
分散式儲存-ceph原理
一、ceph核心元件:
Ceph提供了RADOS、OSD、MON、Librados、RBD、RGW和Ceph FS等功能元件,但其底層仍然使用RADOS儲存來支撐上層的那些元件;
核心元件:Ceph OSD,Ceph Monitor,Ceph MDS。
Ceph OSD:全稱是Object Storage Device,主要功能包括儲存資料,處理資料的複製、恢復、回補、平衡資料分佈,並將一些相關資料提供給Ceph Monitor;
Ceph Monitor:Ceph的監控器,主要功能是維護整個叢集健康狀態,提供一致性的決策,包含了Monitor map、OSD map、PG(Placement Group)map和CRUSH map;
Ceph MDS
Managers: Ceph Manager守護程序(ceph-mgr)負責跟蹤執行時指標和Ceph叢集的當前狀態,包括儲存利用率,當前效能指標和系統負載。Ceph Manager守護程序還託管基於python的外掛來管理和公開Ceph叢集資訊,包括基於Web的Ceph Manager Dashboard和 REST API。高可用性通常至少需要兩個管理器。
提示:Ceph的塊儲存和Ceph的物件儲存都不需要Ceph MDS。Ceph MDS為基於POSIX檔案系統的使用者提供了一些基礎命令,例如ls、find等命令。
提供物件儲存RADOSGW(Reliable 可靠的、Autonomic、Distributed 分散式、Object Storage Gateway)、塊儲存RBD(Rados Block Device)、檔案系統儲存Ceph FS(Ceph File System)
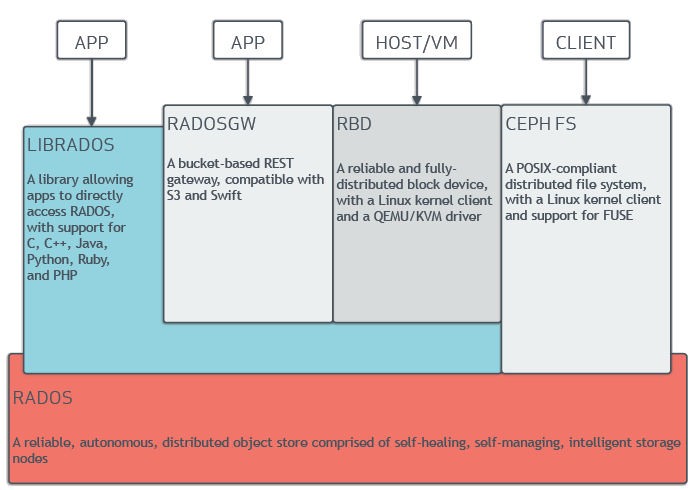
LIBRADOS模組是客戶端用來訪問RADOS物件儲存裝置的
RADOSGW功能特性基於LIBRADOS之上,提供當前流行的RESTful協議的閘道器,並且相容,S3和Swift介面,作為物件儲存,可以對接網盤類應用以及HLS流媒體應用等
RBD(Rados Block Device)功能特性也是基於LIBRADOS之上,通過LIBRBD建立一個塊裝置,通過QEMU/KVM附加到VM上,作為傳統的塊裝置來用。目前OpenStack、CloudStack等,都是採用這種方式來為VM提供塊裝置,同時也支援快照、COW(Copy On Write)等功能
Ceph FS(Ceph File System)功能特性是基於RADOS來實現分散式的檔案系統,引入了MDS(Metadata Server),主要為相容POSIX檔案系統提供元資料。一般都是當做檔案系統來掛載。
二、RADOS架構
基於RADOS,使用Ceph作為儲存架構;RADOS系統主要由兩個部分組成,對於RADOS系統,節點組織管理和資料分發策略均由內部的Mon全權負責;
1)OSD:由數目可變的大規模OSD(Object Storage Devices)組成的叢集,負責儲存所有的Objects資料。
2)Monitor:由少量Monitors組成的強耦合、小規模叢集,負責管理Cluster Map。其中,Cluster Map是整個RADOS系統的關鍵資料結構,管理叢集中的所有成員關係和屬性等資訊以及資料的分發。
(1)Monitor
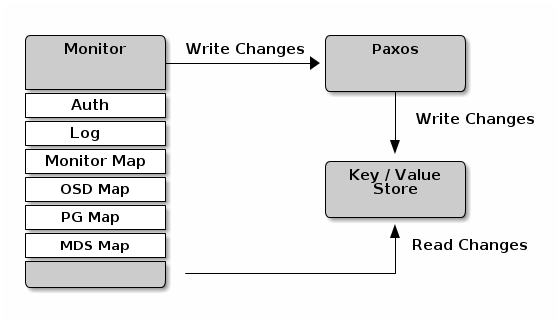
Ceph Monitor是負責監視整個群集的執行狀況的,這些資訊都是由維護叢集成員的守護程式來提供的,如各個節點之間的狀態、叢集配置資訊。Ceph monitor map包括OSD Map、PG Map、MDS Map和CRUSH等,這些Map被統稱為叢集Map;
1)Monitor Map。Monitor Map包括有關monitor節點端到端的資訊,其中包括Ceph叢集ID,監控主機名和IP地址和埠號,它還儲存了當前版本資訊以及最新更改資訊
#ceph mon dump2)OSD Map。OSD Map包括一些常用的資訊,如叢集ID,建立OSD Map的版本資訊和最後修改資訊,以及pool相關資訊,pool的名字、pool的ID、型別,副本數目以及PGP,還包括OSD資訊,如數量、狀態、權重、最新的清潔間隔和OSD主機資訊。
#ceph osd dump3)PG Map。PG Map包括當前PG版本、時間戳、最新的OSD Map的版本資訊、空間使用比例,以及接近佔滿比例資訊,同時,也包括每個PG ID、物件數目、狀態、OSD的狀態以及深度清理的詳細資訊
#ceph pg dump4)CRUSH Map。CRUSH Map包括叢集儲存裝置資訊,故障域層次結構和儲存資料時定義失敗域規則資訊;
#ceph osd crush dump 5)MDS Map。MDS Map包括儲存當前MDS Map的版本資訊、建立當前Map的資訊、修改時間、資料和元資料POOL ID、叢集MDS數目和MDS狀態;
#ceph mds dumpCeph Monitor的主要作用是維護叢集對映的主副本。Ceph Monitors還提供身份驗證和日誌記錄服務。Ceph監視器將監視器服務中的所有更改寫入單個Paxos例項,Paxos將更改寫入鍵/值儲存以實現強一致性。Ceph監視器可以在同步操作期間查詢最新版本的叢集對映。Ceph Monitors利用鍵/值儲存的快照和迭代器(使用leveldb)來執行儲存範圍的同步
叢集執行圖是多個圖的組合,包括監視器圖、 OSD 圖、歸置組圖和元資料伺服器圖。叢集執行圖追蹤幾個重要事件:哪些程序在叢集裡( in );哪些程序在叢集裡( in )是 up 且在執行、或 down ;歸置組狀態是 active 或 inactive 、 clean 或其他狀態;和其他反映當前叢集狀態的資訊,像總儲存容量、和使用量。
Ceph在叢集中與另一個Ceph Monitor時對Ceph監視器要嚴格的一致性要求,然而,Ceph客戶端和其他Ceph守護程序使用Ceph配置檔案來發現監視器,監視器使用監視器對映(monmap)發現彼此,而不是Ceph配置檔案。
當Ceph儲存叢集中發現其他Ceph監視器時,Ceph監視器總是引用monmap的本地副本。使用 monmap而不是Ceph配置檔案可以避免可能破壞叢集的錯誤(例如,在ceph.conf指定監視器地址或埠時出現拼寫錯誤)。由於監視器使用monmaps進行發現,並且它們與客戶端和其他Ceph守護程序共享monmaps,因此monmap為監視器提供了一致的保證,即他們的共識是有效的。
嚴格的一致性也適用於monmap的更新。與Ceph Monitor上的任何其他更新一樣,對monmap的更改始終通過名為Paxos的分散式一致性演算法執行。Ceph監視器必須就monmap的每次更新達成一致,例如新增或刪除Ceph監視器,以確保仲裁中的每個監視器都具有相同版本的monmap。monmap的更新是增量的,因此Ceph Monitors具有最新的商定版本和一組先前版本。維護歷史記錄使得具有舊版monmap的Ceph Monitor能夠趕上Ceph儲存叢集的當前狀態。
Monitor同步
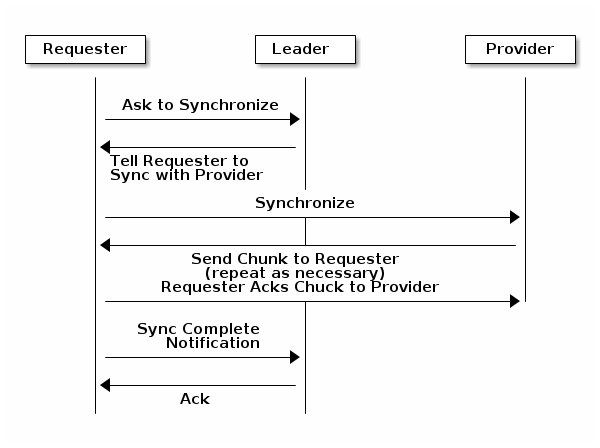
當你叢集中使用多個Monitor時,各監視器都要檢查鄰居是否有叢集執行圖的最新版本的群集對映,(例如,相鄰監視器中的一個對映,其中一個或多個紀元數字高於最大值即時監視器地圖中的當前時期)。群集中的一個監視器可能會定期從其他監視器後面移動到必須離開仲裁的位置,同步以檢索有關群集的最新資訊,然後重新加入仲裁。出於同步的目的,監視器可以採用以下三種角色之一;
(1)Leader 領導者:領導者是第一臺實現最新Paxos版本群集地圖的監視器。
(2)Provider 提供者:提供者是具有最新版本群集對映的監視器,但不是第一個獲得最新版本的監視器。
(3)Requester 請求者:一個請求者是下降落後領先者,並且必須以檢索有關叢集的最新資訊,然後才能重新加入仲裁同步監控。
這些角色使領導者能夠將同步職責委派給提供者,從而防止同步請求超載領導者改進效能。在下圖中,請求者已經瞭解到它已落後於其他監視器。請求者要求領導者進行同步,領導者告訴請求者與提供者同步。
(2)OSD
Ceph OSD是Ceph儲存叢集最重要的元件,Ceph OSD將資料以物件的形式儲存到叢集中每個節點的物理磁碟上,完成儲存使用者資料的工作絕大多數都是由OSD deamon程序來實現的。
Ceph叢集一般情況都包含多個OSD,對於任何讀寫操作請求,Client端從Ceph Monitor獲取Cluster Map之後,Client將直接與OSD進行I/O操作的互動,而不再需要Ceph Monitor干預。這使得資料讀寫過程更為迅速。
Ceph的核心功能特性包括高可靠、自動平衡、自動恢復和一致性,
對於Ceph OSD而言,基
於配置的副本數,Ceph提供通過分佈在多節點上的副本來實現,使得Ceph具有高可用性以及容錯性。在OSD中的每個物件都有一個主副本,若干個從副本,這些副本預設情況下是分佈在不同節點上的,這就是Ceph作為分散式儲存系統的集中體現。每個OSD都可能作為某些物件的主OSD,與此同時,它也可能作為某些物件的從OSD,從OSD受到主OSD的控制,然而,從OSD在某些情況也可能成為主OSD。在磁碟故障時,Ceph OSD Deamon的智慧對等機制將協同其他OSD執行恢復操作。在此期間,儲存物件副本的從OSD將被提升為主OSD,與此同時,新的從副本將重新生成,這樣就保證了Ceph的可靠和一致。
三、CRUSH
物件儲存中一致性Hash和Ceph的CRUSH演算法是使用比較多的資料分佈演算法。在Aamzon的Dyanmo鍵值儲存系統中採用一致性Hash演算法,並且對它做了很多優化。OpenStack的Swift物件儲存系統也使用了一致性Hash演算法。
CRUSH(Controlled Replication Under Scalable Hashing)是一種基於偽隨機控制資料分佈、複製的演算法。Ceph是為大規模分散式儲存系統(PB級的資料和成百上千臺儲存裝置)而設計的,在大規模的儲存系統裡,必須考慮資料的平衡分佈和負載(提高資源利用率)、最大化系統的效能,以及系統的擴充套件和硬體容錯等。
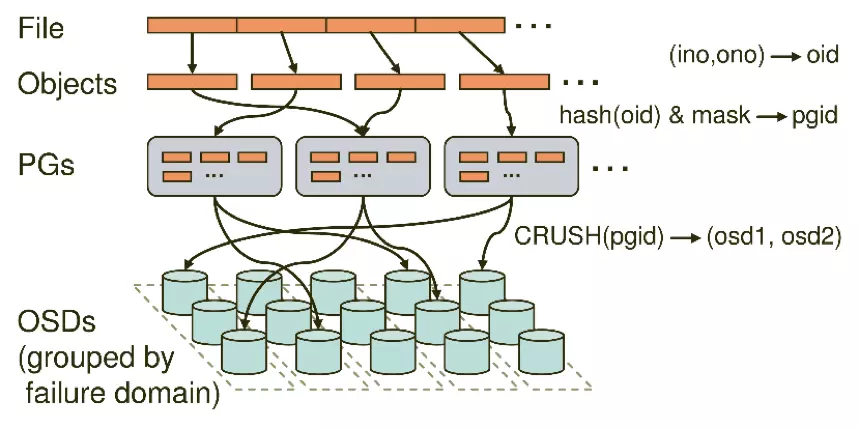
Ceph條帶化之後,將獲得N個帶有唯一oid(即object的id)。Object id是進行線性對映生成的,即由file的元資料、Ceph條帶化產生的Object的序號連綴而成。此時Object需要對映到PG中,該對映包括兩部分。
1)由Ceph叢集指定的靜態Hash函式計算Object的oid,獲取到其Hash值。
2)將該Hash值與mask進行與操作,從而獲得PG ID
由PG對映到資料儲存的實際單元OSD中,該對映是由CRUSH演算法來確定的,將PG ID作為該演算法的輸入,獲得到包含N個OSD的集合,集合中第一個OSD被作為主OSD,其他的OSD則依次作為從OSD。N為該PG所在POOL下的副本數目,在生產環境中N一般為3;OSD集合中的OSD將共同儲存和維護該PG下的Object。需要注意的是,CRUSH演算法的結果不是絕對不變的,而是受到其他因素的影響。其影響因素主要有以下兩個。
一是當前系統狀態 。也就是上文邏輯結構中曾經提及的Cluster Map(叢集對映)。當系統中的OSD狀態、數量發生變化時,Cluster Map可能發生變化,而這種變化將會影響到PG與OSD之間的對映。
二是儲存策略配置 。這裡的策略主要與安全相關。利用策略配置,系統管理員可以指定承載同一個PG的3個OSD分別位於資料中心的不同伺服器乃至機架上,從而進一步改善儲存的可靠性。
四、ceph資料的儲存過程
Ceph FS檔案系統
Ceph FS需要使用Metadata Server(簡稱MDS)來管理檔案系統的名稱空間以及客戶端如何訪問到後端OSD資料儲存中。MDS類似於ceph-mon,是一個服務程序,在使用Ceph FS前首先要安裝和啟動ceph-mds服務;MDS(Metadata Server)以一個Daemon程序執行一個服務,即元資料伺服器,主要負責Ceph FS叢集中檔案和目錄的管理,Ceph檔案系統主要依賴MDS守護程序提供服務。
ceph網站:
https://ceph.com/
http://docs.ceph.com/docs/master/
http://docs.ceph.org.cn