
爬蟲之煎蛋網妹子圖 大爬哦
阿新 • • 發佈:2019-01-26
ima 應該 h+ pan class net 處理 num close
今天為了測試一下urllib2模塊中的headers部分,也就是模擬客戶端登陸的那個東東,就對煎蛋網妹子圖練了一下手,感覺還可以吧。分享一下!
代碼如下
# coding:UTF-8
import urllib2,urllib,re,random
def getHtml(url) :
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
page = response.read()
return page
def getImageUrls(page) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
爬蟲結果
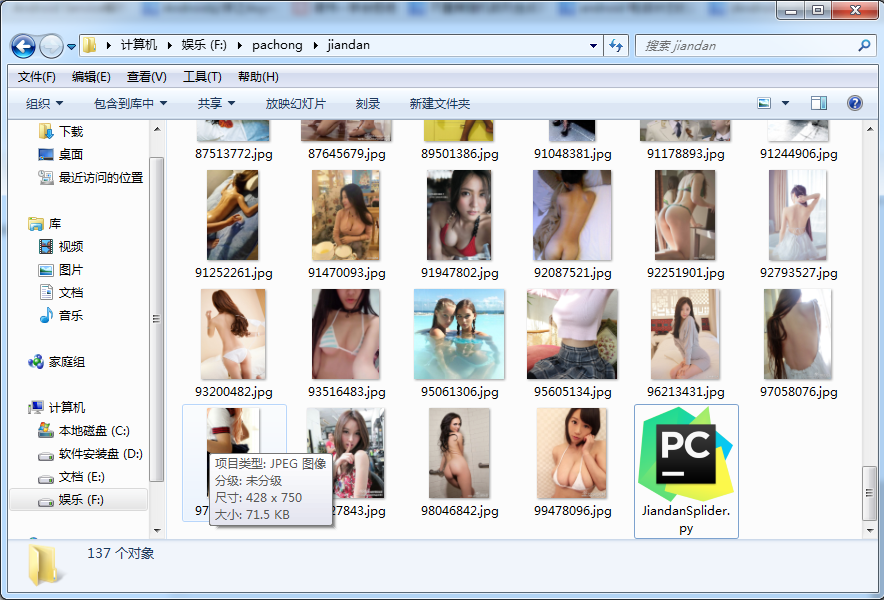
總結
代碼不多,核心在於思想。邏輯如下:
- 使用headers繞開網站的驗證
- 獲得主頁面中所有的圖片的url
- 根據圖片url循環的讀取網頁內容
- 再循環中就把圖片寫入到本地
是不是很簡單呢,但是這裏有不智能的地方,那就是沒有把原始的url做處理,如果再用url拼接技術的話,我們就可以實現“只需要一張網址,就可以抓取我們想要的所有的圖片了”。
代碼中不可避免的存在一些問題,歡迎大家批評指正!
再分享一下我老師大神的人工智能教程吧。零基礎!通俗易懂!風趣幽默!還帶黃段子!希望你也加入到我們人工智能的隊伍中來!https://blog.csdn.net/jiangjunshow
爬蟲之煎蛋網妹子圖 大爬哦