
為什麼Elasticsearch查詢變得這麼慢了?
0、引言
Elasticsearch社群中經常看到慢查詢問題:“你能幫我看看Elasticsearch的響應時間嗎?”或者是:“我的ES查詢耗時很長,我該怎麼做?”
包含但不限於:Nested慢查詢、叢集查詢慢、range查詢慢等問題。

1、兩個維度
每當我們得到這些型別的問題時,我們首先要深入研究兩個主要方面:
- 配置維度 - 檢視當前系統資源和預設Elasticsearch選項。
- 開發維度 - 檢視查詢,其結構以及要搜尋的資料的對映(Mapping)。
我們將首先關注開發方面的問題。 我們將獲得慢查詢,討論DSL查詢語言,並檢視有助於改進Elasticsearch查詢的小型常規選項。
2、開發維度—你的查詢有多慢?
第一步是檢視傳送到群集的查詢所花費的時間。 在研究如何開啟慢速日誌時,Elasticsearch文件可能有點不清楚,因此我將在下面展示一些示例。
- 首先,Elasticsearch中有兩個版本的慢速日誌:索引慢速日誌(index slow logs )和搜尋慢速日誌( search slow logs)。
由於我們試圖解決的問題涉及慢查詢,我們將專注於搜尋慢速日誌。 但是,如果在索引文件/新增文件時問題解決了效能問題,那麼我們將檢視索引慢速日誌。
預設情況下,所有版本的Elasticsearch都會關閉慢速日誌,因此您必須對群集設定和索引設定進行一些更新。
這些示例適用於使用elasticsearch 6.2,但您可以在此處找到所有以前的版本。
只需將$ES_version替換為您正在使用的版本,
例如5.5版本設定官網參考:http://t.cn/E7Hq2NG。
向_cluster API傳送放置請求以定義要開啟的慢速日誌級別:警告,資訊,除錯和跟蹤。 (有關日誌記錄級別的更多資訊參考:http://t.cn/E7Hqc5e。)
curl -XPUT http://localhost:$ES_PORT/_cluster/settings -H ‘Content-Type: application/json’ -d’ { "transient" : { "logger.index.search.slowlog" : "DEBUG", "logger.index.indexing.slowlog" : "DEBUG" } }'
-
所有慢速日誌記錄都在索引級別啟用,因此您可以再次向index _settings API傳送請求以開啟,但如果您每月,每季度等都在滾動更新索引,則還必須新增到索引模板中。
-
將API呼叫調整為索引設定以匹配您想要命中的慢日誌時間閾值。 (您可以設定為0s以分析例項並收集正在傳送的所有查詢,並設定為-1以關閉慢速日誌。)
使用您在_clustersettings中選擇使用的日誌級別設定。 在這個例子中,“DEBUG”。
ES_PORT是一個持久的環境變數。curl -XPUT http://localhost:$ES_PORT/*/_settings?pretty -H 'Content-Type: application/json' -d '{"index.search.slowlog.threshold.query.debug": "-1", "index.search.slowlog.threshold.fetch.debug": "-1",}' -
現在,您需要收集日誌。 每個分片生成慢速日誌並按資料節點收集。 如果您只有一個包含五個主分片的資料節點(這是預設值),您將在慢速日誌中看到一個查詢的五個條目。 由於Elasticsearch中的搜尋發生在每個分片中,因此每個分片都會看到一個。 每個資料節點儲存慢速日誌,預設情況如下
location:/ var / log / elasticsearch / $ClusterID_index_slowlog_query
和 / var / log / elasticsearch / $ClusterID_index_slowlog_fetch。
如您所見,搜尋慢速日誌再次根據搜尋階段分解為單獨的日誌檔案:獲取(fetch)和查詢(query)。
現在我們在日誌中有結果,我們可以拉入一個條目並將其分開。
[2018-05-21T12:35:53,352][DEBUG ][index.search.slowlog.query]
[DwOfjJF] [blogpost-slowlogs][4] took[1s], took_millis[0], types[],
stats[], search_type[QUERY_THEN_FETCH], total_shards[5],
source[{"query":{"match":{"name":{"query":"hello world",
"operator":"OR","prefix_length":0,"max_expansions":50,
"fuzzy_transpositions" :true,"lenient":false,"zero_terms_query":
"NONE","boost":1.0}}},"sort":[{"price": {"order":"desc"}}]}],
在這裡,您看到:
1. 日期
2. 時間戳
3. 日誌級別
4. 慢速型別
5. 節點名稱
6. 索引名稱
7. 分片號
8. 時間花費
9. 查詢的主體(_source>)
一旦我們獲得了我們認為花費的時間太長的查詢,我們就可以使用一些工具來分解查詢:
工具1:Profile API
Profile API提供有關搜尋的資訊頁面,並分解每個分片中發生的情況,直至每個搜尋元件(match/range/match_phrase等)的各個時間。 搜尋越詳細,_profile輸出越詳細。
工具2:The Kibana profiling 工具
這與_profileAPI密切相關。 它提供了各個搜尋元件的完美的視覺化效果表徵各個分解階段以及各階段查詢的時間消耗。 同樣,這允許您輕鬆選擇查詢的問題區域。

3、開發維度—Elasticsearch的查詢原理
現在我們已經確定了一個很慢的查詢,我們通過一個分析器profile來執行它。 但是,檢視單個元件時間結果並未使搜尋速度更快。 怎麼辦?
通過兩個階段(下面)瞭解查詢的工作原理,允許您以從速度和相關性方面獲得Elasticsearch最佳結果的方式重新設計查詢。

3.1 Query階段
- 路由節點接受該查詢。
- 路由節點識別正在搜尋的索引(或多個索引)。
- 路由節點生成一個節點列表,其中包含索引的分片(主要和副本的混合)。
- 路由節點將查詢傳送到節點(上一步節點列表列出的節點)。
- 節點上的分片處理查詢。
- 查詢(預設情況下)對前10個文件進行評分。
- 該列表將傳送迴路由節點。
3.2 fetch階段
獲取階段由路由節點開始,路由節點確定每個分片傳送的50個(5個分片×10個結果)結果中的前10個文件。
路由節點向分片發出對前10個文件的請求。 (可能是包含最高得分文件的一個分片,或者它們可能分散在多個分片中。)
返回列表後,主節點會在查詢響應的_hits部分中顯示文件。
4、開發維度—filter過濾器查詢優化
結果分數是Elasticsearch的關鍵。 通常,當您使用搜索引擎時,您需要最準確的結果。 例如,如果您正在搜尋“蘋果”,您不希望結果包括“蘋果手機”。
Elasticsearch根據您提供的引數對查詢結果進行評分。
雖然查詢相關性不是本篇文章的重點,但重要的是在此提及,因為如果您有快速搜尋需求但結果不是您要查詢的結果,則整個搜尋都是浪費時間。
那麼,你如何加快搜索速度?
4.1 查詢時,使用query-bool-filter組合取代普通query
提高搜尋效能的一種方法是使用過濾器。 過濾後的查詢可能是您最需要的。
首先過濾是很重要的,因為搜尋中的過濾器不會影響文件分數的結果,因此您在資源方面使用很少的資源來將搜尋結果範圍縮小到很小。
使用過濾查詢,結合使用布林匹配,您可以在評分之前搜尋包含X的所有文件,或者不包含Y的所有文件。此外,可以filter是可以被快取的。
過濾器filter查詢不是加速Elasticsearch查詢的唯一方法。
【from騰訊】預設情況下,ES通過一定的演算法計算返回的每條資料與查詢語句的相關度,並通過score欄位來表徵。
但對於非全文索引的使用場景,使用者並不care查詢結果與查詢條件的相關度,只是想精確的查詢目標資料。
此時,可以通過query-bool-filter組合來讓ES不計算score,
並且儘可能的快取filter的結果集,供後續包含相同filter的查詢使用,提高查詢效率。
filter原理推薦閱讀:吃透 | Elasticsearch filter和query的不同
5、開發維度——其他優化
5.1 避免使用script查詢
避免使用指令碼查詢來計算匹配。 推薦:建立索引時儲存計算欄位。
例如,我們有一個包含大量使用者資訊的索引,我們需要查詢編號以“1234”開頭的所有使用者。
您可能希望執行類似“source”的指令碼查詢:“doc [‘num’]。value.startsWith(‘1234’)。”
此查詢非常耗費資源並且會降低整個系統的速度。 合理的建議:考慮在索引時新增名為“num_prefix”的欄位。
然後我們可以查詢“name_prefix”:“1234”。
5.2 避免使用wildcard查詢
主要原因:
wildcard類似mysql中的like,和分詞完全沒有了關係。
出現錯誤:
使用者輸入的字串長度沒有做限制,導致首尾萬用字元中間可能是很長的一個字串。 後果就是對應的wildcard Query執行非常慢,非常消耗CPU。
根本原因:
為了加速萬用字元和正則表示式的匹配速度,Lucene4.0開始會將輸入的字串模式構建成一個DFA (Deterministic Finite Automaton),帶有萬用字元的pattern構造出來的DFA可能會很複雜,開銷很大。
可能的優化方案:
- wildcard query應杜絕使用萬用字元打頭,實在不得已要這麼做,就一定需要限制使用者輸入的字串長度。
- 最好換一種實現方式,通過在index time做文章,選用合適的分詞器,比如nGram tokenizer預處理資料,然後使用更廉價的term query來實現同等的模糊搜尋功能。
- 對於部分輸入即提示的應用場景可以考慮優先使用completion suggester, phrase/term/suggeter一類效能更好,模糊程度略差的方式查詢,待suggester沒有匹配結果的時候,再fall back到更模糊但效能較差的wildcard, regex, fuzzy一類的查詢。
詳盡原理參考:https://elasticsearch.cn/article/171
5.3 合理使用keyword型別
ES5.x裡對數值型欄位做TermQuery可能會很慢。
在ES5.x+裡,一定要注意數值型別是否需要做範圍查詢,看似數值,但其實只用於Term或者Terms這類精確匹配的,應該定義為keyword型別。
典型的例子就是索引web日誌時常見的HTTP Status code。
詳盡原理參考:https://elasticsearch.cn/article/446
5.4 控制欄位的返回
一是:資料建模規劃的時候,在Mapping節點對於僅儲存、是否構建倒排索引通過enabled、index引數進行優化。
二是:_source控制返回,不必要的欄位不需要返回,舉例:採集的原文章詳情內容頁,根據需要決定是否返回。
5.5 讓Elasticsearch幹它擅長的事情
在檢索/聚合結果後,業務系統還有沒有做其他複雜的操作,花費了多少時間?
這塊是最容易忽視的時間耗費擔當。
Elasticsearch顯然更擅長檢索、全文檢索,其他不擅長的事情,儘量不要ES處理。比如:頻繁更新、確保資料的ACID特性等操作。
6、配置維度——核心配置
6.1 節點職責明晰
區分路由節點、資料節點、候選主節點。
路由節點的主要優點是:
- 由於路由節點減少了搜尋和聚合的壓力,因此資料節點上的記憶體壓力略有降低;
- “智慧路由”——因為他們知道所有資料存在的地方,他們可以避免額外的跳躍;“智慧路由”——因為他們知道所有資料存在的地方,他們可以避免額外的跳躍;
- 從架構上講,將路由節點用作叢集的訪問點非常有用,因此您的應用程式無需瞭解詳細資訊。 從架構上講,將路由節點用作叢集的訪問點非常有用,因此您的應用程式無需瞭解詳細資訊。
儘量將主節點與資料節點分開,因為它將減少所有群集的負載。
以下時間開始考慮專用主節點:
- 群集大小開始變得難以駕馭,可能像10個節點或更高?
- 您會看到由於負載導致叢集不穩定(通常由記憶體壓力引起,導致長GC,導致主節點暫時從叢集中退出)您會看到由於負載導致叢集不穩定(通常由記憶體壓力引起,導致長GC,導致主節點暫時從叢集中退出)
分離主節點的主要目的是使“主節點的職責”與負載隔離,因為高負載可能導致長GC,從而導致叢集不穩定。
分離主節點後,一個高負載的叢集只會影響資料節點(顯然仍然不好),但能保證主節點穩定,一旦叢集超載,基本上專門的主節點給你喘息的空間,而不是整個叢集走向崩潰。
另外,與資料節點相比,主節點通常可以非常“輕”。幾GB的RAM,中等CPU,普通磁碟等或許就能滿足需求(需要根據實際業務場景權衡)。
推薦閱讀:http://t.cn/E7HM4ML
6.2 分配合理的堆記憶體
搜尋引擎旨在快速提供答案。 為此,他們使用的大多數資料結構必須駐留在記憶體中。 在很大程度上,他們假設你為他們提供了足夠的記憶。 如果不是這種情況,這可能會導致問題 - 不僅僅是效能問題,還有叢集的可靠性問題。
合理的堆記憶體大小配置建議:宿主機記憶體大小的一半和31GB,取最小值
推薦閱讀:https://blog.csdn.net/laoyang360/article/details/79998974
6.3 設定合理的分片數和副本數
shard數量設定過多或過低都會引發一些問題。
- shard數量過多,則批量寫入/查詢請求被分割為過多的子寫入/子查詢,導致該index的寫入、查詢拒絕率上升;
對於資料量較大的index,當其shard數量過小時,無法充分利用節點資源,造成機器資源利用率不高 或 不均衡,影響寫入/查詢的效率。
對於每個index的shard數量,可以根據資料總量、寫入壓力、節點數量等綜合考量後設定,然後根據資料增長狀態定期檢測下shard數量是否合理。
騰訊基礎架構部資料庫團隊的推薦方案是:
- 對於資料量較小(100GB以下)的index,往往寫入壓力查詢壓力相對較低,一般設定3~5個shard,副本設定為1即可(也就是一主一從,共兩副本)
- 對於資料量較大(100GB以上)的index:一般把單個shard的資料量控制在(20GB~50GB)
讓index壓力分攤至多個節點:可通過index.routing.allocation.totalshardsper_node引數,強制限定一個節點上該index的shard數量,讓shard儘量分配到不同節點上
綜合考慮整個index的shard數量,如果shard數量(不包括副本)超過50個,就很可能引發拒絕率上升的問題,此時可考慮把該index拆分為多個獨立的index,分攤資料量,同時配合routing使用,降低每個查詢需要訪問的shard數量。
——建議參考:https://blog.csdn.net/laoyang360/article/details/78080602
6.4 設定合理的執行緒池和佇列大小
節點包含多個執行緒池,以便改進節點內執行緒記憶體消耗的管理方式。 其中許多池也有與之關聯的佇列,這允許保留掛起的請求而不是丟棄。
search執行緒——用於計數/搜尋/推薦操作。 執行緒池型別為fixed_auto_queue_size,大小為int((available of available_ * 3)/ 2)+ 1,初始佇列大小為1000。
5.X版本之後,執行緒池設定是節點級設定。因此,無法通過群集設定API更新執行緒池設定。
檢視執行緒池的方法:
GET /_cat/thread_pool
6.4 硬體資源的實時監控
排查一下慢查詢時間點的時候,注意觀察伺服器的CPU, load average消耗情況,是否有資源消耗高峰,可以藉助:xpack、cerbero或者elastic-hd工具檢視。
當您遇到麻煩並且群集工作速度比平時慢並且使用大量CPU功率時,您知道需要做一些事情才能使其再次執行。 當Hot Threads API可以為您提供查詢問題根源的必要資訊。 熱執行緒hot thread是一個Java執行緒,它使用高CPU量並執行更長的時間。
Hot Threads API返回有關ElasticSearch程式碼的哪一部分是最耗費cpu或ElasticSearch由於某種原因而被卡住的資訊。
熱執行緒使用方法:
GET /_nodes/hot_threads
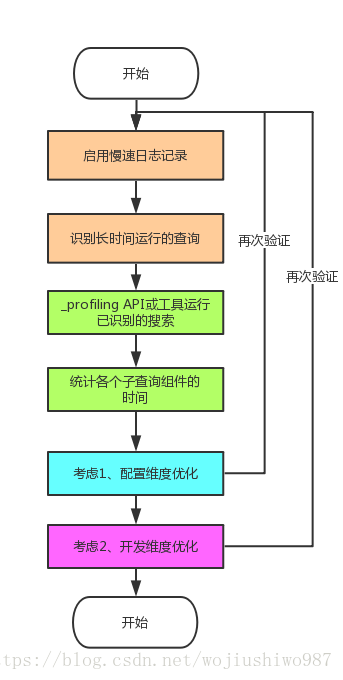
7、小結
回答文章開頭的問題:——為什麼Elasticsearch查詢變得這麼慢了?
和大資料量的業務場景有關,您可以通過幾個簡單的步驟優化查詢:
- 啟用慢速日誌記錄,以便識別長時間執行的查詢
- 通過_profiling API執行已識別的搜尋,以檢視各個子查詢元件的時間通過_profiling API執行已識別的搜尋,以檢視各個子查詢元件的時間
- 過濾,過濾,過濾過濾,過濾,過濾
Elasticsearch優化非一朝一夕之功,需要反覆研究、實踐甚至閱讀原始碼分析。
本文綜合了國外、國內很多優秀的實踐建議,核心點都已經實踐驗證可行。
歡迎大家留言討論!
參考:
http://t.cn/E7HJaPI
http://t.cn/RQSwH4X
http://t.cn/RInoI4c
打造Elasticsearch基礎、進階、實戰第一公眾號!
