
我的人工智慧之旅——線性迴歸
本文將涉及以下知識點
(1)線性關係
(2)線性迴歸
(3)假設函式
(4)代價函式
(5)學習速率
(6)梯度下降
(7)特徵向量
相關的線性代數或微積分知識,可參照另兩篇博文
以下是正文。
線性關係
解釋線性迴歸之前,先來看一下線性關係。
什麼是線性關係?如果自變數與因變數存在一次方函式關係,那麼就成自變數與因變數存線上性關係。例如
y=2x+3 //x為自變數,y為因變數
y=2j+3k+i //j,k,i為自變數,y為因變數但需要注意的是,類似
y=zx //z,x為自變數,y為因變數就不是線性關係。
線性關係還必須滿足以下條件
線性迴歸
所謂線性迴歸,就是利用數理統計中的迴歸分析,來確定兩種或兩種以上變數間,相互依賴的定量關係的一種統計分析方法。
即由樣本(x,y),推斷y=ax+b的過程。其中a,b為需要推斷的常量。那麼,問題來了。
(1)為什麼是"y=ax+b"型的一元一次結構?而非其它一元N次結構?
(2)如何推算出a,b?
假設函式
先來回答上一小節的問題(1)。可以使用其它一元N次結構。選擇一元一次結構只是為了方便。之後的學習,可以換為更復雜的擬合結構。由於我們假設x,y之間存在"y=ax+b"型的對映關係,所以函式f(x)=ax+b被稱為假設函式,hypothesis function。
對於假設函式中的引數a,b,我們沒有辦法直接算出正確的值。也無法讓所有樣本,都對映到假設函式上。因此,只能推算出對於樣本集合整體來說,最佳的a,b取值。
代價函式
如何評斷引數a,b最佳?最佳a,b應使得假設函式求得的資料,與實際資料之間誤差的平方和為最小。
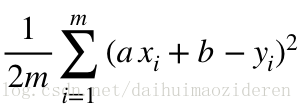
注:關於為何使用1/2m,而非1/m,我們在下一小節說明。
由於樣本集中的每個樣本(x,y)已知,算式中a和b成為了變數,算式可以看作是a,b作為變數的函式。即
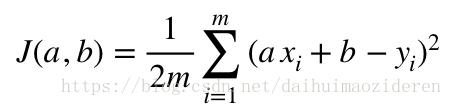
該函式,被稱為代價函式,cost function,或者平方誤差代價函式,squared error cost function。
有了代價函式,推算a,b的問題就演化為,求代價函式何時取到最小值的問題。
當然,除了平方誤差代價函式外,還存在其它代價函式。只是平方誤差代價函式,是解決線性迴歸問題最常用的手段罷了。
但不管使用何種代價函式,我們的目的終歸是要推算最佳的a,b。那麼,如何推算呢?
梯度下降演算法
梯度下降演算法,gradient descent,用於求函式的最小值。該演算法運用了微積分(claculus)中的導數(derivatives)或偏導數(partial derivatives)知識。
簡單的說,導數體現了自變數在變化時,對因變數所產生的影響。若存在多個自變數,那麼對其中一個變數進行的求導,即為偏導數。換句話說,一個自變數在變化時,對因變數和其它自變數鎖產生的影響。
若某一點的導數大於0,那麼說明,因變數隨自變數增大而增大,隨自變數減小而減小。若小於0,則因變數隨自變數的增大而減小,隨自變數減小而增大。依據該特性,我們不斷地同時更新a,b的取值,直至(a,b)所對應的點導數為0。那麼,如何更新呢?
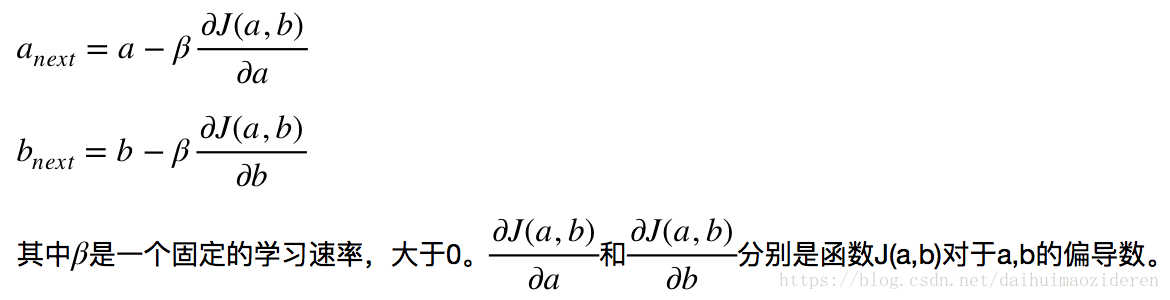
我們將J(a,b)帶入,來看一下運算過程。
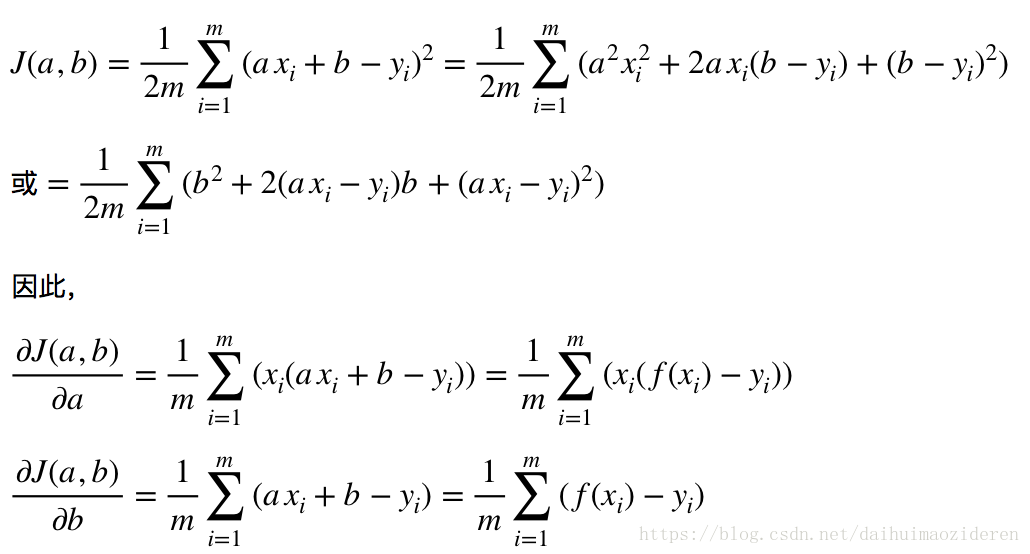
還記得上一節的“1/2m”or“1/m”的疑問嗎?通過運算,“1/2”被約掉。因此,代價函式之所以取“1/2m”作為引數,是為來運算方便。
將導數結果帶入,通過不斷的迭代嘗試獲取和
,直至兩者的偏導數為0或接近0。此時,得到的a,b的值,即為最佳值(全域性最佳,或區域性最佳)。
需要注意的是,由於受限於樣本集合的大小,該最佳值可能為區域性最佳值。
此外,初始點的選取,也將影響最佳值的推算。
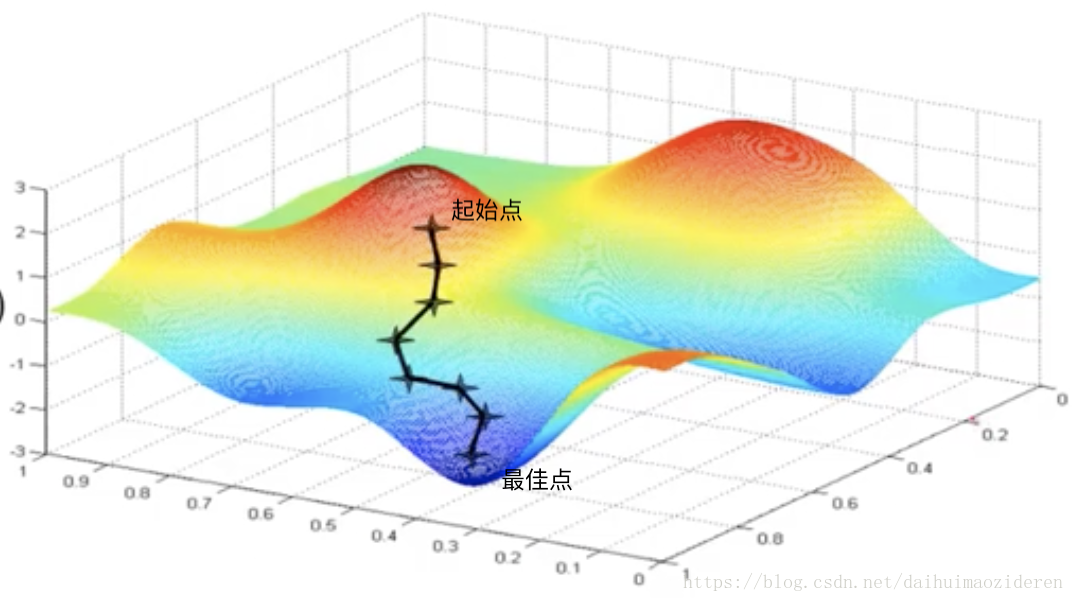
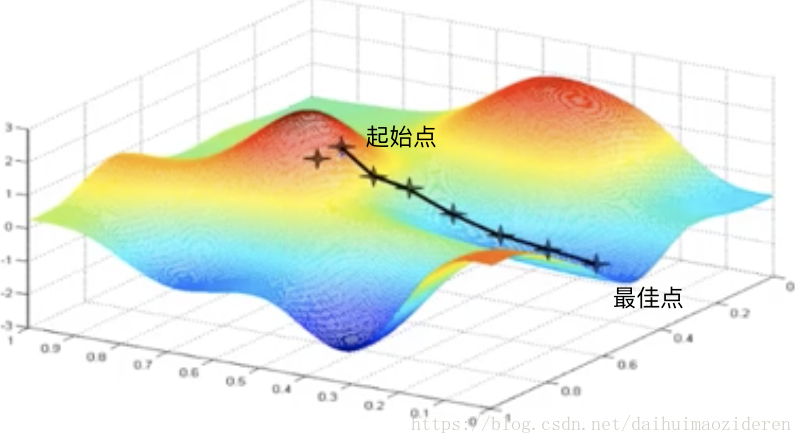
可見,梯度下降演算法其實是一步一步的試出了對於樣本集合最佳的a,b取值。有了a,b的估值,假設函式的真容也便浮出水面了。
梯度下降,並非唯一的推算最佳引數的方法。其它常用方法還包括,BFGS演算法,L-BFGS演算法,共軛梯度法(Conjugate Gradient)等。這些方法遠比梯度下降法複雜的多,但優點在於,它們不用人為的選擇學習率,甚至可以每次迭代自動使用更優的學習率,因此收斂速度較梯度下降更快。由於篇幅及範圍的原因,此處暫不過多涉及。
多元線性迴歸
至此,我們其實還是在討論一元一次的簡單假設,即一個自變數和一個因變數的情況。但實際遇到的問題並非如此簡單。例如,房子的價值,不僅僅與面積有關,還要參考樓層,房齡,房間數量等多重因素,即多元線性迴歸的問題。
那麼,我們的假設函式也相應發生了變化。
這裡,我麼把引數都變為了,自變數變為了
(例如,
分別代表樓層,房齡,房間數量,
預設為1)。之所以這樣表示,是為了方便矩陣的引入。根據矩陣內積(矩陣與向量的乘法),
可以表述為
若假設向量,向量
,那麼,向量A的轉置
=
則假設函式轉化為,其中
稱為特徵(feature),X稱為特徵向量(feature vector)。
解決多元線性迴歸的問題,我們同樣使用梯度下降演算法,即我們要推算出合適的A。而推算過程,我們已在上一小節進行了描述。那麼,套用之前的公式,可得到代價函式,
(j=0,1,2,3)的迭代演算法則為
其中
當j=0,1,2,3時,各偏導數為
由於,所以
最終,引數向量A中的元素的迭代演算法為
小結
線性迴歸,可分為一元或多元線性迴歸。通過構建合理的假設函式和代價函式,利用梯度下降演算法,迭代推算出對於樣本集合來說,最佳的引數或引數向量。希望通過本文的敘述,使得大家對推算過程,線性回顧問題的解決思路,有一個大致的瞭解。