-
說說 Exchanger 原理
-
ThreadLocal 原理分析,ThreadLocal為什麼會出現OOM,出現的深層次原理
-
講講執行緒池的實現原理
-
執行緒池的幾種實現方式
-
執行緒的生命週期,狀態是如何轉移的
可參考:《Java多執行緒程式設計核心技術》
1.4、鎖機制
-
說說執行緒安全問題,什麼是執行緒安全,如何保證執行緒安全
-
重入鎖的概念,重入鎖為什麼可以防止死鎖
-
產生死鎖的四個條件(互斥、請求與保持、不剝奪、迴圈等待)
-
如何檢查死鎖(通過jConsole檢查死鎖)
-
volatile 實現原理(禁止指令重排、重新整理記憶體)
-
synchronized 實現原理(物件監視器)
-
synchronized 與 lock 的區別
-
AQS同步佇列
-
CAS無鎖的概念、樂觀鎖和悲觀鎖
-
常見的原子操作類
-
什麼是ABA問題,出現ABA問題JDK是如何解決的
-
樂觀鎖的業務場景及實現方式
-
Java 8並法包下常見的併發類
-
偏向鎖、輕量級鎖、重量級鎖、自旋鎖的概念
可參考:《Java多執行緒程式設計核心技術》
1.5、JVM
-
JVM執行時記憶體區域劃分
-
記憶體溢位OOM和堆疊溢位SOE的示例及原因、如何排查與解決
-
如何判斷物件是否可以回收或存活
-
常見的GC回收演算法及其含義
-
常見的JVM效能監控和故障處理工具類:jps、jstat、jmap、jinfo、jconsole等
-
JVM如何設定引數
-
JVM效能調優
-
類載入器、雙親委派模型、一個類的生命週期、類是如何載入到JVM中的
-
類載入的過程:載入、驗證、準備、解析、初始化
-
強引用、軟引用、弱引用、虛引用
個人分享答案:
Java基礎
1.面向物件的特徵:繼承、封裝和多型
* 繼承:A extends B,A則繼承了B所有的屬性(非private)和方法,A可重寫方法,也可擴充套件自己的屬性和方法
* 封裝:將資料和基於資料的操作封裝在一起,使其構成一個不可分割的物件,資料的操作隱藏在物件內部,只保留一些介面使其與外部發生聯絡。
封裝的優點:良好的封裝減少耦合;類內部的結構可以自由修改;隱藏內部資訊,實現細節。
* 多型:分為編譯時多型和執行時多型。
編譯時多型:主要指方法的過載,它根據引數列表的不同來區分不同的函式;
執行時多型:當實現多型的三個條件(繼承、重寫、向上轉型)都具備時,指向子類的父類型別引用在真正執行時會執行子類的方法,這樣對外表現為使用相同的類當時表現出不同的結果
2.final, finally, finalize 的區別
* final用來作為類、方法、成員變數的修飾符,表明類是不可繼承的、方法和成員變數是不可修改的
* finally用在try...catch..finally裡,作為異常捕獲裡最後執行的程式碼塊,一般用於釋放資源、關閉連線
* finalize是定義在Object中的方法,子類可以重寫這個方法以整理系統資源或者清理工作,方法在垃圾回收器回收這個物件之前呼叫
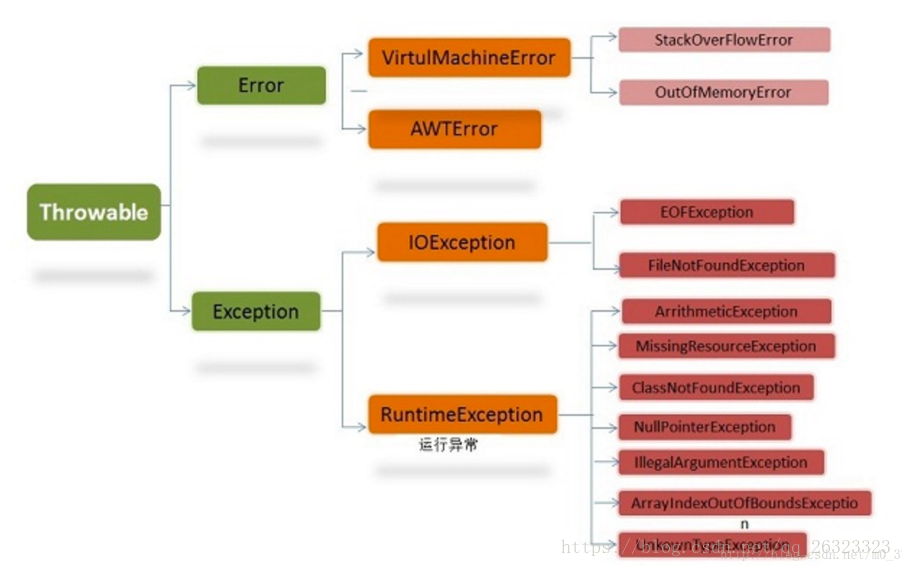
3.Exception、Error、執行時異常與一般異常有何異同
* Exception和Error都繼承自Throwable
* Exception是所有異常的父類,執行時異常和一般異常都繼承自Exception
* 執行時異常:編譯期間不會強制要求捕獲,通常是可以通過編碼避免的異常
* 可檢查異常:在原始碼中必須進行顯示的捕獲處理,這是編譯器檢查的一部分
* Error表現了java執行時系統的內部錯誤和資源耗盡錯誤。大部分錯誤與編寫者執行的操作無關,而表示JVM執行時出現的問題。應用程式不應該丟擲這種錯誤
4.請寫出5種常見到的runtime exception
ArrayIndexOutOfBoundsException
NullPointException
ClassNotFoundException
ClassCastException
NoSuchMethodException
5.int 和 Integer 有什麼區別,Integer的值快取範圍
* int是基本資料型別
* Integer是物件型別,有一系列的物件方法
int和Integer可互相轉換,稱為拆箱封箱操作
* Integer快取值範圍為-128~127
6.包裝類,裝箱和拆箱
* 包裝類是相對於基本型別而言的,八中基本型別都有相對應的包裝類
* 裝箱和拆箱操作是在基本型別和其物件型別之間發生的,是一種自動的行為
Integer i = 10; //裝箱操作,自動呼叫 Integer.valueOf(int val) 方法 i = 10; //裝箱操作,自動呼叫 Integer.valueOf(int val) 方法int n = i; // 拆箱操作,自動呼叫Integer.intValue()方法 n = i; // 拆箱操作,自動呼叫Integer.intValue()方法
7.String、StringBuilder、StringBuffer
* String作為一個final型別的物件,可用來表示字串值,字串的拼接實際是一個不斷產生新的String物件的過程
* StringBuilder在String的拼接過程中,只產生一個物件
* StringBuffer的方法都是synchronized的,相對於StringBuilder而言是執行緒安全的
在執行速度方面:StringBuilder > StringBuffer > String
線上程安全方面:StringBuilder非執行緒安全;StringBuffer執行緒安全
8.過載和重寫的區別
* 過載:一個類的多個方法,方法名相同,而引數不同(引數型別、引數個數不同,返回型別可相同也可不同,引數型別不可作為過載函式的判斷標準)
* 重寫:發生在父子類之間,子類定義的方法與父類擁有相同的名稱和引數,這說明該方法被重寫
9.抽象類和介面有什麼區別
* 抽象類:以abstract描述的類,一般存在未實現的抽象方法,子類繼承抽象類之後,需要實現該抽象方法,如果沒有實現,則可以設定子類也為abstract類
* 介面:介面是一種特殊的抽象類,接口裡的方法全部為抽象方法,子類實現介面後,需要實現這些方法
應用場景:
* 抽象類不能被例項化,只能用作子類的父類,模板模式一般就使用抽象類來實現
* 如果想實現多重繼承,這需要使用介面來實現
10.說說反射的用途及實現
反射作為JDK的一個優秀特性,可作為一種特殊的實現方式來實現對類的操作。
在執行態中,針對於任何一個類,我們能獲取這個類的屬性和方法,並且能呼叫物件的方法。
我們常用的Spring框架就使用了反射,通過使用反射來獲取類的例項;
實現:獲取類的Class物件,可通過Class來獲取類的屬性、方法,並可通過Class物件來建立例項
11.說說自定義註解的場景及實現
我們在使用框架如Spring、Mybatis時都會用到很多註解,註解可以在類上、方法上、成員變數上。
一般來說,使用註解可以為類新增許多附加功能。
Spring的Controller、Service註解,主要就是讓Spring在掃描包下的類的時候,針對於添加了這些註解的類這注冊到Spring容器中
12.HTTP請求的GET與POST方式的區別
HTTP的請求型別有很多種方式,常用的就是GET和POST,其他還有PUT/DELETE/HEAD等
GET:一般用於查詢操作,引數拼接在URL上
POST:一般用於新增或更新操作,引數可作為http請求的body來放入,
可以從安全性、引數傳輸長度等方面來分析其區別
更多可參考: https://www.cnblogs.com/logsharing/p/8448446.html
13.Session與Cookie區別
在常規的Web開發中,經常會使用到Session和Cookie
* Session可被看做是一次會話,當session過期或session關閉的時候會話結束,我們在開發中可以使用session傳遞一些引數
* Cookie是使用在客戶端的,相對而言,session是使用在伺服器端的。最經典的Cookie使用方式是:在Cookie中存放session_id,將Cookie和Session的聯合使用,實現http請求的連續性交易
14.列出自己常用的JDK包
java.lang
java.io
java.nio
java.util
java.util.concurrent
15.MVC設計思想
在Web開發中的一個經典開發思想
model-view-controller
將web專案分成不同的層次,每個層次之間對外提供介面訪問,實現一種高內聚低耦合。
主要要體會到MVC的分層思想,在實際的程式碼開發中需要注意到
16.equals與==的區別
* equals比較的是兩個物件的值是否相同
* == 比較的是兩個物件的物件記憶體地址是否相同
17.hashCode和equals方法的區別與聯絡
hashCode和equals是Object的兩個方法,hashCode主要是為了獲取物件的雜湊值;equals這比較兩個物件是否相等(記憶體地址意義上的相同)
equals方法相等這hashCode一定相等;但是hashCode相等equals方法不一定相等
注意:hashCode和equals方法都是為了比較物件是否相等的,那麼為什麼需要兩個方法了?
equals的比較相對複雜點,而hashCode的比較相對簡單,但是equals的比較更嚴謹,hashCode就不那麼嚴謹了。所以,針對大量的物件比較,如果都用equals比較的話,顯然效率比較低,所以,一般先用hashCode進行比較,如果hashCode不同則兩個物件肯定不同;如果hashCode相同,則再進行equals比較。
使用者一般不需要重寫hashCode和equals方法,如果要重寫的話,這兩個都要重寫
更多可參考https://www.cnblogs.com/keyi/p/7119825.html
18.什麼是Java序列化和反序列化,如何實現Java序列化?或者請解釋Serializable 介面的作用
java序列化:將物件轉換為位元組流的過程
反序列化:將位元組流轉換為物件的過程
序列化的用途:將物件的位元組序列儲存到硬碟上;在網路上傳輸物件的位元組序列。
java實現序列化:物件實現Serializable介面,然後使用流處理操作ObjectInputSteam和ObjectOutputStream來進行序列化操作
19.Object類中常見的方法,為什麼wait notify會放在Object裡邊?
toString()/hashCode()/equals()/clone()
wait方法暫停的是持有物件的鎖,所以要呼叫wait方法必須為object.wait()
同理:notify方法喚醒的是等待鎖的物件,
20.Java的平臺無關性如何體現出來的
最主要的是JDK的部署,JDK扮演了java程式與所在硬體平臺和作業系統之間的緩衝角色。這樣java程式只需要與JDK打交道而不用管具體的作業系統
體現在:我們只需要編寫java程式,如果需要在不同的平臺執行,那麼首先在對應平臺安裝JDK,然後將打包後的應用執行在JDK上即可,與作業系統無關
21.JDK和JRE的區別
JDK包含JRE,JRE是java執行時環境,包含了JVM
JDK不僅僅有JRE,同時還有java原始碼、編譯器javac、java程式除錯工具jconsole等,可以進行開發除錯工作
22.Java 8有哪些新特性
* lambda
* java.util.Stream提供對元素流進行函式式操作
明細見:https://www.oracle.com/technetwork/cn/java/javase/8-whats-new-2157071-zhs.html
Java常見集合
1.List 和 Set 區別
List和Set同為集合型別,父介面都為Collection
List為有序可重複的
Set為無序不可重複的
2.Set和hashCode以及equals方法的聯絡
Set實際就是用Map來實現的,使用的是Map的key,value用一個static final型別的Object來代替
Set的結構為陣列結構,準確點說是雜湊陣列,以值的hashCode來確定所在陣列的index
Set所存的值是不可重複的,為什麼呢?因為Set會使用物件的equals方法進行比較,如果相同,則使用新值替換掉老值
3.List 和 Map 區別
List和Map都是集合型別,List繼承了Collection介面,Map沒有繼承該介面
資料結構不同:List一般是陣列或者連結串列結構;而Map一般是陣列+連結串列的結構或者樹結構
4.Arraylist 與 LinkedList 區別
ArrayList底層是陣列
LinkedList底層是連結串列(雙端連結串列)
5.ArrayList 與 Vector 區別
ArrayList和Vector實現的功能基本保持一致
ArrayList非執行緒安全
Vector的方法都是synchronized,所以執行緒安全
6.HashMap 和 Hashtable 的區別
HashMap和HashTable實現的功能保持一致
HashMap非執行緒安全
HashTable執行緒安全
7.HashSet 和 HashMap 區別
HashSet的實現實際上是基於HashMap的
HashSet使用的就是HashMap的雜湊表來實現的,相對於HashMap而言就是value是固定的為一個static final的Object
8.HashMap 和 ConcurrentHashMap 的區別
HashMap是執行緒非安全的
ConcurrentHashMap是執行緒安全的,相對於HashTable而言,ConcurrentHashMap實現的方式更優雅,採取的是分段鎖的措施
9.HashMap 的工作原理及程式碼實現,什麼時候用到紅黑樹
HashMap的資料結構是雜湊表+連結串列的格式,使用key.hashCode來確定所在雜湊表的位置,然後將value存放在連結串列中
TreeMap是基於紅黑樹實現的,可以實現快速查詢
10.多執行緒情況下HashMap死迴圈的問題
主要發生在HashMap.put()方法時,如果添加當前元素後超過了閾值,則需要擴容,擴容的時候需要將原來的map所有元素都存放到新的map中
如果在多執行緒操作情況下,則有可能引發環形連結的情況
詳細請參考:https://coolshell.cn/articles/9606.html
11.HashMap出現Hash DOS攻擊的問題
主要是將json轉換為map時候,當json過大且map的key被不停的碰撞(hash collision),導致CPU爆滿
12.ConcurrentHashMap 的工作原理及程式碼實現,如何統計所有的元素個數
程序和執行緒
1.執行緒和程序的概念、並行和併發的概念
* 程序:每一個單獨的應用都可以看做一個程序,擁有一個程式執行的入口、順序執行序列和程式的出口
* 執行緒:屬於程序裡的,一個程序可以有多個執行緒,執行緒無法獨立執行,必須已存在應用程式中
執行緒開銷小,但不利於資源的管理和保護;程序正相反。
程序在執行過程中擁有獨立的記憶體單元;而多個執行緒共享記憶體
* 並行:多個任務同時執行
* 併發:也是多工執行,從CPU的角度來看,實際上只有一個任務在執行
2.建立執行緒的方式及實現
* new Thread()
* implements Runnable
3.程序間通訊的方式
* 無名管道通訊(半雙工的通訊方式,資料只能單向流動,而且只能在具有親緣關係[如父子程序]的程序間使用)
* 高階管道通訊(將另一個程式當做一個新程序在當前程序中啟動,則他算是當前程序的子程序)
* 有名管道通訊(半雙工的通訊方式,允許無親緣關係的程序通訊)
* 訊息佇列通訊(訊息佇列是由訊息的連結串列,存放在核心中並有訊息佇列識別符號標識。訊息佇列克服了訊號傳遞資訊少、管道只能承載無格式位元組流以及緩衝區大小受限等缺點)
* 訊號量通訊(訊號量是一個計數器,可以用來控制多個程序對共享資源的訪問,它常作為一種鎖機制,防止某程序正在訪問共享資源時,其他程序也訪問該資源。因此主要作為程序間以及同一程序內不同執行緒之間的同步手段)
* 訊號(訊號是一種比較複雜的通訊方式,用於通知接收程序某個事件已經發生)
* 共享記憶體通訊(共享記憶體就是對映一段能夠被其他程序訪問的記憶體,這段共享記憶體有一個程序建立,但多個程序都可以訪問。共享記憶體是最快的IPC方式,它是針對其他程序通訊方式執行效率低而專門設計的。它往往與其它方式如訊號量等配合使用,來實現程序間的同步和通訊)
* 套接字通訊(套接字也是一種程序通訊方式,與其它方式不同的是:它還可以實現不同伺服器之間的通訊)
4.說說 CountDownLatch、CyclicBarrier 原理和區別
* CountDownLatch閉鎖,相當於一扇門,在門開啟之前,沒有執行緒能夠通過,在達到結束狀態時,這扇門會允許所有的執行緒通過
* CyclicBarrier類似於閉鎖,它能阻止一組執行緒直到某個時間發生
不同點:閉鎖做減法,柵欄做加法,閉鎖只能使用一次,而柵欄可以使用多次
5.說說 Semaphore 原理
計數訊號量,Semaphore管理一系列許可證,每個acquire方法阻塞,直到有一個許可證可以獲得然後拿走一個許可證;每個release方法增加一個許可證
Semaphore經常用於限制獲取某種資源的執行緒數量。
Semaphore有兩種模式:公平模式和非公平模式;公平模式下呼叫acquire的順序就是獲取許可證的順序,遵循FIFO;非公平模式是搶佔式的
6.說說 Exchanger 原理
Exchanger是一個用於執行緒間協作的工具類。用於執行緒間的資料交換,它提供一個同步點,在這個同步點,兩個執行緒可以交換彼此的資料。他提供一個同步點,在這個同步點,兩個執行緒可以交換彼此的資料。這兩個執行緒通過exchange方法來交換資料,如果第一個執行緒先執行exchange方法,它會一直等待第二個執行緒也執行exchange方法,當兩個執行緒達到同步點時,這兩個執行緒就可以交換資料
7.ThreadLocal 原理分析,ThreadLocal為什麼會出現OOM,出現的深層次原理
ThreadLocal為每個執行緒建立一個副本,那麼每個執行緒可以訪問自己內部的副本變數。
注意ThreadLocalMap是每個執行緒所獨有的
OOM:ThreadLocal到Entry物件key的引用斷裂,而不及時的清理Entry物件,可能造成OOM記憶體溢位
8.講講執行緒池的實現原理
執行緒池中的核心執行緒數,當提交一個任務時,執行緒池建立一個執行緒執行任務,直到當前執行緒數等於corePoolSize;
如果當前執行緒數為corePoolSize,那麼繼續提交的任務則儲存到阻塞佇列中,等待被執行;
如果阻塞佇列也滿了,那就建立新的執行緒執行任務,直到當前執行緒數等於maxPoolSize;
如果這時再有任務,則執行reject處理任務
9.執行緒池的幾種實現方式
* newFixedThreadPool()
* newCachedThreadPool()
* newSingleThreadExecutor()
* newScheduledThreadPool()
拒絕策略:
* AbortPolicy 丟棄任務並丟擲RejectException
* DiscardPolicy 丟棄任務,但是不丟擲異常
* DiscardOldestPolicy 丟棄最前面的任務,然後嘗試執行任務(重複此過程)
* CallerRunsPolicy 由呼叫執行緒處理該任務
執行緒池的狀態:
* RUNNING 接受新任務,並處理阻塞佇列中的任務
* SHUTDOWN 不會接受新任務,但會處理阻塞佇列中的任務
* STOP 不接受新任務,也不會處理阻塞佇列中的任務,而且會中斷正在執行的任務
* TIDYING 執行緒池對執行緒進行整理優化
* TERMINATED 執行緒池停止工作
向執行緒池提交任務的兩種方式:
Executor.execute(Runnable command);
ExecutorService.submit(Callable<T> task);
* execute()內部實現
1.首次通過workCountof()獲知當前執行緒池中的執行緒數,
如果小於corePoolSize, 就通過addWorker()建立執行緒並執行該任務;
否則,將該任務放入阻塞佇列;
2. 如果能成功將任務放入阻塞佇列中,
如果當前執行緒池是非RUNNING狀態,則將該任務從阻塞佇列中移除,然後執行reject()處理該任務;
如果當前執行緒池處於RUNNING狀態,則需要再次檢查執行緒池(因為可能在上次檢查後,有執行緒資源被釋放),是否有空閒的執行緒;如果有則執行該任務;
3、如果不能將任務放入阻塞佇列中,說明阻塞佇列已滿;那麼將通過addWoker()嘗試建立一個新的執行緒去執行這個任務;如果addWoker()執行失敗,說明執行緒池中執行緒數達到maxPoolSize,則執行reject()處理任務;
* sumbit()內部實現
會將提交的Callable任務會被封裝成了一個FutureTask物件
FutureTask類實現了Runnable介面,這樣就可以通過Executor.execute()提交FutureTask到執行緒池中等待被執行,最終執行的是FutureTask的run方法;
比較:
兩個方法都可以向執行緒池提交任務,execute()方法的返回型別是void,它定義在Executor介面中, 而submit()方法可以返回持有計算結果的Future物件,它定義在ExecutorService介面中,它擴充套件了Executor介面,其它執行緒池類像ThreadPoolExecutor和ScheduledThreadPoolExecutor都有這些方法。
執行緒池關閉的兩種方式:
* shutdown() 不會立即終止執行緒池,不接受新的任務,等緩衝池中的任務都執行完畢之後 終止 ,執行緒池的狀態變為SHUT_DOWN
* shutdownNow() 立即終止執行緒池,不接受新的任務,打斷正在執行的任務,並且清空任務快取佇列,返回尚未執行的任務,執行緒池的狀態變為STOP
來源: https://www.cnblogs.com/zhaojinxin/p/6668247.html
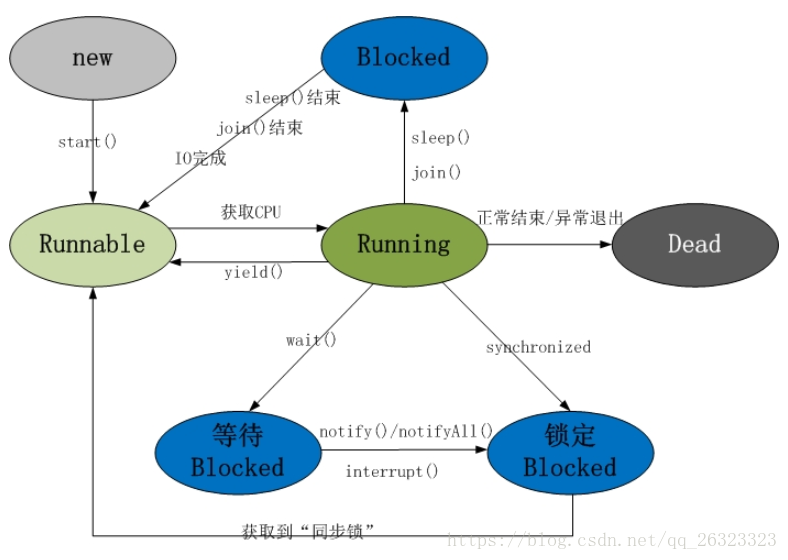
10.執行緒的生命週期,狀態是如何轉移的
生命週期:new/runnable/running/blocked/dead
鎖機制
1.說說執行緒安全問題,什麼是執行緒安全,如何保證執行緒安全
什麼是執行緒安全:當多個執行緒操作一個物件時,這個物件始終表現出正確的行為,那麼稱這個類執行緒安全
執行緒安全問題:多個執行緒同時操作一個可變物件,就有可能發生執行緒安全問題
如何保證執行緒安全:物件設定為final型別;多執行緒操作物件時加鎖
2.重入鎖的概念,重入鎖為什麼可以防止死鎖
重入鎖:如果某個執行緒試圖獲取一個已經有他自己持有的鎖,那麼這個請求就會成功。因為內建鎖是可重入的
重入的實現方式:為每個鎖關聯一個計數器和所有者執行緒。當計數器為0時,說明這個鎖沒有被任何執行緒持有;當執行緒請求一個未被持有的鎖時,JVM將記下鎖的持有者,並將計數器設定為1,如果同一個執行緒再次獲取這個鎖,計數器將遞增;而當執行緒退出同步程式碼塊時,計數器相應的遞減,當計數器為0時,這個鎖將被釋放
防止死鎖:內建鎖可重入,就避免了同一個執行緒再次獲取該鎖的時候,無法獲取的問題
3.產生死鎖的四個條件
* 互斥:某個資源一次只允許一個執行緒訪問
* 佔有且等待:一個執行緒本身佔有資源,同時還等待資源未得到滿足,正在等待其他執行緒釋放該資源
* 不可搶佔:別人已經佔有了某項資源,你不能因為自己的需求,就去把別人的資源搶佔過來
* 迴圈等待:存在一個執行緒鏈,使得每個執行緒都佔有下一個執行緒所需的至少一種資源
4.如何檢查死鎖
jconsole可以關聯相關應用,並檢視死鎖執行緒
jstack pid可以列印棧資訊
如何詳細使用請參考:https://www.cnblogs.com/flyingeagle/articles/6853167.html
5.volatile 實現原理
volatile提示執行緒每次從共享記憶體中讀取變數,而不是從私有記憶體中讀取。這樣就保證了同步資料的可見性
volatile本身並不處理資料的原子性,而是強制對資料的讀寫及時影響到主記憶體中。
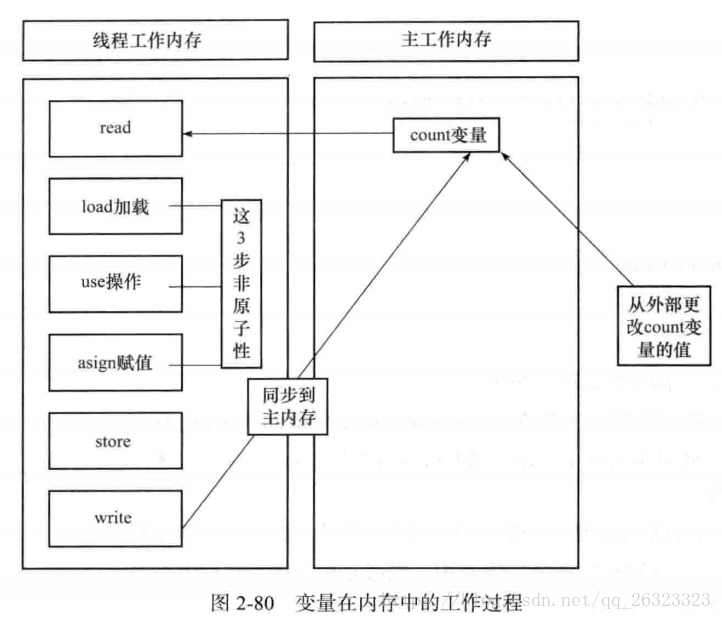
1)過程分析
* read和load階段:從主記憶體複製變數到執行緒記憶體
* use和assign階段:執行程式碼,改變共享變數值
* store和write階段:用工作記憶體資料重新整理主記憶體對應變數的值
2)多執行緒資料髒讀問題分析
在多執行緒環境中,use和assign是多次出現的,但這一操作並不是原子性,也就是在read和load之後,如果主執行緒的資料發生修改,執行緒工作記憶體中的值由於已經載入不會產生對應的變化,也就是私有記憶體和公共記憶體中的變數不同步,所以計算出的結果和預期值不一致,產生髒讀問題。
3)如何理解volatile只保證可見性,不保證原子性?
簡單來說,volatile在多CPU環境下不能保證其他CPU的快取同步重新整理,因此無法保證原子性。以最常用的i++來說吧,包含3個步驟
1:從記憶體中讀取i當前的值
2:加1
3:把修改後的值重新整理到主記憶體
對於普通變數來說,多執行緒下1、2之間被中斷,其他執行緒修改了i的值,那原來在1、2之間被中斷的i的值就已經無效了,所以多執行緒是不安全的
另外對於普通變數來說,步驟1也不是每次都從記憶體中讀取,步驟3也不會每次都保證立即重新整理到主記憶體。所以這裡有兩個問題:可見性和原子性
volatile只保證了可見性,即步驟1每次都重新讀,步驟3每次都立即重新整理到主記憶體。但1、2之間仍然會被中斷,多個執行緒交叉修改,所以仍然不安全。
4)如何保證記憶體可見性?
volatile的記憶體可見性是基於記憶體屏障(Memory Barrier)實現的
記憶體屏障又稱記憶體柵欄,是一個CPU指令,在程式執行時,為了提高程式執行效能,編譯器和處理器會對指令進行重排序,JVM為了保證在不同的編譯器和CPU上有相同的執行結果,通過插入特定型別的記憶體屏障來禁止特定型別的編譯器重排序和處理器重排序,插入一條記憶體屏障會告訴編譯器和CPU:不管什麼指令都不能和這條Memory Barrier指令重排序。
CPU為了提高處理效能,並不直接和記憶體進行通訊,而是將記憶體的資料讀取到記憶體快取(L1、L2)再進行操作,但操作並不能確定何時寫回到記憶體。如果對volatile變數進行寫操作,當CPU執行到lock字首指令時,會將這個變數所在快取行的資料寫回到記憶體。
不過還是有一個問題,就算記憶體資料是最新的,其他快取資料還是舊的,所以為了保證各個CPU快取一致性,各個CPU通過嗅探在總線上傳播的資料來檢查自己快取的資料有效性,當發現自己快取行對應的記憶體地址的資料被修改,就會將該快取行設定為無效狀態,當CPU讀取該變數時,發現所在的快取行資料被設定為無效,就會重新從記憶體中讀取資料到快取中。
6.synchronized 實現原理
我們通過對synchronized修飾的程式碼進行class檔案分析,可以看到,同步程式碼塊是使用monitorenter和monitorexit指令實現的(也就是監視器的進入和監視器的退出)
任何物件都有一個monitor與之相關聯,當且一個monitor被持有之後,他將處於鎖定狀態。執行緒執行到monitorenter指令時,將會嘗試獲取物件所對應的monitor所有權,即嘗試獲取物件的鎖;
具體可見:http://www.importnew.com/23511.html
7.synchronized 與 lock 的區別
synchronized和lock都可以實現鎖的功能;
只是lock比synchronized功能更多一些,synchronized的程式碼不可中斷,如果無法獲取鎖的話也會一直阻塞等待。而lock我們可以使用tryLock來實現規定時間內阻塞的鎖,使用lockIntercupt來實現響應中斷的鎖
8.AQS同步佇列
AQS是抽象的佇列式同步器,AQS定義了一套多執行緒訪問共享資源的同步器框架。許多併發類都基於此實現。如ReentrantLock、Semaphore、CountDownLatch等
AQS使用int成員變數來表示同步狀態,通過內建的FIFO佇列來完成獲取資源執行緒的排隊工作
以兩種方式方式獲取資源:獨佔式、共享式
獨佔式:tryAcquire()/tryRelease()
共享式:tryAcquireShared()/tryReleaseShared()
具體可見:https://www.cnblogs.com/waterystone/p/4920797.html
9.CAS無鎖的概念、樂觀鎖和悲觀鎖
CAS(compare and swap)
對於併發控制而言,鎖是一種悲觀策略,會阻塞執行緒執行。而無鎖是一種樂觀策略,它會假設對資源的訪問時沒有衝突的,執行緒也不需要阻塞。
那麼當多個執行緒共同訪問臨界區的資源時,無鎖策略則採用一種比較交換技術來鑑別執行緒衝突
一個CAS包括三個引數CAS(V,E,N)V表示要更新的變數、E表示預期的值、N表示新值。只有當V的值等於E時,才會將V的值修改為N。如果不相等,說明已經被其他執行緒修改了,當前執行緒可以放棄該次操作,也可繼續嘗試直至修改成功。
相對而言,synchronized就是悲觀鎖,CAS鎖就是樂觀鎖
10.常見的原子操作類
AtomicInteger
AtomicLong
AtomicBoolean
AtomicIntegerArray
11.什麼是ABA問題,出現ABA問題JDK是如何解決的
具體可見https://www.jianshu.com/p/72d02353dc7e
12.樂觀鎖的業務場景及實現方式
樂觀鎖:比較適合讀取比較頻繁的場景
悲觀鎖:比較適合寫入比較頻繁的場景
JDK中的CAS就是樂觀鎖的一種實現方式;
資料庫中使用version來進行update操作也是一個樂觀鎖的實現方式
13.Java 8並法包下常見的併發類
CopyonwriteArrayList
CopyOnWriteArraySet
ConcurrentHashMap
ConcurrentLinkedQueue
ConcurrentLinkedDeque
14.偏向鎖、輕量級鎖、重量級鎖、自旋鎖的概念
* 偏向鎖:目的是消除資料在無競爭情況下的同步源語,進一步提高程式的執行效能。鎖會偏向於第一個獲取她的執行緒,如果在接下來的執行中,該鎖沒有被其他執行緒獲取,那麼持有偏向鎖的執行緒則永遠不需要再進行同步
適用場景:始終只有一個執行緒在執行同步塊,在他沒有執行完釋放鎖之前,沒有其他執行緒去執行同步塊,在鎖無競爭的情況下使用,如果一旦有競爭就升級為輕量級鎖;升級為輕量級鎖的時候需要撤銷偏向鎖,撤銷偏向鎖會導致stop the World操作
* 輕量級鎖:輕量級鎖並不是用來替代重量級鎖的,它的本意是在沒有多執行緒競爭的前提下,減少傳統的重量級鎖使用作業系統互斥量產生的效能消耗。輕量級鎖由偏向鎖升級來的,偏向鎖執行在一個執行緒進入同步塊的情況下,當第二個執行緒加入所競爭的時候,偏向鎖就會升級為輕量級鎖
* 重量級鎖:輕量級和重量級是相對而言的,使用作業系統互斥量來實現的傳統鎖就是重量級鎖。synchronized鎖。當輕量級鎖由兩條以上的執行緒競爭時,那輕量級鎖就不再有效,要膨脹為重量級鎖
* 自旋鎖:如果共享資料的鎖定狀態只會持續很短一段時間,為了這段時間去掛起和恢復執行緒並不值得。那麼等待鎖的執行緒可以先空轉一會等待鎖的釋放而不是直接掛起,這樣的鎖稱為自旋鎖
更多請參考:https://blog.csdn.net/zqz_zqz/article/details/70233767
JVM
1.JVM執行時記憶體區域劃分
jdk6的記憶體區域劃分:程式計數器、方法區、堆、棧、本地方法棧
jdk8中,方法區(也就是永久代)已經不存在了,編譯後的程式碼資料等已經移動到了元空間(metaspace),元空間並沒有處於堆記憶體上,而是直接佔用的本地記憶體(NativeMemory)
2.記憶體溢位OOM和堆疊溢位SOE的示例及原因、如何排查與解決
* 堆記憶體溢位OOM:持有物件過多而無法釋放,再分配記憶體空間的時候就會發生堆記憶體溢位
* 棧溢位:與棧相關的兩個異常
StackOverflowERROR(方法呼叫過深,記憶體不夠新建棧幀)
OutofMemoryError(執行緒太多,記憶體不夠新建執行緒)
3.如何判斷物件是否可以回收或存活
物件的回收是需要達到一定條件的
當一個物件沒有任何GCRoot可以達到的時候,說明該物件已經沒有引用可被回收
可作為GCRoot的物件有:虛擬機器棧中引用的物件;方法去中靜態變數引用的物件;方法區中常量引用的物件;本地方法棧中JNI引用的物件
4.常見的GC回收演算法及其含義
* 標記清除演算法
* 複製演算法
* 標記整理演算法
* 分代收集演算法
5.常見的JVM效能監控和故障處理工具類
jps、jstat、jmap、jinfo、jconsole
6.JVM如何設定引數
-Xmx -Xmn設定堆記憶體大小引數,類似於這種設定方式,可以在應用啟動的時候,新增上這些JVM引數,以限定應用的記憶體使用
更多引數請參考:https://www.cnblogs.com/jianyungsun/p/6911380.html
7.JVM效能調優
可以從以下幾個方法來回答
* 堆記憶體大小、比例設定
* 回收器的選擇
* 年輕代的設定
更多請參考:http://www.jb51.net/article/36964.htm
8.類載入器、雙親委派模型、一個類的生命週期、類是如何載入到JVM中的
* 類載入器:通過一個類的許可權定名來獲取描述此類的二進位制位元組流,這個動作由類載入器實現。這個動作在JVM之外,以便讓應用程式自己來決定如何獲取所需要的類
* 雙親委派模型:從開發人員的角度來看,類載入器可分為:啟動類載入器(BootStrap ClassLoader,載入JAVA_HOME/lib下的jar)、擴充套件類載入器(Extension ClassLoader,載入JAVA_HOME/lib/ext下的jar)、應用程式類載入器(Application ClassLoader,載入使用者類路徑上指定的類庫)
工作原理:一個類載入器收到類載入的請求,他首先不會自己嘗試載入這個類,而是把這個請求委託給父類載入器去執行,每一個層次的類載入器都是如此,只有當父載入器反饋自己無法完成這個載入請求時,子載入器才會嘗試自己去載入
* 類生命週期:載入(Loading)、驗證(Verification)、準備(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)、解除安裝(Unloading)7個階段。其中 驗證 準備 解析3個部分統稱為連線
9.強引用、軟引用、弱引用、虛引用
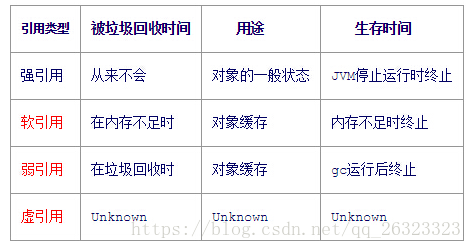
具體可參考:https://www.cnblogs.com/gudi/p/6403953.html