
[Network Architecture]Mask R-CNN論文解析(轉)
前言
最近有一個idea需要去驗證,比較忙,看完Mask R-CNN論文了,最近會去研究Mask R-CNN的程式碼,論文解析轉載網上的兩篇部落格
技術挖掘者
remanented
文章1
論文題目:Mask R-CNN
論文連結:論文連結
論文程式碼:Facebook程式碼連結;Tensorflow版本程式碼連結; Keras and TensorFlow版本程式碼連結;MxNet版本程式碼連結
一、Mask R-CNN是什麼,可以做哪些任務?
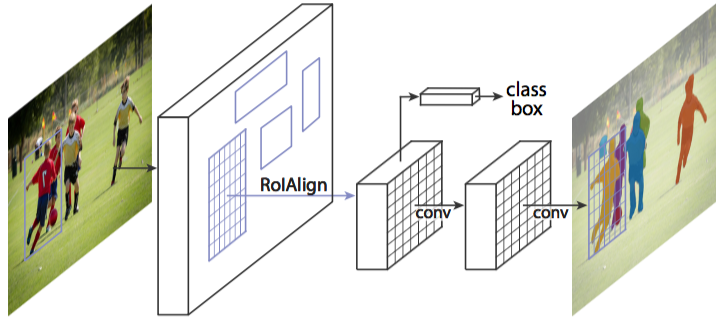
圖1 Mask R-CNN整體架構
Mask R-CNN是一個例項分割(Instance segmentation)演算法,可以用來做“目標檢測”、“目標例項分割”、“目標關鍵點檢測”。
1. 例項分割(Instance segmentation)和語義分割(Semantic segmentation)的區別與聯絡
聯絡:語義分割和例項分割都是目標分割中的兩個小的領域,都是用來對輸入的圖片做分割處理;
區別:

圖2 例項分割與語義分割區別
1. 通常意義上的目標分割指的是語義分割,語義分割已經有很長的發展歷史,已經取得了很好地進展,目前有很多的學者在做這方面的研究;然而例項分割是一個從目標分割領域獨立出來的一個小領域,是最近幾年才發展起來的,與前者相比,後者更加複雜,當前研究的學者也比較少,是一個有研究空間的熱門領域,如圖1所示,這是一個正在探索中的領域;
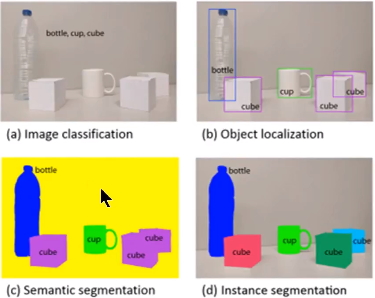
圖3 例項分割與語義分割區別
2. 觀察圖3中的c和d圖,c圖是對a圖進行語義分割的結果,d圖是對a圖進行例項分割的結果。兩者最大的區別就是圖中的"cube物件",在語義分割中給了它們相同的顏色,而在例項分割中卻給了不同的顏色。即例項分割需要在語義分割的基礎上對同類物體進行更精細的分割。
注:很多部落格中都沒有完全理解清楚這個問題,很多人將這個演算法看做語義分割,其實它是一個例項分割演算法。
2. Mask R-CNN可以完成的任務

圖4 Mask R-CNN進行目標檢測與例項分割

圖5 Mask R-CNN進行人體姿態識別
總之,Mask R-CNN是一個非常靈活的框架,可以增加不同的分支完成不同的任務,可以完成目標分類、目標檢測、語義分割、例項分割、人體姿勢識別等多種任務,真不愧是一個好演算法!
3. Mask R-CNN預期達到的目標
- 高速
- 高準確率(高的分類準確率、高的檢測準確率、高的例項分割準確率等)
- 簡單直觀
- 易於使用
4. 如何實現這些目標
高速和高準確率:為了實現這個目的,作者選用了經典的目標檢測演算法Faster-rcnn和經典的語義分割演算法FCN。Faster-rcnn可以既快又準的完成目標檢測的功能;FCN可以精準的完成語義分割的功能,這兩個演算法都是對應領域中的經典之作。Mask R-CNN比Faster-rcnn複雜,但是最終仍然可以達到5fps的速度,這和原始的Faster-rcnn的速度相當。由於發現了ROI Pooling中所存在的畫素偏差問題,提出了對應的ROIAlign策略,加上FCN精準的畫素MASK,使得其可以獲得高準確率。
簡單直觀:整個Mask R-CNN演算法的思路很簡單,就是在原始Faster-rcnn演算法的基礎上面增加了FCN來產生對應的MASK分支。即Faster-rcnn + FCN,更細緻的是 RPN + ROIAlign + Fast-rcnn + FCN。
易於使用:整個Mask R-CNN演算法非常的靈活,可以用來完成多種任務,包括目標分類、目標檢測、語義分割、例項分割、人體姿態識別等多個任務,這將其易於使用的特點展現的淋漓盡致。我很少見到有哪個演算法有這麼好的擴充套件性和易用性,值得我們學習和借鑑。除此之外,我們可以更換不同的backbone architecture和Head Architecture來獲得不同效能的結果。
二、Mask R-CNN框架解析
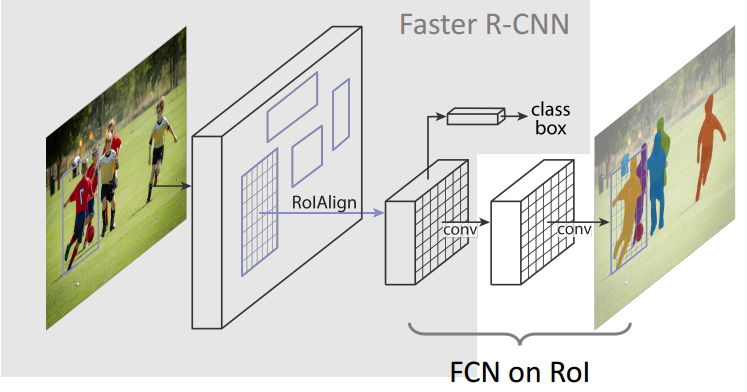
圖6 Mask R-CNN演算法框架
1. Mask R-CNN演算法步驟
- 首先,輸入一幅你想處理的圖片,然後進行對應的預處理操作,或者預處理後的圖片;
- 然後,將其輸入到一個預訓練好的神經網路中(ResNeXt等)獲得對應的feature map;
- 接著,對這個feature map中的每一點設定預定個的ROI,從而獲得多個候選ROI;
- 接著,將這些候選的ROI送入RPN網路進行二值分類(前景或背景)和BB迴歸,過濾掉一部分候選的ROI;
- 接著,對這些剩下的ROI進行ROIAlign操作(即先將原圖和feature map的pixel對應起來,然後將feature map和固定的feature對應起來);
- 最後,對這些ROI進行分類(N類別分類)、BB迴歸和MASK生成(在每一個ROI裡面進行FCN操作)。
2. Mask R-CNN架構分解
在這裡,我將Mask R-CNN分解為如下的3個模組,Faster-rcnn、ROIAlign和FCN。然後分別對這3個模組進行講解,這也是該演算法的核心。
3. Faster-rcnn(該演算法請參考該連結,我進行了詳細的分析)
4. FCN
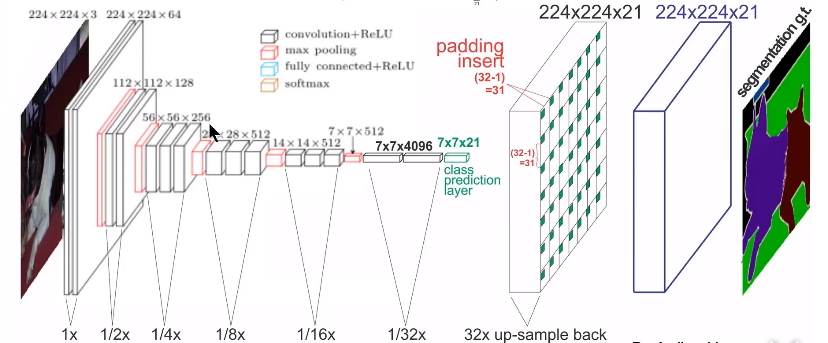
圖7 FCN網路架構
FCN演算法是一個經典的語義分割演算法,可以對圖片中的目標進行準確的分割。其總體架構如上圖所示,它是一個端到端的網路,主要的模快包括卷積和去卷積,即先對影象進行卷積和池化,使其feature map的大小不斷減小;然後進行反捲積操作,即進行插值操作,不斷的增大其feature map,最後對每一個畫素值進行分類。從而實現對輸入影象的準確分割。具體的細節請參考該連結。
5. ROIPooling和ROIAlign的分析與比較
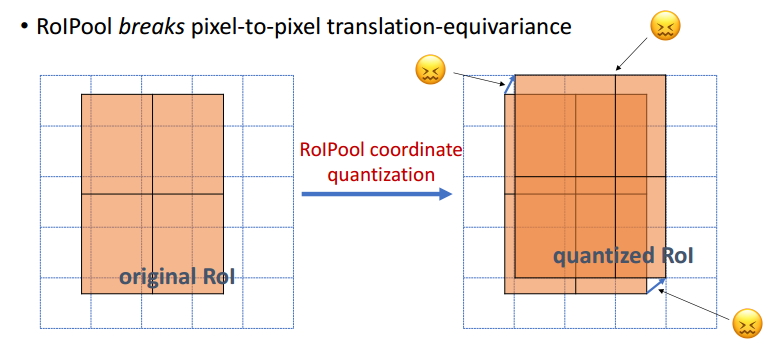 圖8
ROIPooling和ROIAlign的比較
如圖8所示,ROI Pooling和ROIAlign最大的區別是:前者使用了兩次量化操作,而後者並沒有採用量化操作,使用了線性插值演算法,具體的解釋如下所示。
圖8
ROIPooling和ROIAlign的比較
如圖8所示,ROI Pooling和ROIAlign最大的區別是:前者使用了兩次量化操作,而後者並沒有採用量化操作,使用了線性插值演算法,具體的解釋如下所示。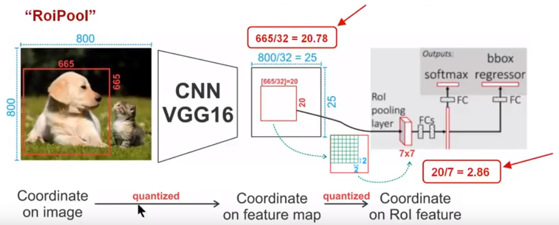
圖9 ROI Pooling技術
如圖9所示,為了得到固定大小(7X7)的feature map,我們需要做兩次量化操作:1)影象座標 — feature map座標,2)feature map座標 — ROI feature座標。我們來說一下具體的細節,如圖我們輸入的是一張800x800的影象,在影象中有兩個目標(貓和狗),狗的BB大小為665x665,經過VGG16網路後,我們可以獲得對應的feature map,如果我們對卷積層進行Padding操作,我們的圖片經過卷積層後保持原來的大小,但是由於池化層的存在,我們最終獲得feature map 會比原圖縮小一定的比例,這和Pooling層的個數和大小有關。在該VGG16中,我們使用了5個池化操作,每個池化操作都是2Pooling,因此我們最終獲得feature map的大小為800/32 x 800/32 = 25x25(是整數),但是將狗的BB對應到feature map上面,我們得到的結果是665/32 x 665/32 = 20.78 x 20.78,結果是浮點數,含有小數,但是我們的畫素值可沒有小數,那麼作者就對其進行了量化操作(即取整操作),即其結果變為20 x 20,在這裡引入了第一次的量化誤差;然而我們的feature map中有不同大小的ROI,但是我們後面的網路卻要求我們有固定的輸入,因此,我們需要將不同大小的ROI轉化為固定的ROI feature,在這裡使用的是7x7的ROI feature,那麼我們需要將20 x 20的ROI對映成7 x 7的ROI feature,其結果是 20 /7 x 20/7 = 2.86 x 2.86,同樣是浮點數,含有小數點,我們採取同樣的操作對其進行取整吧,在這裡引入了第二次量化誤差。其實,這裡引入的誤差會導致影象中的畫素和特徵中的畫素的偏差,即將feature空間的ROI對應到原圖上面會出現很大的偏差。原因如下:比如用我們第二次引入的誤差來分析,本來是2,86,我們將其量化為2,這期間引入了0.86的誤差,看起來是一個很小的誤差呀,但是你要記得這是在feature空間,我們的feature空間和影象空間是有比例關係的,在這裡是1:32,那麼對應到原圖上面的差距就是0.86 x 32 = 27.52。這個差距不小吧,這還是僅僅考慮了第二次的量化誤差。這會大大影響整個檢測演算法的效能,因此是一個嚴重的問題。好的,應該解釋清楚了吧,好累!
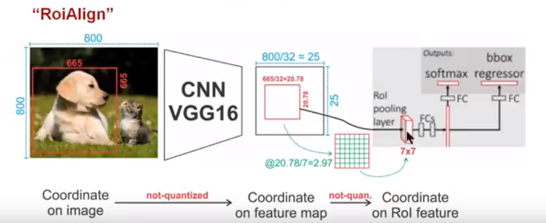
圖10 ROIAlign技術
如圖10所示,為了得到為了得到固定大小(7X7)的feature map,ROIAlign技術並沒有使用量化操作,即我們不想引入量化誤差,比如665 / 32 = 20.78,我們就用20.78,不用什麼20來替代它,比如20.78 / 7 = 2.97,我們就用2.97,而不用2來代替它。這就是ROIAlign的初衷。那麼我們如何處理這些浮點數呢,我們的解決思路是使用“雙線性插值”演算法。雙線性插值是一種比較好的影象縮放演算法,它充分的利用了原圖中虛擬點(比如20.56這個浮點數,畫素位置都是整數值,沒有浮點值)四周的四個真實存在的畫素值來共同決定目標圖中的一個畫素值,即可以將20.56這個虛擬的位置點對應的畫素值估計出來。厲害哈。如圖11所示,藍色的虛線框表示卷積後獲得的feature map,黑色實線框表示ROI feature,最後需要輸出的大小是2x2,那麼我們就利用雙線性插值來估計這些藍點(虛擬座標點,又稱雙線性插值的網格點)處所對應的畫素值,最後得到相應的輸出。這些藍點是2x2Cell中的隨機取樣的普通點,作者指出,這些取樣點的個數和位置不會對效能產生很大的影響,你也可以用其它的方法獲得。然後在每一個橘紅色的區域裡面進行max pooling或者average pooling操作,獲得最終2x2的輸出結果。我們的整個過程中沒有用到量化操作,沒有引入誤差,即原圖中的畫素和feature map中的畫素是完全對齊的,沒有偏差,這不僅會提高檢測的精度,同時也會有利於例項分割。這麼細心,做科研就應該關注細節,細節決定成敗。
we propose an RoIAlign layer that removes the harsh quantization of RoIPool, properly aligning the extracted features with the input. Our proposed change is simple: we avoid any quantization of the RoI boundaries or bins (i.e., we use x=16 instead of [x=16]). We use bilinear interpolation [22] to compute the exact values of the input features at four regularly sampled locations in each RoI bin, and aggregate the result (using max or average), see Figure 3 for details. We note that the results are not sensitive to the exact sampling locations, or how many points are sampled, as long as no quantization is performed。

圖11 雙線性插值
6. LOSS計算與分析
由於增加了mask分支,每個ROI的Loss函式如下所示:
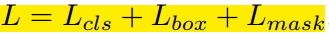
其中Lcls和Lbox和Faster r-cnn中定義的相同。對於每一個ROI,mask分支有Km*m維度的輸出,其對K個大小為m*m的mask進行編碼,每一個mask有K個類別。我們使用了per-pixel sigmoid,並且將Lmask定義為the average binary cross-entropy loss 。對應一個屬於GT中的第k類的ROI,Lmask僅僅在第k個mask上面有定義(其它的k-1個mask輸出對整個Loss沒有貢獻)。我們定義的Lmask允許網路為每一類生成一個mask,而不用和其它類進行競爭;我們依賴於分類分支所預測的類別標籤來選擇輸出的mask。這樣將分類和mask生成分解開來。這與利用FCN進行語義分割的有所不同,它通常使用一個per-pixel sigmoid和一個multinomial cross-entropy loss ,在這種情況下mask之間存在競爭關係;而由於我們使用了一個per-pixel sigmoid 和一個binary loss ,不同的mask之間不存在競爭關係。經驗表明,這可以提高例項分割的效果。
一個mask對一個目標的輸入空間佈局進行編碼,與類別標籤和BB偏置不同,它們通常需要通過FC層而導致其以短向量的形式輸出。我們可以通過由卷積提供的畫素和畫素的對應關係來獲得mask的空間結構資訊。具體的來說,我們使用FCN從每一個ROI中預測出一個m*m大小的mask,這使得mask分支中的每個層能夠明確的保持m×m空間佈局,而不將其摺疊成缺少空間維度的向量表示。和以前用fc層做mask預測的方法不同的是,我們的實驗表明我們的mask表示需要更少的引數,而且更加準確。這些畫素到畫素的行為需要我們的ROI特徵,而我們的ROI特徵通常是比較小的feature map,其已經進行了對其操作,為了一致的較好的保持明確的單畫素空間對應關係,我們提出了ROIAlign操作。
三、Mask R-CNN細節分析
1. Head Architecture
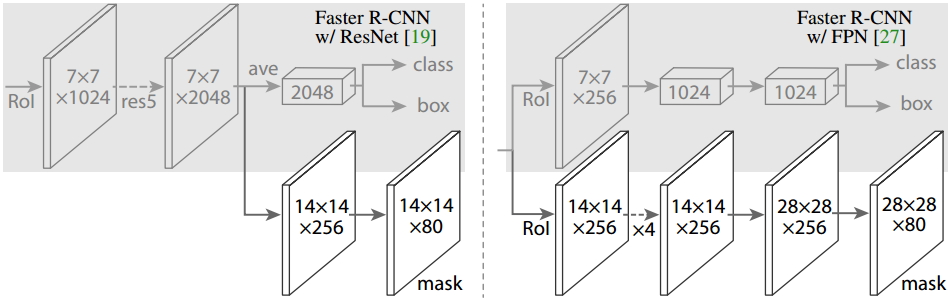
圖12 Head Architecture
如上圖所示,為了產生對應的Mask,文中提出了兩種架構,即左邊的Faster R-CNN/ResNet和右邊的Faster R-CNN/FPN。對於左邊的架構,我們的backbone使用的是預訓練好的ResNet,使用了ResNet倒數第4層的網路。輸入的ROI首先獲得7x7x1024的ROI feature,然後將其升維到2048個通道(這裡修改了原始的ResNet網路架構),然後有兩個分支,上面的分支負責分類和迴歸,下面的分支負責生成對應的mask。由於前面進行了多次卷積和池化,減小了對應的解析度,mask分支開始利用反捲積進行解析度的提升,同時減少通道的個數,變為14x14x256,最後輸出了14x14x80的mask模板。而右邊使用到的backbone是FPN網路,這是一個新的網路,通過輸入單一尺度的圖片,最後可以對應的特徵金字塔,如果想要了解它的細節,請參考該連結。得到證實的是,該網路可以在一定程度上面提高檢測的精度,當前很多的方法都用到了它。由於FPN網路已經包含了res5,可以更加高效的使用特徵,因此這裡使用了較少的filters。該架構也分為兩個分支,作用於前者相同,但是分類分支和mask分支和前者相比有很大的區別。可能是因為FPN網路可以在不同尺度的特徵上面獲得許多有用資訊,因此分類時使用了更少的濾波器。而mask分支中進行了多次卷積操作,首先將ROI變化為14x14x256的feature,然後進行了5次相同的操作(不清楚這裡的原理,期待著你的解釋),然後進行反捲積操作,最後輸出28x28x80的mask。即輸出了更大的mask,與前者相比可以獲得更細緻的mask。

圖13 BB輸出的mask結果
如上圖所示,影象中紅色的BB表示檢測到的目標,我們可以用肉眼可以觀察到檢測結果並不是很好,即整個BB稍微偏右,左邊的一部分畫素並沒有包括在BB之內,但是右邊顯示的最終結果卻很完美。
2. Equivariance in Mask R-CNN
Equivariance 指隨著輸入的變化輸出也會發生變化。
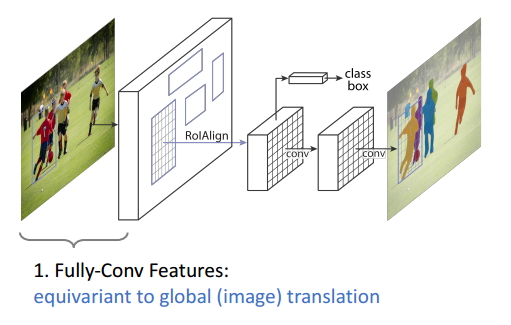 圖14
Equivariance 1
即全卷積特徵(Faster R-CNN網路)和影象的變換具有同變形,即隨著影象的變換,全卷積的特徵也會發生對應的變化;
圖14
Equivariance 1
即全卷積特徵(Faster R-CNN網路)和影象的變換具有同變形,即隨著影象的變換,全卷積的特徵也會發生對應的變化;
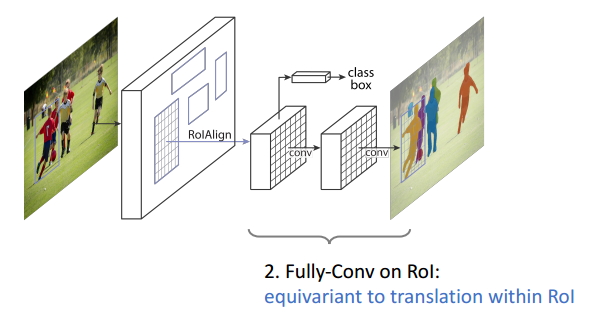
圖15 Equivariance2 在ROI上面的全卷積操作(FCN網路)和在ROI中的變換具有同變性;
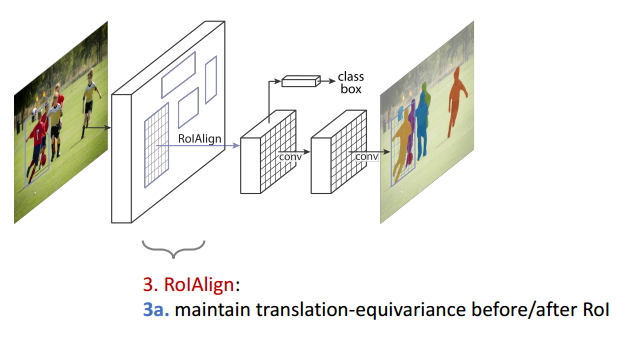
圖16 Equivariance3
ROIAlign操作保持了ROI變換前後的同變性;

圖17 ROI中的全卷積
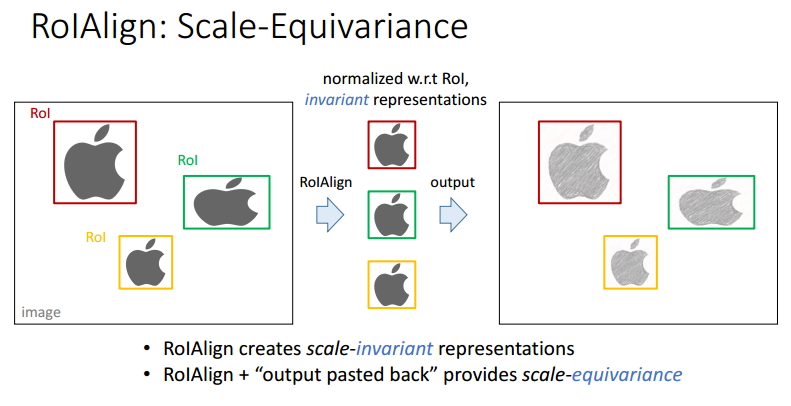
圖18 ROIAlign的尺度同變性

圖19 Mask R-CNN中的同變性總結
3. 演算法實現細節

圖20 演算法實現細節
觀察上圖,我們可以得到以下的資訊:
- Mask R-CNN中的超引數都是用了Faster r-cnn中的值,機智,省時省力,效果還好,別人已經替你調節過啦,哈哈哈;
- 使用到的預訓練網路包括ResNet50、ResNet101、FPN,都是一些效能很好地網路,尤其是FPN,後面會有分析;
- 對於過大的圖片,它會將其裁剪成800x800大小,影象太大的話會大大的增加計算量的;
- 利用8個GPU同時訓練,開始的學習率是0.01,經過18k次將其衰減為0.001,ResNet50-FPN網路訓練了32小時,ResNet101-FPN訓練了44小時;
- 在Nvidia Tesla M40 GPU上面的測試時間是195ms/張;
- 使用了MS COCO資料集,將120k的資料集劃分為80k的訓練集、35k的驗證集和5k的測試集;
四、效能比較
1. 定量結果分析
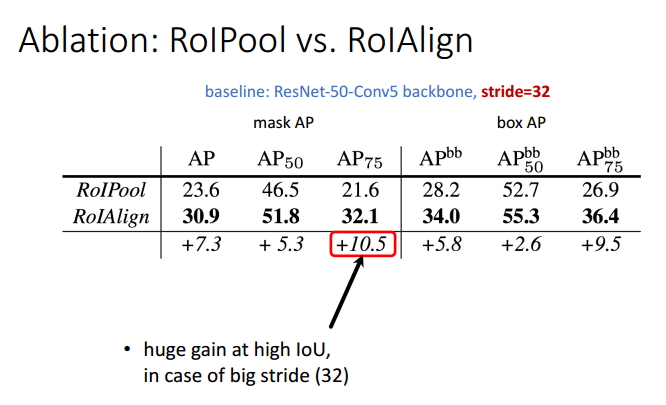
表1 ROI Pool和ROIAlign效能比較
由前面的分析,我們就可以定性的得到一個結論,ROIAlign會使得目標檢測的效果有很大的效能提升。根據上表,我們進行定量的分析,結果表明,ROIAlign使得mask的AP值提升了10.5個百分點,使得box的AP值提升了9.5個百分點。

表2 Multinomial和Binary loss比較
根據上表的分析,我們知道Mask R-CNN利用兩個分支將分類和mask生成解耦出來,然後利用Binary Loss代替Multinomial Loss,使得不同類別的mask之間消除了競爭。依賴於分類分支所預測的類別標籤來選擇輸出對應的mask。使得mask分支不需要進行重新的分類工作,使得效能得到了提升。

表3 MLP與FCN mask效能比較
如上表所示,MLP即利用FC來生成對應的mask,而FCN利用Conv來生成對應的mask,僅僅從引數量上來講,後者比前者少了很多,這樣不僅會節約大量的記憶體空間,同時會加速整個訓練過程(因此需要進行推理、更新的引數更少啦)。除此之外,由於MLP獲得的特徵比較抽象,使得最終的mask中丟失了一部分有用資訊,我們可以直觀的從右邊看到差別。從定性角度來講,FCN使得mask AP值提升了2.1個百分點。
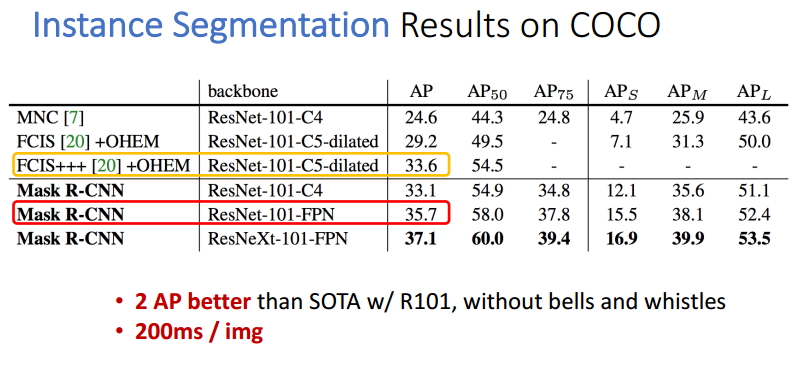
表4 例項分割的結果
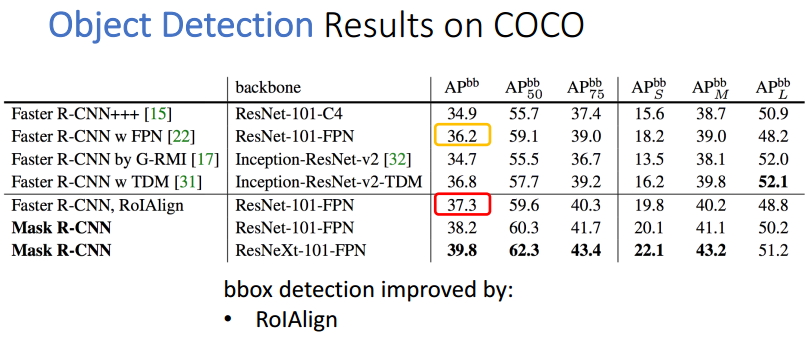
表5 目標檢測的結果
觀察目標檢測的表格,我們可以發現使用了ROIAlign操作的Faster R-CNN演算法效能得到了0.9個百分點,Mask R-CNN比最好的Faster R-CNN高出了2.6個百分點。
2. 定性結果分析
 圖21 例項分割結果1
圖21 例項分割結果1
 圖22 例項分割結果2
圖22 例項分割結果2
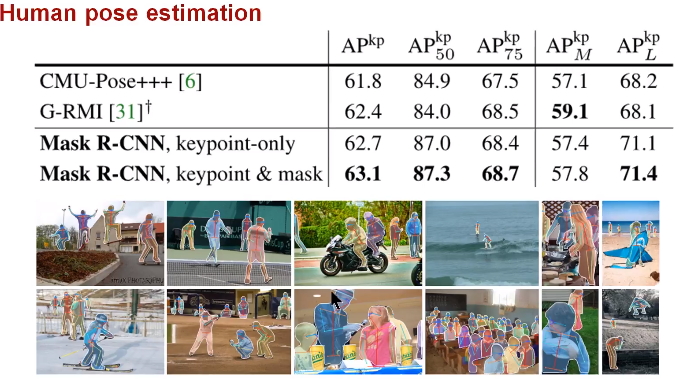 圖23 人體姿勢識別結果
圖23 人體姿勢識別結果
 圖24 失敗檢測案例1
圖24 失敗檢測案例1
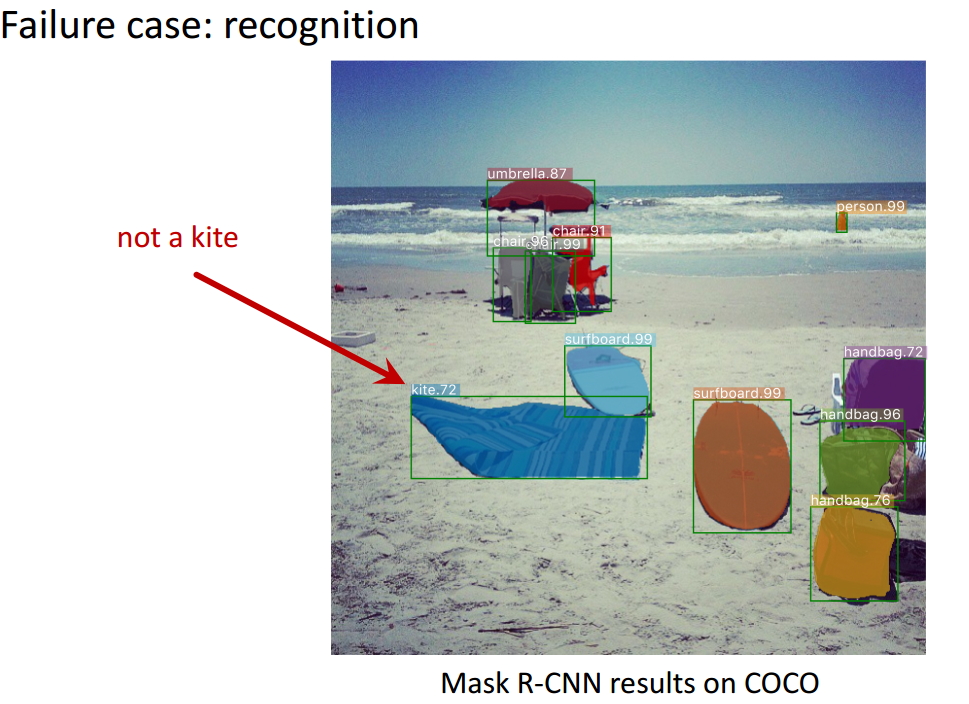 圖25 失敗檢測案例2
五、總結
圖25 失敗檢測案例2
五、總結
Mask R-CNN論文的主要貢獻包括以下幾點:
- 分析了ROI Pool的不足,提升了ROIAlign,提升了檢測和例項分割的效果;
- 將例項分割分解為分類和mask生成兩個分支,依賴於分類分支所預測的類別標籤來選擇輸出對應的mask。同時利用Binary Loss代替Multinomial Loss,消除了不同類別的mask之間的競爭,生成了準確的二值mask;
- 並行進行分類和mask生成任務,對模型進行了加速。
參考文獻:
[1] 何鎧明大神在ICCV2017上在的Slides,視訊連結
[2] Ardian Umam對Mask R-CNN的講解,視訊連結
注意事項:
[1] 該部落格是本人原創部落格,如果您對該部落格感興趣,想要轉載該部落格,請與我聯絡(qq郵箱:[email protected]),我會在第一時間回覆大家,謝謝大家。
[2] 由於個人能力有限,該部落格可能存在很多的問題,希望大家能夠提出改進意見。
[3] 如果您在閱讀本部落格時遇到不理解的地方,希望可以聯絡我,我會及時的回覆您,和您交流想法和意見,謝謝。
文章2
寫在前面:經過了10多天對RCNN家族的目標檢測演算法的探究,從一個小白到了入門階段,覺得有必要記錄下這些天學習的知識,如有理解的不到位的地方,還望各位大佬指教。文章程式碼量比較大,詳細的看可能需要一段的時間,等畢設開題答辯完了之後有時間我再修改修改,望諒解。
MASK RCNN 演算法介紹:
Mask-RCNN 是何凱明大神繼Faster-RCNN後的又一力作,集成了物體檢測和例項分割兩大功能,並且在效能上上也超過了Faster-RCNN。
整體框架:
圖1. Mask-RCNN 整體架構
為了能夠形成一定的對比,把Faster-RCNN的框架也展示出來,直接貼論文中的原圖
是在predict中用,及其
圖2.Faster-RCNN 整體架構
對比兩張圖可以很明顯的看出,在Faster-RCNN的基礎之上,Mask-RCNN加入了Mask branch(FCN)用於生成物體的掩模(object mask), 同時把RoI pooling 修改成為了RoI Align 用於處理mask與原圖中物體不對齊的問題。因為在提取feature maps的主幹conv layers中不好把FPN的結構繪製進去,所有在架構中就沒有體現出了FPN的作用,將在後面講述。
各大部件原理講解
遵循自下而上的原則,依次的從backbone,FPN,RPN,anchors,RoIAlign,classification,box regression,mask這幾個方面講解。
backbone
backbone是一系列的卷積層用於提取影象的feature maps,比如可以是VGG16,VGG19,GooLeNet,ResNet50,ResNet101等,這裡主要講解的是ResNet101的結構。
ResNet(深度殘差網路)實際上就是為了能夠訓練更加深層的網路提供了有利的思路,畢竟之前一段時間裡面一直相信深度學習中網路越深得到的效果會更加的好,但是在構建了太深層之後又會使得網路退化。ResNet使用了跨層連線,使得訓練更加容易。
圖3.ResNet的一個block
網路試圖讓一個block的輸出為f(x) + x,其中的f(x)為殘差,當網路特別深的時候殘差f(x)會趨近於0(我也沒整明白為什麼會趨近於0,大佬是這麼說的....),從而f(x) + x就等於了x,即實現了恆等變換,不管訓練多深效能起碼不會變差。
在網路中只存在兩種型別的block,在構建ResNet中一直是這兩種block在交替或者迴圈的使用,所有接下來介紹一下這兩種型別的block(indetity block, conv block):
圖4. 跳過三個卷積的identity block
圖中可以看出該block中直接把開端的x接入到第三個卷積層的輸出,所以該x也被稱為shortcut,相當於捷徑似得。注意主路上第三個卷積層使用啟用層,在相加之後才進行了ReLU的啟用。
圖5. 跳過三個卷積並在shortcut上存在卷積的conv block
與identity block其實是差不多的,只是在shortcut上加了一個卷積層再進行相加。注意主路上的第三個卷積層和shortcut上的卷積層都沒啟用,而是先相加再進行啟用的。
其實在作者的程式碼中,主路中的第一個和第三個卷積都是1*1的卷積(改變的只有feature maps的通道大小,不改變長和寬),為了降維從而實現卷積運算的加速;注意需要保持shortcut和主路最後一個卷積層的channel要相同才能夠進行相加。
下面展示一下ResNet101的整體框架:
圖6.ResNet101整體架構
從圖中可以得知ResNet分為了5個stage,C1-C5分別為每個Stage的輸出,這些輸出在後面的FPN中會使用到。你可以數數,看看是不是總共101層,數的時候除去BatchNorm層。注:stage4中是由一個conv_block和22個identity_block,如果要改成ResNet50網路的話只需要調整為5個identity_block.
ResNet101的介紹算是告一個段落了。
FPN(Feature Pyramid Network)
FPN的提出是為了實現更好的feature maps融合,一般的網路都是直接使用最後一層的feature maps,雖然最後一層的feature maps 語義強,但是位置和解析度都比較低,容易檢測不到比較小的物體。FPN的功能就是融合了底層到高層的feature maps ,從而充分的利用了提取到的各個階段的Z徵(ResNet中的C2-C5 )。
圖7.FPN特徵融合圖
來說可能這
圖8.特徵融合圖7中+的意義解釋圖
從圖中可以看出+的意義為:左邊的底層特徵層通過1*1的卷積得到與上一層特徵層相同的通道數;上層的特徵層通過上取樣得到與下一層特徵層一樣的長和寬再進行相加,從而得到了一個融合好的新的特徵層。舉個例子說就是:C4層經過1*1卷積得到與P5相同的通道,P5經過上取樣後得到與C4相同的長和寬,最終兩者進行相加,得到了融合層P4,其他的以此類推。
注:P2-P5是將來用於預測物體的bbox,box-regression,mask的,而P2-P6是用於訓練RPN的,即P6只用於RPN網路中。
anchors
anchors英文翻譯為錨點、錨框,是用於在feature maps的畫素點上產生一系列的框,各個框的大小由scale和ratio這兩個引數來確定的,比如scale =[128],ratio=[0.5,1,1.5] ,則每個畫素點可以產生3個不同大小的框。這個三個框是由保持框的面積不變,來通過ratio的值來改變其長寬比,從而產生不同大小的框。
假設我們現在繪製feature maps上一個畫素點的anchors,則能得到下圖:
圖9.一個畫素點上的anchors
由於使用到了FPN,在論文中也有說到每層的feature map 的scale是保持不變的,只是改變每層的ratio,且越深scale的值就越小,因為越深的話feature map就越小。論文中提供的每層的scale為(32, 64, 128, 256, 512),ratio為(0.5, 1, 2),所有每一層的每一個畫素點都會產生3個錨框,而總共會有15種不同大小的錨框。
對於影象的中心點會有15個不同大小錨框,如下圖:
圖10.影象中心點的錨框展示
RPN(Region Proposal Network)
RNP顧名思義:區域推薦的網路,用於幫助網路推薦感興趣的區域,也是Faster-RCNN中重要的一部分。
圖11. 論文中RPN介紹圖
1. conv feature map:上文中的P2-P6
2. kk anchor boxes:在每個sliding window的點上的初始化的參考區域。每個sliding window的點上取得anchor boxes都一樣。只要知道sliding window的點的座標,就可以計算出每個anchor box的具體座標。每個特徵層的k=3k,先確定一個base anchor,如P6大小為32×3216×16,保持面積不變使其長寬比為(0.5,1,2)(0.5,1,2),得到3個anchors。
3. intermediate layer:作者程式碼中使用的是512d的conv中間層,再通過1×11×1的卷積獲得2k2k scores和4k4k cordinates。作者在文中解釋為用全卷積方式替代全連線。
4. 2k2k scores:對於每個anchor,用了softmax layer的方式,會或得兩個置信度。一個置信度是前景,一個置信度是背景
5. 4k4k cordinates:每個視窗的座標。這個座標並不是anchor的絕對座標,而是與ground_truth偏差的迴歸。
在作者程式碼中RPN的網路具體結構如下:
圖12. RPN接面構圖
注:在開始看作者程式碼的時候也是有些蒙圈的,為什麼給RPN只傳入了feature map和k值就可以,而沒有給出之前建立好的anchors,後來才明白作者在資料產生那一塊做了修改,他在產生資料的時候就給每一個建立好的anchors標註好了是positive還是negative以及需要回歸的box值,所有隻需要訓練RPN就好了。
RoIAlign
Mask-RCNN中提出了一個新的idea就是RoIAlign,其實RoIAlign就是在RoI pooling上稍微改動過來的,但是為什麼在模型中不能使用RoI pooling呢?現在我們來直觀的解釋一下。
圖13. RoIAlign與RoIpooling對比
可以看出來在RoI pooling中出現了兩次的取整,雖然在feature maps上取整看起來只是小數級別的數,但是當把feature map還原到原圖上時就會出現很大的偏差,比如第一次的取整是捨去了0.78,還原到原圖時是0.78*32=25,第一次取整就存在了25個畫素點的偏差,在第二次的取整後的偏差更加的大。對於分類和物體檢測來說可能這不是一個很大的誤差,但是對於例項分割而言,這是一個非常大的偏差,因為mask出現沒對齊的話在視覺上是很明顯的。而RoIAlign的提出就是為了解決這個問題,解決不對齊的問題。
RoIAlign的思想其實很簡單,就是取消了取整的這種粗暴做法,而是通過雙線性插值(聽我師姐說好像有一篇論文用到了積分,而且效能得到了一定的提高)來得到固定四個點座標的畫素值,從而使得不連續的操作變得連續起來,返回到原圖的時候誤差也就更加的小。
1.劃分7*7的bin(可以直接精確的對映到feature map上來劃分bin,不用第一次ROI的量化)
圖14. ROI分割7*7的bin
2.接著是對每一個bin中進行雙線性插值,得到四個點(在論文中也說到過插值一個點的效果其實和四個點的效果是一樣的,在程式碼中作者為了方便也就採用了插值一個點)
圖15.插值示意圖
3.通過插完值之後再進行max pooling得到最終的7*7的ROI,即完成了RoIAlign的過程。是不是覺得大佬提出來的高大上名字的方法還是挺簡單的。
classifier
其中包括了物體檢測最終的classes和bounding boxes。該部分是利用了之前檢測到了ROI進行分類和迴歸(是分別對每一個ROI進行)。
圖16. classifier的結構
論文中提到用1024個神經元的全連線網路,但是在程式碼中作者用卷積深度為1024的卷積層來代替這個全連線層。
mask
mask的預測也是在ROI之後的,通過FCN(Fully Convolution Network)來進行的。注意這個是實現的語義分割而不是例項分割。因為每個ROI只對應一個物體,只需對其進行語義分割就好,相當於了例項分割了,這也是Mask-RCNN與其他分割框架的不同,是先分類再分割。
圖17. mask的結構
對於每一個ROI的mask都有80類,因為coco上的資料集是80個類別,並且這樣做的話是為了減弱類別間的競爭,從而得到更加好的結果。
該模型的訓練和預測是分開的,不是套用同一個流程。在訓練的時候,classifier和mask都是同時進行的;在預測的時候,顯示得到classifier的結果,然後再把此結果傳入到mask預測中得到mask,有一定的先後順序。
Mask-RCNN 程式碼實現
文中程式碼的作者是Matterport: 程式碼github地址,文中詳細的介紹了各個部分,以及給了demo和各個實現的步驟及其視覺化。
程式碼總體框架
先貼出我對作者程式碼流程的理解,及其畫出的流程圖。
圖18.程式碼中training的流程圖
圖19.程式碼中predict的流程圖
兩張流程圖其實已經把作者的程式碼各個關鍵部分都展示出來了,並寫出了哪些層是在training中用,哪些層是在predict中用,及其層的輸出和需要的輸入。可以清晰的看出training和predict過程是存在較大的差異的,也是之前說過的,training的時候mask與classifier是並行的,predict時候是先classifier再mask,並且兩個模型的輸入輸出差異也較大。
已經有一篇部落格寫的很好,對作者程式碼的那幾個ipynb都運行了一遍,並且加上了自己的理解。非常的感謝那位博主,之前在探究Mask-RCNN的時候那邊博文對我的幫助很大,有興趣的可以看看那片博文:博文連結
我這裡就主要的介紹一下作者中的幾個.py檔案:visualize.py,utils.py,model.py,最後再實現一下如何使用該程式碼處理視訊
因為程式碼量比較大,我就挑一些本人認為重要的程式碼貼出來。
visualize.py
##利用不同的顏色為每個instance標註出mask,根據box的座標在instance的周圍畫上矩形
##根據class_ids來尋找到對於的class_names。三個步驟中的任何一個都可以去掉,比如把mask部分
##去掉,那就只剩下box和label。同時可以篩選出class_ids從而顯示制定類別的instance顯示,下面
##這段就是用來顯示人的,其實也就把人的id選出來,然後記錄它們在輸入ids中的相對位置,從而得到
##相對應的box與mask的準確順序
def display_instances_person(image, boxes, masks, class_ids, class_names,
scores=None, title="",
figsize=(16, 16), ax=None):
"""
the funtion perform a role for displaying the persons who locate in the image
boxes: [num_instance, (y1, x1, y2, x2, class_id)] in image coordinates.
masks: [height, width, num_instances]
class_ids: [num_instances]
class_names: list of class names of the dataset
scores: (optional) confidence scores for each box
figsize: (optional) the size of the image.
"""
#compute the number of person
temp = []
for i, person in enumerate(class_ids):
if person == 1:
temp.append(i)
else:
pass
person_number = len(temp)
person_site = {}
for i in range(person_number):
person_site[i] = temp[i]
NN = boxes.shape[0]
# Number of person'instances
#N = boxes.shape[0]
N = person_number
if not N:
print("\n*** No person to display *** \n")
else:
# assert boxes.shape[0] == masks.shape[-1] == class_ids.shape[0]
pass
if not ax:
_, ax = plt.subplots(1, figsize=figsize)
# Generate random colors
colors = random_colors(NN)
# Show area outside image boundaries.
height, width = image.shape[:2]
ax.set_ylim(height + 10, -10)
ax.set_xlim(-10, width + 10)
ax.axis('off')
ax.set_title(title)
masked_image = image.astype(np.uint32).copy()
for a in range(N):
color = colors[a]
i = person_site[a]
# Bounding box
if not np.any(boxes[i]):
# Skip this instance. Has no bbox. Likely lost in image cropping.
continue
y1, x1, y2, x2 = boxes[i]
p = patches.Rectangle((x1, y1), x2 - x1, y2 - y1, linewidth=2,
alpha=0.7, linestyle="dashed",
edgecolor=color, facecolor='none')
ax.add_patch(p)
# Label
class_id = class_ids[i]
score = scores[i] if scores is not None else None
label = class_names[class_id]
x = random.randint(x1, (x1 + x2) // 2)
caption = "{} {:.3f}".format(label, score) if score else label
ax.text(x1, y1 + 8, caption,
color='w', size=11, backgroundcolor="none")
# Mask
mask = masks[:, :, i]
masked_image = apply_mask(masked_image, mask, color)
# Mask Polygon
# Pad to ensure proper polygons for masks that touch image edges.
padded_mask = np.zeros(
(mask.shape[0] + 2, mask.shape[1] + 2), dtype=np.uint8)
padded_mask[1:-1, 1:-1] = mask
contours = find_contours(padded_mask, 0.5)
for verts in contours:
# Subtract the padding and flip (y, x) to (x, y)
verts = np.fliplr(verts) - 1
p = Polygon(verts, facecolor="none", edgecolor=color)
ax.add_patch(p)
ax.imshow(masked_image.astype(np.uint8))
plt.show()utils.py
##因為一個自定義層的輸入的batch只能為1,所以需要把input分成batch為1的輸入,
##然後通過graph_fn計算出output,最終再合在一塊,即間接的實現了計算了一個batch的操作
# ## Batch Slicing
# Some custom layers support a batch size of 1 only, and require a lot of work
# to support batches greater than 1. This function slices an input tensor
# across the batch dimension and feeds batches of size 1. Effectively,
# an easy way to support batches > 1 quickly with little code modification.
# In the long run, it's more efficient to modify the code to support large
# batches and getting rid of this function. Consider this a temporary solution
def batch_slice(inputs, graph_fn, batch_size, names=None):
"""Splits inputs into slices and feeds each slice to a copy of the given
computation graph and then combines the results. It allows you to run a
graph on a batch of inputs even if the graph is written to support one
instance only.
inputs: list of tensors. All must have the same first dimension length
graph_fn: A function that returns a TF tensor that's part of a graph.
batch_size: number of slices to divide the data into.
names: If provided, assigns names to the resulting tensors.
"""
if not isinstance(inputs, list):
inputs = [inputs]
outputs = []
for i in range(batch_size):
inputs_slice = [x[i] for x in inputs]
output_slice = graph_fn(*inputs_slice)
if not isinstance(output_slice, (tuple, list)):
output_slice = [output_slice]
outputs.append(output_slice)
# Change outputs from a list of slices where each is
# a list of outputs to a list of outputs and each has
# a list of slices
outputs = list(zip(*outputs))
if names is None:
names = [None] * len(outputs)
result = [tf.stack(o, axis=0, name=n)
for o, n in zip(outputs, names)]
if len(result) == 1:
result = result[0]
return result############################################################
# Anchors
############################################################
##對特徵圖上的pixel產生anchors,根據anchor_stride來確定pixel產生anchors的密度
##即是每個畫素點產生anchors,還是每兩個產生,以此類推
def generate_anchors(scales, ratios, shape, feature_stride, anchor_stride):
"""
scales: 1D array of anchor sizes in pixels. Example: [32, 64, 128]
ratios: 1D array of anchor ratios of width/height. Example: [0.5, 1, 2]
shape: [height, width] spatial shape of the feature map over which
to generate anchors.
feature_stride: Stride of the feature map relative to the image in pixels.
anchor_stride: Stride of anchors on the feature map. For example, if the
value is 2 then generate anchors for every other feature map pixel.
"""
# Get all combinations of scales and ratios
scales, ratios = np.meshgrid(np.array(scales), np.array(ratios))
scales = scales.flatten()
ratios = ratios.flatten()
# Enumerate heights and widths from scales and ratios
heights = scales / np.sqrt(ratios)
widths = scales * np.sqrt(ratios)
# Enumerate shifts in feature space
shifts_y = np.arange(0, shape[0], anchor_stride) * feature_stride
shifts_x = np.arange(0, shape[1], anchor_stride) * feature_stride
shifts_x, shifts_y = np.meshgrid(shifts_x, shifts_y)
# Enumerate combinations of shifts, widths, and heights
box_widths, box_centers_x = np.meshgrid(widths, shifts_x)
box_heights, box_centers_y = np.meshgrid(heights, shifts_y)
# Reshape to get a list of (y, x) and a list of (h, w)
box_centers = np.stack(
[box_centers_y, box_centers_x], axis=2).reshape([-1, 2])
box_sizes = np.stack([box_heights, box_widths], axis=2).reshape([-1, 2])
# Convert to corner coordinates (y1, x1, y2, x2)
boxes = np.concatenate([box_centers - 0.5 * box_sizes,
box_centers + 0.5 * box_sizes], axis=1)
return boxes
#呼叫generate_anchors()為每一層的feature map都生成anchors,最終在合成在一塊。自己層中的scale是相同的
def generate_pyramid_anchors(scales, ratios, feature_shapes, feature_strides,
anchor_stride):
"""Generate anchors at different levels of a feature pyramid. Each scale
is associated with a level of the pyramid, but each ratio is used in
all levels of the pyramid.
Returns:
anchors: [N, (y1, x1, y2, x2)]. All generated anchors in one array. Sorted
with the same order of the given scales. So, anchors of scale[0] come
first, then anchors of scale[1], and so on.
"""
# Anchors
# [anchor_count, (y1, x1, y2, x2)]
anchors = []
for i in range(len(scales)):
anchors.append(generate_anchors(scales[i], ratios, feature_shapes[i],
feature_strides[i], anchor_stride))
return np.concatenate(anchors, axis=0)
model.py
###建立ResNet101網路的架構,其中identity_block和conv_block就是上文中講解。
def resnet_graph(input_image, architecture, stage5=False):
assert architecture in ["resnet50", "resnet101"]
# Stage 1
x = KL.ZeroPadding2D((3, 3))(input_image)
x = KL.Conv2D(64, (7, 7), strides=(2, 2), name='conv1', use_bias=True)(x)
x = BatchNorm(axis=3, name='bn_conv1')(x)
x = KL.Activation('relu')(x)
C1 = x = KL.MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
# Stage 2
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
C2 = x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# Stage 3
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
C3 = x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# Stage 4
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
block_count = {"resnet50": 5, "resnet101": 22}[architecture]
for i in range(block_count):
x = identity_block(x, 3, [256, 256, 1024], stage=4, block=chr(98 + i))
C4 = x
# Stage 5
if stage5:
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
C5 = x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
else:
C5 = None
return [C1, C2, C3, C4, C5]
Proposal Layer:
class ProposalLayer(KE.Layer):
"""
Inputs:
rpn_probs: [batch, anchors, (bg prob, fg prob)]
rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))]
Returns:
Proposals in normalized coordinates [batch, rois, (y1, x1, y2, x2)]
"""
def __init__(self, proposal_count, nms_threshold, anchors,
config=None, **kwargs):
"""
anchors: [N, (y1, x1, y2, x2)] anchors defined in image coordinates
"""
super(ProposalLayer, self).__init__(**kwargs)
self.config = config
self.proposal_count = proposal_count
self.nms_threshold = nms_threshold
self.anchors = anchors.astype(np.float32)
def call(self, inputs):
###實現了將傳入的anchors,及其scores、deltas進行topK的推薦和nms的推薦,最終輸出
###數量為proposal_counts的proposals。其中的scores和deltas都是RPN網路中得到的
# Box Scores. Use the foreground class confidence. [Batch, num_rois, 1]
scores = inputs[0][:, :, 1]
# Box deltas [batch, num_rois, 4]
deltas = inputs[1]
deltas = deltas * np.reshape(self.config.RPN_BBOX_STD_DEV, [1, 1, 4])
# Base anchors
anchors = self.anchors
# Improve performance by trimming to top anchors by score
# and doing the rest on the smaller subset.
pre_nms_limit = min(6000, self.anchors.shape[0])
ix = tf.nn.top_k(scores, pre_nms_limit, sorted=True,
name="top_anchors").indices
scores = utils.batch_slice([scores, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
deltas = utils.batch_slice([deltas, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
anchors = utils.batch_slice(ix, lambda x: tf.gather(anchors, x),
self.config.IMAGES_PER_GPU,
names=["pre_nms_anchors"])
# Apply deltas to anchors to get refined anchors.
# [batch, N, (y1, x1, y2, x2)]
##利用deltas在anchors上,得到精化的boxs
boxes = utils.batch_slice([anchors, deltas],
lambda x, y: apply_box_deltas_graph(x, y),
self.config.IMAGES_PER_GPU,
names=["refined_anchors"])
# Clip to image boundaries. [batch, N, (y1, x1, y2, x2)]
height, width = self.config.IMAGE_SHAPE[:2]
window = np.array([0, 0, height, width]).astype(np.float32)
boxes = utils.batch_slice(boxes,
lambda x: clip_boxes_graph(x, window),
self.config.IMAGES_PER_GPU,
names=["refined_anchors_clipped"])
# Filter out small boxes
# According to Xinlei Chen's paper, this reduces detection accuracy
# for small objects, so we're skipping it.
# Normalize dimensions to range of 0 to 1.
normalized_boxes = boxes / np.array([[height, width, height, width]])
# Non-max suppression
def nms(normalized_boxes, scores):
indices = tf.image.non_max_suppression(
normalized_boxes, scores, self.proposal_count,
self.nms_threshold, name="rpn_non_max_suppression")
proposals = tf.gather(normalized_boxes, indices)
# Pad if needed
padding = tf.maximum(self.proposal_count - tf.shape(proposals)[0], 0)
##填充到與proposal_count的數量一樣,往下填充。
proposals = tf.pad(proposals, [(0, padding), (0, 0)])
return proposals
proposals = utils.batch_slice([normalized_boxes, scores], nms,
self.config.IMAGES_PER_GPU)
return proposals
RoIAlign Layer:
class PyramidROIAlign(KE.Layer):
"""Implements ROI Pooling on multiple levels of the feature pyramid.
Params:
- pool_shape: [height, width] of the output pooled regions. Usually [7, 7]
- image_shape: [height, width, chanells]. Shape of input image in pixels
Inputs:
- boxes: [batch, num_boxes, (y1, x1, y2, x2)] in normalized
coordinates. Possibly padded with zeros if not enough
boxes to fill the array.
- Feature maps: List of feature maps from different levels of the pyramid.
Each is [batch, height, width, channels]
Output:
Pooled regions in the shape: [batch, num_boxes, height, width, channels].
The width and height are those specific in the pool_shape in the layer
constructor.
"""
def __init__(self, pool_shape, image_shape, **kwargs):
super(PyramidROIAlign, self).__init__(**kwargs)
self.pool_shape = tuple(pool_shape)
self.image_shape = tuple(image_shape)
def call(self, inputs):
##計算在不同層的ROI下的ROIalig pooling,應該是計算了每一個lever的所有channels
# Crop boxes [batch, num_boxes, (y1, x1, y2, x2)] in normalized coords
boxes = inputs[0]
# Feature Maps. List of feature maps from different level of the
# feature pyramid. Each is [batch, height, width, channels]
feature_maps = inputs[1:]
# Assign each ROI to a level in the pyramid based on the ROI area.
y1, x1, y2, x2 = tf.split(boxes, 4, axis=2)
h = y2 - y1
w = x2 - x1
# Equation 1 in the Feature Pyramid