
VGG-Net論文解析
目錄
@
0. 論文連結
1. 概述
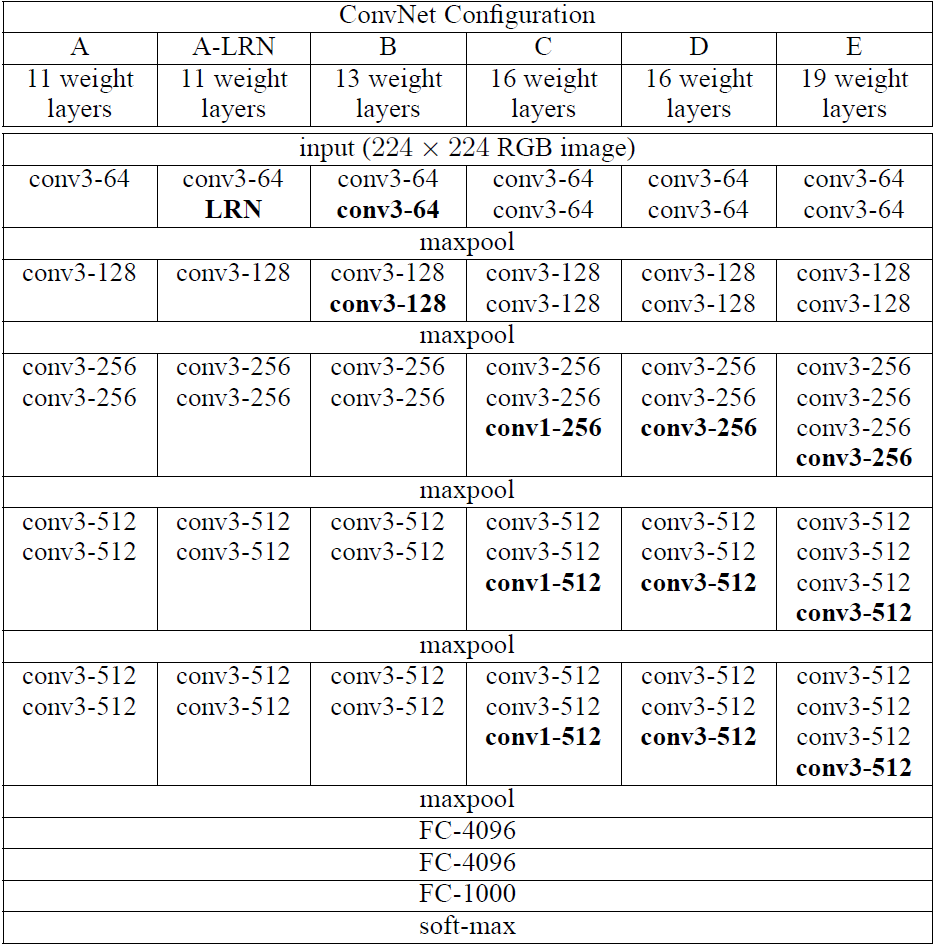
VGG提出了相對AlexNet更深的網路模型,並且通過實驗發現網路越深效能越好(在一定範圍內)。在網路中,使用了更小的卷積核(3x3),stride為1,同時不單單的使用卷積層,而是組合成了“卷積組”,即一個卷積組包括2-4個3x3卷積層(a stack of 3x3 conv),有的層也有1x1卷積層,因此網路更深,網路使用2x2的max pooling,在full-image測試時候把最後的全連線層(fully-connected)改為全卷積層(fully-convolutional net),重用訓練時的引數,使得測試得到的全卷積網路因為沒有全連線的限制,因而可以接收任意寬或高為的輸入,另外VGGNet卷積層有一個顯著的特點:特徵圖的空間解析度單調遞減,特徵圖的通道數單調遞增,這是為了更好地將HxWx3(1)的影象轉換為1x1xC的輸出,之後的GoogLeNet與Resnet都是如此。另外上圖後面4個VGG訓練時引數都是通過pre-trained 網路A進行初始賦值。上圖為VGG不同版本的網路模型,較為流行的是VGG-16,與VGG-19。
另外在某篇部落格看到一段對VGG-Net與GoogLe-Net的總結,摘取至此(會在最後的參考連結給出引用):
GoogLeNet和VGG的Classification模型從原理上並沒有與傳統的CNN模型有太大不同。大家所用的Pipeline也都是:訓練時候:各種資料Augmentation(剪裁,不同大小,調亮度,飽和度,對比度,偏色),剪裁送入CNN模型,Softmax,Backprop。測試時候:儘量把測試資料又各種Augmenting(剪裁,不同大小),把測試資料各種Augmenting後在訓練的不同模型上的結果再繼續Averaging出最後的結果。
2. 網路結構
2.1 卷積核
使用3x3小卷積核,是能夠獲取上下左右中心資訊的最小卷積核,同時在某些“卷積組”使用1x1卷積核,stride=1,padding=1(為了保證卷積層後像素保持不變),2個3x3卷積層堆疊起來相當於一個5x5卷積層,3個3x3卷積層堆疊起來相當於一個7x7卷積層。但一些3x3卷積層堆疊起來與直接一個7x7卷積層有什麼好處呢?作者給出瞭如下幾個理由:
- 相當於組合了3個非線性修正層而不是隻有一個,這樣使得決策函式識別性更強。
- 減少了引數的數量,假設有C個3x3卷積組,那麼引數各位為:\(3(3^2C^2) = 27C^2\),而C個7x7卷積層他的引數為\(7^2C^2 = 49C^2\)
- 小卷積核代替大卷積核的正則作用帶來效能提升。作者用三個conv3x3代替一個conv7x7,認為可以進一步分解(decomposition)原本用7x7大卷積核提到的特徵,這裡的分解是相對於同樣大小的感受野來說的。
1x1卷積核是在保持空間維度不變的情況下,進行了一個線性對映並且多加上了一層非線性修正層,是一種增加決策函式“非線性”(non-linearity)而不影響卷積層感受野的方式。
2.2 池化核
相對於AlexNet使用的3x3池化核,VGG使用2x2池化核,stride為2的max pooling,從而獲取更細節的資訊。
2.3 全連線層
VGG最後三個全連線層在形式上完全平移AlexNet的最後三層,VGGNet後面三層(三個全連線層)為:
- FC4096-ReLU6-Drop0.5,FC為高斯分佈初始化(std=0.005),bias常數初始化(0.1)
- FC4096-ReLU7-Drop0.5,FC為高斯分佈初始化(std=0.005),bias常數初始化(0.1)
- FC1000(最後接SoftMax1000分類),FC為高斯分佈初始化(std=0.005),bias常數初始化(0.1)
在某個測試階段(whole-image)作者將FC層利用conv層代替,如下圖(上半部分是訓練階段,此時最後三層都是全連線層(輸出分別是4096、4096、1000),下半部分是測試階段(輸出分別是1x1x4096、1x1x4096、1x1x1000),最後三層都是卷積層):
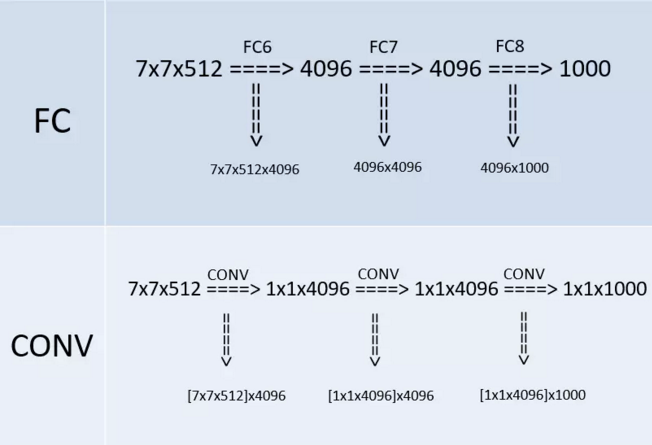
改變之後,整個網路由於沒有了全連線層,網路中間的feature map不會固定,所以網路對任意大小的輸入都可以處理。
3. 訓練
ps:以下來自翻譯,因為剛入門,對於訓練/測試模型的一些操作還不是很熟悉,所以直接翻譯了,積累一些訓練方法跟trick。
ConvNet訓練過程通常遵循Krizhevsky等人(2012)(除了從多尺度訓練影象中對輸入裁剪影象進行取樣外,如下文所述)。也就是說,通過使用具有動量的小批量梯度下降(基於反向傳播(LeCun等人,1989))優化多項式邏輯迴歸目標函式來進行訓練。批量大小設為256,動量為0.9。訓練通過權重衰減(L2懲罰乘子設定為)進行正則化,前兩個全連線層執行丟棄正則化(丟棄率設定為0.5)。學習率初始設定為,然後當驗證集準確率停止改善時,減少10倍。學習率總共降低3次,學習在37萬次迭代後停止(74個epochs)。我們推測,儘管與(Krizhevsky等,2012)相比我們的網路引數更多,網路的深度更大,但網路需要更小的epoch就可以收斂,這是由於(a)由更大的深度和更小的卷積濾波器尺寸引起的隱式正則化,(b)某些層的預初始化。
網路權重的初始化是重要的,因為由於深度網路中梯度的不穩定,不好的初始化可能會阻礙學習。為了規避這個問題,我們開始訓練配置A(表1),足夠淺以隨機初始化進行訓練。然後,當訓練更深的架構時,我們用網路A的層初始化前四個卷積層和最後三個全連線層(中間層被隨機初始化)。我們沒有減少預初始化層的學習率,允許他們在學習過程中改變。對於隨機初始化(如果應用),我們從均值為0和方差為的正態分佈中取樣權重。偏置初始化為零。值得注意的是,在提交論文之後,我們發現可以通過使用Glorot&Bengio(2010)的隨機初始化程式來初始化權重而不進行預訓練。
為了獲得固定大小的224×224 ConvNet輸入影象,它們從歸一化的訓練影象中被隨機裁剪(每個影象每次SGD迭代進行一次裁剪)。為了進一步增強訓練集,裁剪影象經過了隨機水平翻轉和隨機RGB顏色偏移(Krizhevsky等,2012)。下面解釋訓練影象歸一化。
訓練影象大小。令S是等軸歸一化的訓練影象的最小邊,ConvNet輸入從S中裁剪(我們也將S稱為訓練尺度)。雖然裁剪尺寸固定為224×224,但原則上S可以是不小於224的任何值:對於,裁剪影象將捕獲整個影象的統計資料,完全擴充套件訓練影象的最小邊;對於,裁剪影象將對應於影象的一小部分,包含小物件或物件的一部分。
我們考慮兩種方法來設定訓練尺度S。第一種是修正對應單尺度訓練的S(注意,取樣裁剪影象中的影象內容仍然可以表示多尺度影象統計)。在我們的實驗中,我們評估了以兩個固定尺度訓練的模型:(已經在現有技術中廣泛使用(Krizhevsky等人,2012;Zeiler&Fergus,2013;Sermanet等,2014))和。給定ConvNet配置,我們首先使用來訓練網路。為了加速網路的訓練,用預訓練的權重來進行初始化,我們使用較小的初始學習率。
設定S的第二種方法是多尺度訓練,其中每個訓練影象通過從一定範圍(我們使用和)隨機取樣S來單獨進行歸一化。由於影象中的目標可能具有不同的大小,因此在訓練期間考慮到這一點是有益的。這也可以看作是通過尺度抖動進行訓練集增強,其中單個模型被訓練在一定尺度範圍內識別物件。為了速度的原因,我們通過對具有相同配置的單尺度模型的所有層進行微調,訓練了多尺度模型,並用固定的進行預訓練。
4. 測試
在測試時,給出訓練的ConvNet和輸入影象,它按以下方式分類。首先,將其等軸地歸一化到預定義的最小影象邊,表示為Q(我們也將其稱為測試尺度)。我們注意到,Q不一定等於訓練尺度S(正如我們在第4節中所示,每個S使用Q的幾個值會導致效能改進)。然後,網路以類似於(Sermanet等人,2014)的方式密集地應用於歸一化的測試影象上。即,全連線層首先被轉換成卷積層(第一FC層轉換到7×7卷積層,最後兩個FC層轉換到1×1卷積層)。然後將所得到的全卷積網路應用於整個(未裁剪)影象上。結果是類得分圖的通道數等於類別的數量,以及取決於輸入影象大小的可變空間解析度。最後,為了獲得影象的類別分數的固定大小的向量,類得分圖在空間上平均(和池化)。我們還通過水平翻轉影象來增強測試集;將原始影象和翻轉影象的soft-max類後驗進行平均,以獲得影象的最終分數。
由於全卷積網路被應用在整個影象上,所以不需要在測試時對取樣多個裁剪影象(Krizhevsky等,2012),因為它需要網路重新計算每個裁剪影象,這樣效率較低。同時,如Szegedy等人(2014)所做的那樣,使用大量的裁剪影象可以提高準確度,因為與全卷積網路相比,它使輸入影象的取樣更精細。此外,由於不同的卷積邊界條件,多裁剪影象評估是密集評估的補充:當將ConvNet應用於裁剪影象時,卷積特徵圖用零填充,而在密集評估的情況下,相同裁剪影象的填充自然會來自於影象的相鄰部分(由於卷積和空間池化),這大大增加了整個網路的感受野,因此捕獲了更多的上下文。雖然我們認為在實踐中,多裁剪影象的計算時間增加並不足以證明準確性的潛在收益,但作為參考,我們還在每個尺度使用50個裁剪影象(5×5規則網格,2次翻轉)評估了我們的網路,在3個尺度上總共150個裁剪影象,與Szegedy等人(2014)在4個尺度上使用的144個裁剪影象。
5. 其他
文章最後還有單尺度評估與多尺度評估,多裁剪影象評估等,這裡就不細說了。
6.參考連結
https://blog.csdn.net/abc_138/article/details/80568450
https://blog.csdn.net/qq_31531635/article/details/71170861
https://blog.csdn.net/qq_26591517/article/details/81071393
https://blog.csdn.net/u011440696/article/details/77756776
http://blog.leanote.com/post/dataliu/5d29e67dd0b0