
Flask - 資料庫 - 1
1 學習目標
- 能夠理解 ORM 工作原理以及其優缺點
- 能夠寫出在 Flask 中連線 MySQL 的配置項格式(IP,埠,資料庫)
- 能夠使用 SQLAlchemy 定義出關係為一對多模型類
- 能夠使用 SQLAlchemy 的相關函式建立表及刪除表
- 能夠寫出的指定模型資料對資料庫的增刪改程式碼
- 能夠寫出模型資料按照條件查詢的功能邏輯
- 能夠寫出模型資料按照指定數量分頁的功能邏輯
- 能夠寫出模型資料按照指定條件排序的功能邏輯
2 ORM
ORM 全拼 Object-Relation Mapping,文意為主要實現模型物件到關係資料庫資料的對映,比如:把資料庫表中每條記錄對映為一個模型物件。物件-關係對映,
2.1 ORM圖解

優點 :
- 只需要面向物件程式設計,不需要面向資料庫編寫程式碼
- 對資料庫的操作都轉化成對類屬性和方法的操作
- 不用編寫各種資料庫的
sql語句
- 實現了資料模型與資料庫的解耦,遮蔽了不同資料庫操作上的差異
- 不在關注用的是
mysql、oracle...等 - 通過簡單的配置就可以輕鬆更換資料庫,而不需要修改程式碼
- 不在關注用的是
缺點 :
- 相比較直接使用SQL語句操作資料庫,有效能損失
- 根據物件的操作轉換成SQL語句,根據查詢的結果轉化成物件,在對映過程中有效能損失
3 Flask-SQLAlchemy安裝及設定
- SQLALchemy 實際上是對資料庫的抽象,讓開發者不用直接和 SQL 語句打交道,而是通過 Python 物件來操作資料庫,在捨棄一些效能開銷的同時,換來的是開發效率的較大提升
- SQLAlchemy是一個關係型資料庫框架,它提供了高層的 ORM 和底層的原生資料庫的操作。flask-sqlalchemy 是一個簡化了 SQLAlchemy 操作的flask擴充套件。
- 文件地址:http://docs.jinkan.org/docs/flask-sqlalchemy
3.1 安裝
- 安裝 flask-sqlalchemy
pip install flask-sqlalchemy
- 如果連線的是 mysql 資料庫,需要安裝 mysqldb
pip install flask-mysqldb- 在安裝flask-mysqldb的時候可能會報錯:mysql_config not found
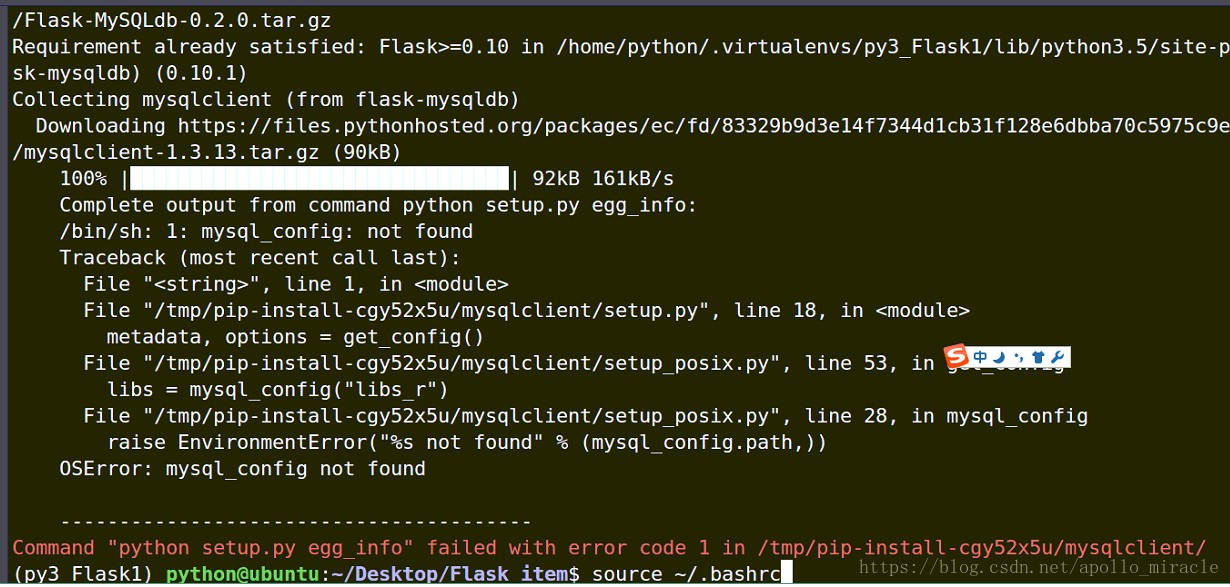
- 解決如下,輸入以下程式碼 :
sudo aptitude install libmysqlclient-dev
3.2 資料庫連線設定
3.2.1 連線 MySQL 資料庫
完整連線 URI 列表請跳轉到 SQLAlchemy 下面的文件 (Supported Databases) 。這裡給出一些 常見的連線字串。
- Postgres:
postgresql://scott:[email protected]/mydatabase
- MySQL:
mysql://scott:[email protected]/mydatabase
- Oracle:
- oracle://scott:[email protected]:1521/sidname
- SQLite (注意開頭的四個斜線):
sqlite:////absolute/path/to/foo.db- 在 Flask-SQLAlchemy 中,資料庫使用URL指定,而且程式使用的資料庫必須儲存到Flask配置物件的 SQLALCHEMY_DATABASE_URI 鍵中
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test'資料庫連線url的說明:
mysql://:是協議
root:使用者名稱
mysql:密碼
127.0.0.1:資料庫所在電腦
3306:資料庫埠號
test:資料庫名
- 其他設定:
# 動態追蹤修改設定,如未設定只會提示警告
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#查詢時會顯示原始SQL語句
app.config['SQLALCHEMY_ECHO'] = True- 配置完成需要去 MySQL 中建立專案所使用的資料庫
mysql -uroot -pmysql
create database test charset utf8;- 其他配置
| 名字 | 備註 |
|---|---|
| SQLALCHEMY_DATABASE_URI | 用於連線的資料庫 URI 。例如:sqlite:////tmp/test.dbmysql://username:[email protected]/db |
| SQLALCHEMY_BINDS | 一個對映 binds 到連線 URI 的字典。更多 binds 的資訊見用 Binds 操作多個數據庫。 |
| SQLALCHEMY_ECHO | 如果設定為Ture, SQLAlchemy 會記錄所有 發給 stderr 的語句,這對除錯有用。(列印sql語句) |
| SQLALCHEMY_RECORD_QUERIES | 可以用於顯式地禁用或啟用查詢記錄。查詢記錄 在除錯或測試模式自動啟用。更多資訊見get_debug_queries()。 |
| SQLALCHEMY_NATIVE_UNICODE | 可以用於顯式禁用原生 unicode 支援。當使用 不合適的指定無編碼的資料庫預設值時,這對於 一些資料庫介面卡是必須的(比如 Ubuntu 上 某些版本的 PostgreSQL )。 |
| SQLALCHEMY_POOL_SIZE | 資料庫連線池的大小。預設是引擎預設值(通常 是 5 ) |
| SQLALCHEMY_POOL_TIMEOUT | 設定連線池的連線超時時間。預設是 10 。 |
| SQLALCHEMY_POOL_RECYCLE | 多少秒後自動回收連線。這對 MySQL 是必要的, 它預設移除閒置多於 8 小時的連線。注意如果 使用了 MySQL , Flask-SQLALchemy 自動設定 這個值為 2 小時。 |
3.2.2 連線其他資料庫
完整連線 URI 列表請跳轉到 SQLAlchemy 下面的文件 (Supported Databases) 。這裡給出一些 常見的連線字串。
- Postgres:
postgresql://scott:[email protected]/mydatabase
- MySQL:
mysql://scott:[email protected]/mydatabase
- Oracle:
- oracle://scott:[email protected]:1521/sidname
- SQLite (注意開頭的四個斜線):
sqlite:////absolute/path/to/foo.db3.2.3 常用的SQLAlchemy欄位型別
| 型別名 | python中型別 | 說明 |
|---|---|---|
| Integer | int | 普通整數,一般是32位 |
| SmallInteger | int | 取值範圍小的整數,一般是16位 |
| BigInteger | int或long | 不限制精度的整數 |
| Float | float | 浮點數 |
| Numeric | decimal.Decimal | 普通整數,一般是32位 |
| String | str | 變長字串 |
| Text | str | 變長字串,對較長或不限長度的字串做了優化 |
| Unicode | unicode | 變長Unicode字串 |
| UnicodeText | unicode | 變長Unicode字串,對較長或不限長度的字串做了優化 |
| Boolean | bool | 布林值 |
| Date | datetime.date | 時間 |
| Time | datetime.datetime | 日期和時間 |
| LargeBinary | str | 二進位制檔案 |
3.2.4 常用的SQLAlchemy列選項
| 選項名 | 說明 |
|---|---|
| primary_key | 如果為True,代表表的主鍵 |
| unique | 如果為True,代表這列不允許出現重複的值 |
| index | 如果為True,為這列建立索引,提高查詢效率 |
| nullable | 如果為True,允許有空值,如果為False,不允許有空值 |
| default | 為這列定義預設值 |
3.2.5 常用的SQLAlchemy關係選項
| 選項名 | 說明 |
|---|---|
| backref | 在關係的另一模型中新增反向引用 |
| primary join | 明確指定兩個模型之間使用的聯結條件 |
| uselist | 如果為False,不使用列表,而使用標量值 |
| order_by | 指定關係中記錄的排序方式 |
| secondary | 指定多對多關係中關係表的名字 |
| secondary join | 在SQLAlchemy中無法自行決定時,指定多對多關係中的二級聯結條件 |
3.2.6 SQLAlchemy使用操作
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 配置資料庫連線地址
app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://root:[email protected]:3306/test_27"
# 是否追蹤資料庫的修改
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
@app.route("/")
def index():
return "index"
if __name__ == '__main__':
app.run(debug=True)SQLAlchemy常用配置就這兩個:uri 和 track_modifications
4 資料庫基本操作
在Flask-SQLAlchemy中,插入、修改、刪除操作,均由資料庫會話管理。
- 會話用 db.session 表示。在準備把資料寫入資料庫前,要先將資料新增到會話中然後呼叫 commit() 方法提交會話。
在 Flask-SQLAlchemy 中,查詢操作是通過 query 物件操作資料。
- 最基本的查詢是返回表中所有資料,可以通過過濾器進行更精確的資料庫查詢。
4.1 新增模型&增刪改
4.1.1 準備工作
通過物件操作資料庫,那麼首先需要建立資料庫 test:
create database test charset utf8;進入看一眼,目前還沒有表:
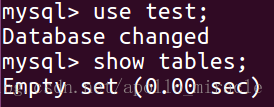
4.1.2 新增模型
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 配置資料庫連線地址
app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://root:[email protected]:3306/test"
# 是否追蹤資料庫的修改
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
class Role(db.Model):
# 指定該模型對應資料庫中的表名,如果不指定,表名就為類名小寫,即“role”
__tablename__ = "roles"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return "Role: %s %s" % (self.id, self.name)
@app.route("/")
def index():
return "index"
if __name__ == '__main__':
db.create_all()
app.run(debug=True)
程式碼說明:
__repr__ :類似於__str__,列印Role例項物件的時候會呼叫__repr__
db.create_all():建立所有繼承 db.Model 的模型對應的資料庫表
接下來執行此程式,然後查看錶:
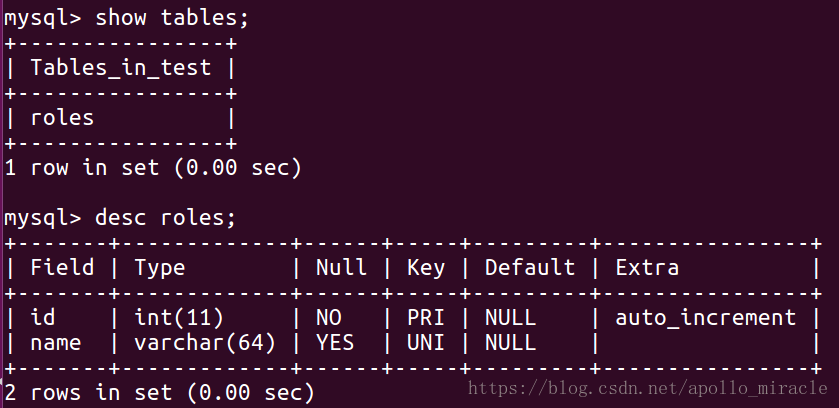
4.1.3 增加
通過 pycharm 的 terminal 進入 ipython3,輸入如下程式碼:
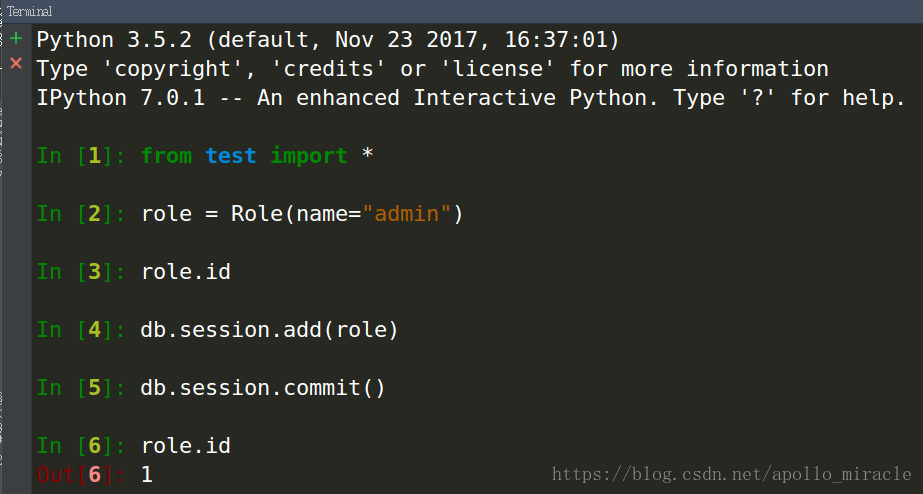
增加資料,需要新建Role例項物件,並且新增到db.session中,最終還要commit提交才可以
注意:
這裡的session(會話)跟檢視中操作的session不一樣,這裡他是自己做了一個會話,可以將多個數據庫操作一次性新增到會話中,最終commit一次即可
commit之後,role.id竟然有值了,這是因為插入成功之後,資料庫有了id值,然後SQLAlchemy給資料庫的改變反饋到了例項物件role上了,所以role.id有值了
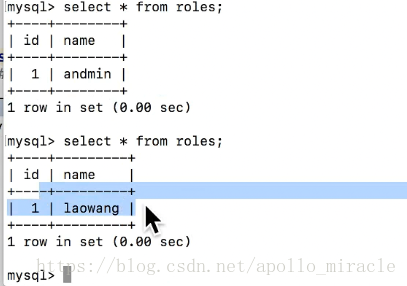
插入成功之後,查詢資料庫:(插入之前沒有資料,插入之後有一條資料)

4.1.4 修改
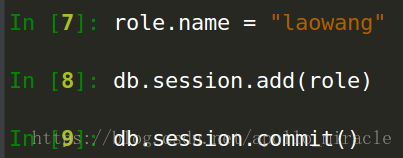
注意:
這裡的修改操作也應該通過db.session.add(role)來處理,但是因為上邊增加操作已經將role 新增到db.session中了。所以這裡可以省略第二步。(其實建議再寫一遍,這樣更規範)
4.1.5 刪除
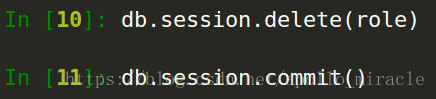
注意:刪除操作是通過db.session.delete()來處理的

4.2 資料庫一對多的關係定義
4.2.1 準備工作
接下來我們討論一下多表的關係:一對多關係
那麼就需要增加一個模型類User,Role 與 User 的關係是一對多。
增加User如下:
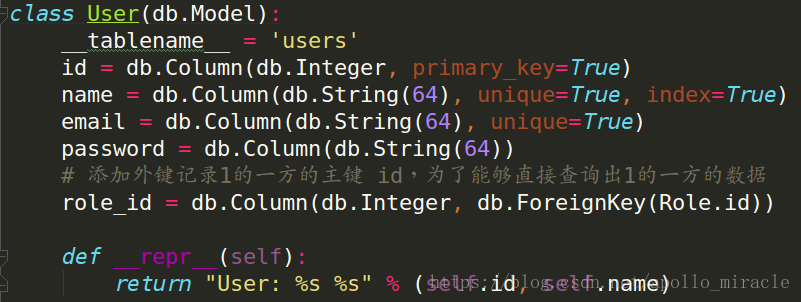
增加測試資料:
if __name__ == '__main__':
db.drop_all()
db.create_all()
# 插入一條資料
ro1 = Role(name='admin')
db.session.add(ro1)
db.session.commit()
# 再次插入一條資料
ro2 = Role(name='user')
db.session.add(ro2)
db.session.commit()
# 一次插入多條資料
us1 = User(name='wang', email='[email protected]', password='123456', role_id=ro1.id)
us2 = User(name='zhang', email='[email protected]', password='201512', role_id=ro2.id)
us3 = User(name='chen', email='[email protected]', password='987654', role_id=ro2.id)
us4 = User(name='zhou', email='[email protected]', password='456789', role_id=ro1.id)
us5 = User(name='tang', email='[email protected]', password='158104', role_id=ro2.id)
us6 = User(name='wu', email='[email protected]', password='5623514', role_id=ro2.id)
us7 = User(name='qian', email='[email protected]', password='1543567', role_id=ro1.id)
us8 = User(name='liu', email='[email protected]', password='867322', role_id=ro1.id)
us9 = User(name='li', email='[email protected]', password='4526342', role_id=ro2.id)
us10 = User(name='sun', email='[email protected]', password='235523', role_id=ro2.id)
db.session.add_all([us1, us2, us3, us4, us5, us6, us7, us8, us9, us10])
db.session.commit()
app.run(debug=True)
問題:
- 為啥create_all()之前要先drop_all()?
因為執行已經生成過Role表了,現在如果重新建立,肯定會報錯,所以先刪除所有表,在重新建立
- 為啥ro1和ro2新增到db.session之後,要立馬commit,不能和user一起commit麼?
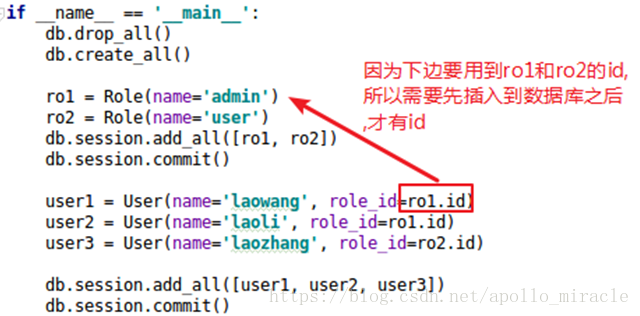
執行,生成表和資料:
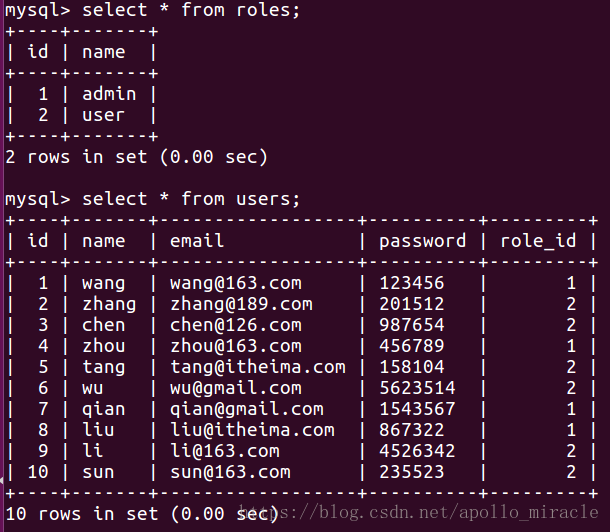
4.2.2 關聯查詢
進入ipython3,我們來看一下一對多查詢:

說明:
all 返回兩個使用者的列表,列表中的每一項是一個role物件;
為啥是Role 1 admin,這是因為__repr__方法就是這樣返回的
我們先執行如下程式碼:
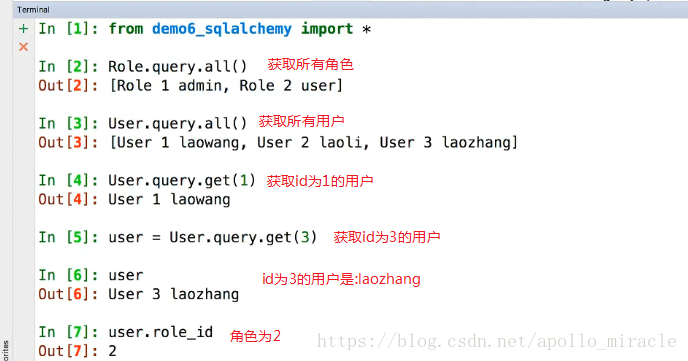
然後獲取id3的使用者的角色資訊:

你會發現這樣查詢很麻煩,需要先通過id3查詢到user,然後在查詢user身上的role_id角色id,在通過角色id查詢Role表才可以知道。那我們暢想一下:
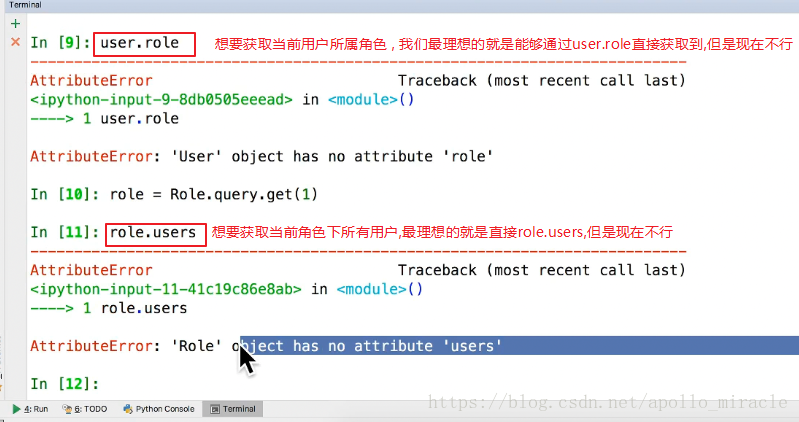
如何實現暢想呢?給Role新增一個關係屬性users:
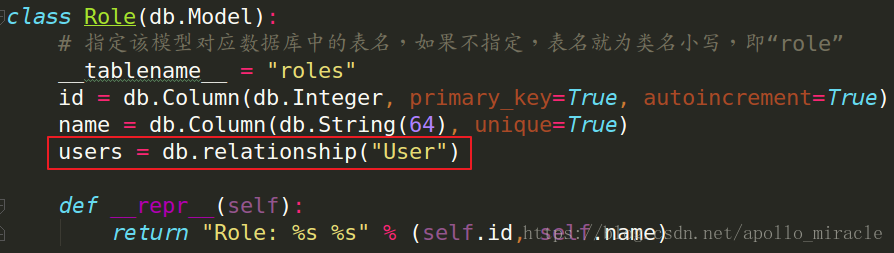
上圖程式碼說明:users屬性關聯著User模型類
接下來查詢:
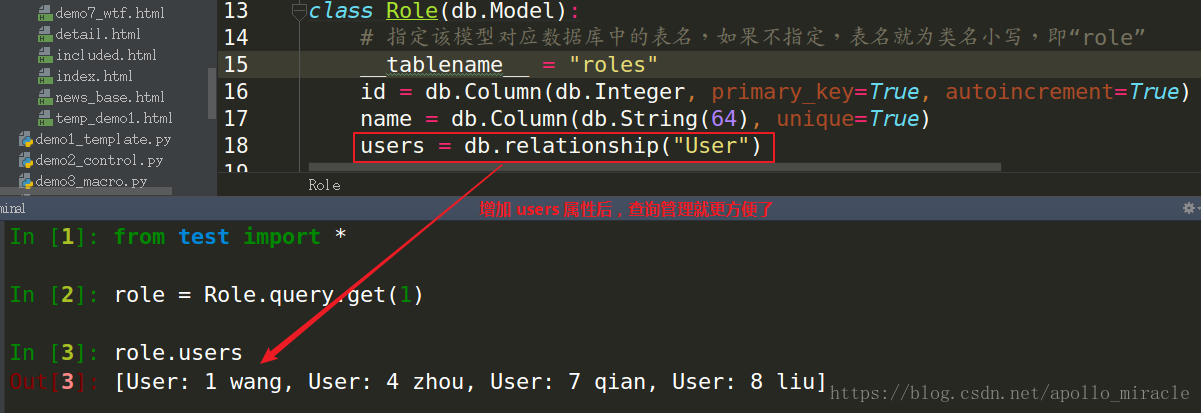
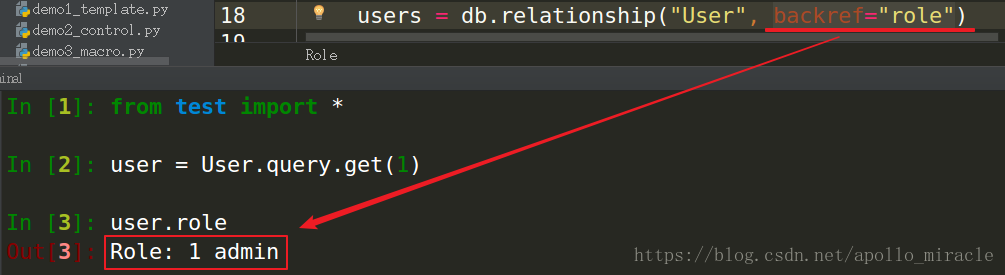
那麼想查詢使用者所屬角色怎麼辦?在後邊加上一句:backref("role")
users = db.relationship("User", backref="role")查詢:
4.3 資料庫的簡單查詢
4.3.1 常用的SQLAlchemy查詢過濾器
| 過濾器 | 說明 |
|---|---|
| filter() | 把過濾器新增到原查詢上,返回一個新查詢 |
| filter_by() | 把等值過濾器新增到原查詢上,返回一個新查詢 |
| limit | 使用指定的值限定原查詢返回的結果 |
| offset() | 偏移原查詢返回的結果,返回一個新查詢 |
| order_by() | 根據指定條件對原查詢結果進行排序,返回一個新查詢 |
| group_by() | 根據指定條件對原查詢結果進行分組,返回一個新查詢 |
4.3.2 常用的SQLAlchemy查詢執行器
| 方法 | 說明 |
|---|---|
| all() | 以列表形式返回查詢的所有結果 |
| first() | 返回查詢的第一個結果,如果未查到,返回None |
| first_or_404() | 返回查詢的第一個結果,如果未查到,返回404 |
| get() | 返回指定主鍵對應的行,如不存在,返回None |
| get_or_404() | 返回指定主鍵對應的行,如不存在,返回404 |
| count() | 返回查詢結果的數量 |
| paginate() | 返回一個Paginate物件,它包含指定範圍內的結果 |
4.3.3 牛刀小試
接下來我們給下邊的所有題目做完即可:
查詢所有使用者資料
查詢有多少個使用者
查詢第1個使用者
查詢id為4的使用者[3種方式]
查詢名字結尾字元為g的所有資料[開始/包含]
查詢名字不等於wang的所有資料[2種方式]
查詢名字和郵箱都以 li 開頭的所有資料[2種方式]
查詢password是 `123456` 或者 `email` 以 `itheima.com` 結尾的所有資料
查詢id為 [1, 3, 5, 7, 9] 的使用者列表
查詢name為liu的角色資料
查詢所有使用者資料,並以郵箱排序
每頁3個,查詢第2頁的資料答案如下:
In [1]: from test import *
In [2]: User.query.all()
Out[2]:
[User: 1 wang,
User: 2 zhang,
User: 3 chen,
User: 4 zhou,
User: 5 tang,
User: 6 wu,
User: 7 qian,
User: 8 liu,
User: 9 li,
User: 10 sun]
In [3]: User.query.count()
Out[3]: 10
In [4]: User.query.first()
Out[4]: User: 1 wang
In [5]: User.query.get(4)
Out[5]: User: 4 zhou
In [6]: User.query.filter_by(id=4).first()
Out[6]: User: 4 zhou
In [7]: User.query.filter(User.id==4).first()
Out[7]: User: 4 zhou
In [10]: User.query.filter(User.name.endswith("g")).all()
Out[10]: [User: 1 wang, User: 2 zhang, User: 5 tang]
In [11]: User.query.filter(User.name.endswith("g")).all()
Out[11]: [User: 1 wang, User: 2 zhang, User: 5 tang]
In [12]: User.query.filter(User.name.startswith("g")).all()
Out[12]: []
In [13]: User.query.filter(User.name.contains("g")).all()
Out[13]: [User: 1 wang, User: 2 zhang, User: 5 tang]
In [14]: User.query.filter(User.name != "wang").all()
Out[14]:
[User: 2 zhang,
User: 3 chen,
User: 4 zhou,
User: 5 tang,
User: 6 wu,
User: 7 qian,
User: 8 liu,
User: 9 li,
User: 10 sun]
In [17]: from sqlalchemy import not_
In [18]: User.query.filter(User.name != "wang").all()
Out[18]:
[User: 2 zhang,
User: 3 chen,
User: 4 zhou,
User: 5 tang,
User: 6 wu,
User: 7 qian,
User: 8 liu,
User: 9 li,
User: 10 sun]
In [19]: from sqlalchemy import not_
In [20]: User.query.filter(not_(User.name == "wang")).all()
Out[20]:
[User: 2 zhang,
User: 3 chen,
User: 4 zhou,
User: 5 tang,
User: 6 wu,
User: 7 qian,
User: 8 liu,
User: 9 li,
User: 10 sun]
In [21]: User.query.filter(User.name.startswith("li"), User.email.startswith("li")).all()
Out[21]: [User: 9 li, User: 8 liu]
In [22]: from sqlalchemy import and_
In [23]: User.query.filter(and_(User.name.startswith("li"), User.email.startswith("li"))).all()
Out[23]: [User: 9 li, User: 8 liu]
In [24]: from sqlalchemy import or_
In [25]: User.query.filter(or_(User.password == "123456", User.email.endswith("itheima.com"))).all
...: ()
Out[25]: [User: 1 wang, User: 5 tang, User: 8 liu]
In [26]: User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()
Out[26]: [User: 1 wang, User: 3 chen, User: 5 tang, User: 7 qian, User: 9 li]
In [28]: User.query.filter(User.name == "liu").first().role
Out[28]: Role: 1 admin
In [29]: User.query.order_by(User.email).all()
Out[29]:
[User: 3 chen,
User: 9 li,
User: 8 liu,
User: 7 qian,
User: 10 sun,
User: 5 tang,
User: 1 wang,
User: 6 wu,
User: 2 zhang,
User: 4 zhou]
In [30]: User.query.order_by(User.email.desc()).all()
Out[30]:
[User: 4 zhou,
User: 2 zhang,
User: 6 wu,
User: 1 wang,
User: 5 tang,
User: 10 sun,
User: 7 qian,
User: 8 liu,
User: 9 li,
User: 3 chen]
In [31]: User.query.order_by(User.email.asc()).all()
Out[31]:
[User: 3 chen,
User: 9 li,
User: 8 liu,
User: 7 qian,
User: 10 sun,
User: 5 tang,
User: 1 wang,
User: 6 wu,
User: 2 zhang,
User: 4 zhou]
In [34]: paginate = User.query.paginate(2, 3)
In [35]: paginate.items
Out[35]: [User: 4 zhou, User: 5 tang, User: 6 wu]
In [36]: paginate.pages
Out[36]: 4
In [37]: paginate.page
Out[37]: 2