
python 爬取煎蛋ooxx妹子圖
阿新 • • 發佈:2018-11-12
煎蛋網妹子圖首頁(http://jandan.net/ooxx),這個連結看起來怎麼那麼邪惡呢?經分析網站隱藏了圖片地址。心一橫,採取曲線路線,成功爬取大量妹子圖~
原始碼如下:
1 import requests 2 import re 3 import os 4 import base64 5 from urllib.request import urlretrieve 6 7 8 class JianDan: 9 def __init__(self): 10 self.url_temp = "http://jandan.net/ooxx/page-{}#comments" 11 self.header = { 12 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'} 13 14 def get_url_list(self): 15 url_list = [self.url_temp.format(page) for page in range(1, 51)] 16 return url_list17 18 def parse_url(self, url): 19 try: 20 response = requests.get(url, headers=self.header) 21 html_str = response.content.decode() 22 img_base_urls = re.findall( 23 r'<span class="img-hash">(.*?)</span>', html_str) 24 img_urls = list(25 map(lambda base_url: "http:" + base64.b64decode(base_url).decode('utf-8'), img_base_urls)) 26 return img_urls 27 except Exception as e: 28 print(f"請求目標網站異常:{e}") 29 30 def make_file(self): 31 dir_name = '煎蛋IMG' 32 get_path = os.getcwd() 33 path_dir = get_path + "/" + dir_name 34 if not os.path.isdir(path_dir): 35 print(f"建立煎{dir_name}資料夾成功") 36 os.mkdir(path_dir) 37 else: 38 print(f"{dir_name}G資料夾已存在建立失敗") 39 return path_dir 40 41 def download(self, img_url, file_path): 42 file_name = "/" + img_url.split('/')[-1] 43 print(f"###### 正在儲存 -> {file_name} ") 44 try: 45 urlretrieve(img_url, file_path + file_name) 46 print(f"###### 儲存成功 -> {file_name} ") 47 except Exception as e: 48 print(f'下載圖片失敗:{file_name}') 49 50 def run(self): 51 url_list = self.get_url_list() 52 file_path = self.make_file() 53 for url in url_list: 54 print("#### 獲取第{}頁圖片 ####".format(url_list.index(url) + 1)) 55 img_urls = self.parse_url(url) 56 for img_url in img_urls: 57 self.download(img_url, file_path) 58 59 print("end...") 60 61 62 if __name__ == '__main__': 63 jiandan = JianDan() 64 jiandan.run()
執行結果:
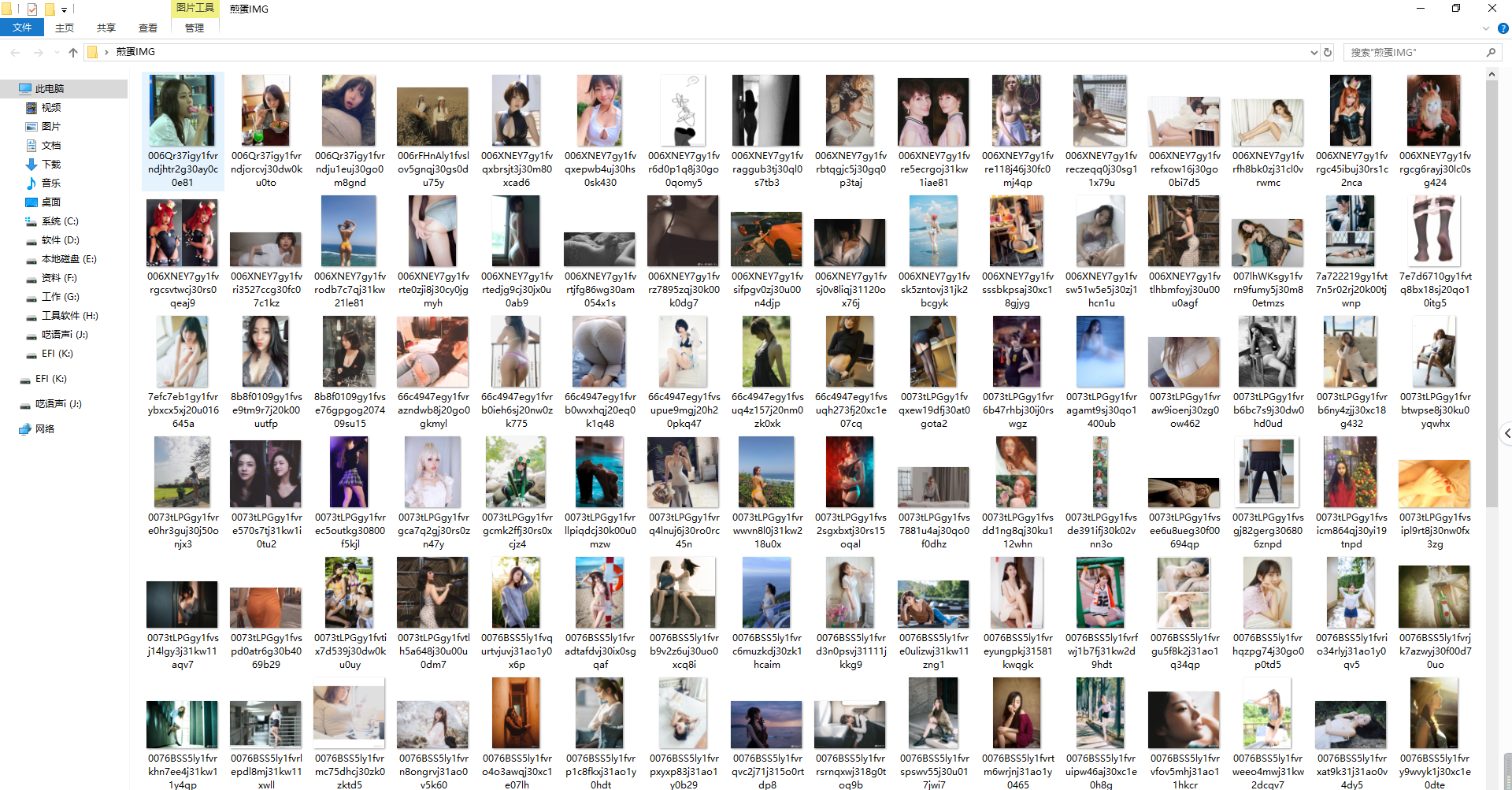
初學python與爬蟲,要學習的還很多。煎蛋網以後還會嘗試用更高效的方式來爬取測試的~