
大資料技術 分散式儲存 HDFS原理
大資料基礎知識
一、什麼是大資料
短時間內快速產生的海量的多種多樣的有價值的資料。
大資料的技術:
1、分散式儲存:
2、分散式計算:
1)分散式批處理:
當資料積累一定的時間後(假設一個月),進行統一的處理。
2)分散式流處理
分散式流處理是一個實時的處理。即資料生成後立即處理。
例子: 11.11天貓大螢幕 QQ實時線上的分佈情況
3、機器學習
凡是預測類的都是機器學習。
分散式儲存
簡單案例:假如你要儲存10PB的一個視訊檔案,自己一個人的電腦儲存不了,需要儲存在多個伺服器上,每一個伺服器就是一個datanode
系統學習分散式儲存 過程(HDFS原理)
1 如果要上傳一個大檔案,首先要計算大檔案的block數量,block數量=大檔案的大小/128M(一般採用128M為一個block塊的大小)
2 client會向namenode彙報
1)當前大檔案的block數量
2)當前大檔案屬於誰 許可權
3)上傳時間
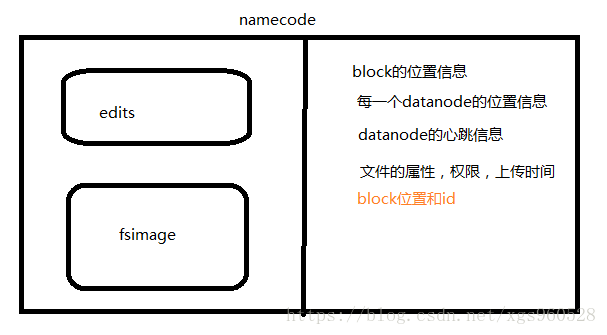
namenode的作用:
掌握全域性,管理datanode以及元資料
元資料儲存在記憶體中
接受客戶端client的讀寫服務
收集datanode彙報的block列表的資訊
namenode儲存metadata資訊包括
檔案的owner和permissions
檔案的大小,時間
(block列表:blockId)
block副本的位置(由datanode上報)
3由於檔案太大,超過128M所以得切割出來一個個的block,先切割一個block塊
4namenode去請求block塊的Id號以及地址
5因為namenode能夠掌握全域性,管理所有的datanode,所以它會將負載不高的datanode
6client拿到地址後,找到datanode上傳資料,
如何上傳:
namenode將地址返回後,block會切割成一個個的packet,這些datanode之間會形成一個Pipeline管道,目的是:並行儲存,提高效率。

7datanode拿到地址後,會向namenode回報當前的儲存情況。
datanode的作用:
儲存block塊,向namenode彙報傳送心跳,傳送心跳是為了讓namenode知道自己在正常執行
接受client的讀請求,client不僅可以向datanode寫資料,也可以讀資料,獲取到地址後直接讀取。
8client繼續切割,直到上傳完成所有的資料。
問題:
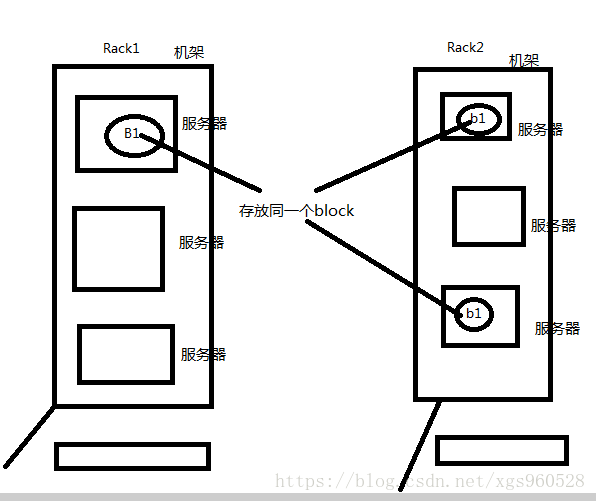
考慮到安全問題,資料做了兩個備份(預設兩份),所以在第6步上傳資料的時候,是向多臺伺服器傳遞資料。
多臺??:(1)如果是叢集(多臺伺服器組成)外namecode向client返回的三個地址,第一個是負載不高的datanode,第二個地址是在其他機架(有多臺伺服器)的隨機一個伺服器上第三個地址是和第二個我地址位於同一個機架的其他伺服器上。如果一個機架出現問題,資料也不會丟失。
(2)如果是叢集內返回地址,第一個位置是當前的節點,第二個,第三個同上
namenode工作原理:
基本結構
edits:儲存操作資訊
edits儲存了namenode的操作資訊,當edits檔案中的資料達到一定的數量(64M)或者時間超過了規定的時間時,secondnamenode會將edits和fsimage,同時namenode生成新的edits.new去記錄操作,在secondnamenode中,會模擬執行edits檔案,產生元資料,並將元資料與fsimage合併,合併之後將fsimage推送給namenode,edits.new成為新的edits。這個過程就是元資料的持久化。
不是所有的元資料都會持久化,block的位置就不會,因為每次叢集啟動時,伺服器會自己將block的位置傳遞給namenode.
注意:
1 安全模式:
1)載入fsimage,載入到記憶體
2)如果edits檔案不為空,那麼namenode自己來合併
3)檢查datanode是否健康
4)如果有datanode不正常,指揮做備份
2處於安全模式的過程中,如果fsiamge已經載入到記憶體中,可以檢視到檔案目錄,但是無法讀取
3HDFS許可權控制:防君子,不妨小人
4HDFS叢集不允許修改,檔案一旦上傳成功不能修改block塊的大小,禁掉的功能就是為了防止叢集泛洪