
基於流的生成模型
英偉達率先發表了相似的工作,讓千里之外的幾位研究者一臉懵逼,於是決定公佈程式碼以示沒有剽竊。
來自韓國首爾大學的研究者近期釋出了一篇利用基於流的生成模型進行實時的語音合成的研究 FloWaveNet。但奇怪的是,他們的論文中並沒有語音合成中典型的人類評估 MOS(平均意見分數)指標,甚至一個實驗圖示都沒有。原因很有趣:他們發現英偉達在前幾天釋出的論文 WaveGlow 竟然和 FloWaveNet 在主要思想上幾乎完全相同,都提出了基於流的語音合成方法。
為此,論文二作趕緊將程式碼、生成樣本以及 arXiv 手稿放了出來,並在 Reddit 上公告,然後苦苦思索如何安慰在實驗室角落哭泣的一作。
Reddit 網友紛紛伸出援手安慰一作:
你和領域巨頭的想法碰撞到一起了,這是好事不是嗎?
WaveGlow 仍然只是一篇 arXiv 論文,所以不用擔心,順便提一下,Nice Work!
我的朋友,深有同感。我幾周前和谷歌撞車,幾個月前還和 DeepMind 撞車。我是搞人工智慧的,又不是開碰碰車的。我在提交關於音訊生成的論文之前,谷歌釋出了類似的工作 Nsynth。我使用了簡單的基於自編碼器的生成模型,而谷歌的 Nsynth 基本思想一樣,但規模大得多,並且能結合其它很多先進的方法。作為個人很難和擁有更多工程師、研究員和資源的巨頭競爭。這是一個競爭激烈的行業,很難做出完全獨特的研究。但是沒關係,做好你自己的研究,並基於此不斷地改進,也是我們需要的研究態度。
英偉達也開源了 WaveGlow 的程式碼,所以你們可以更細緻地比較你們研究之間的不同。
- WaveGlow:https://github.com/NVIDIA/waveglow
- FloWaveNet:https://github.com/ksw0306/FloWaveNet
- FloWaveNet 生成樣本地址:https://drive.google.com/drive/folders/1RPo8e35lhqwOrMrBf1cVXqnF9hzxsunU
這兩篇論文到底有多相似?我們一起感受一下。
論文:FloWaveNet : A Generative Flow for Raw Audio
論文地址:https://arxiv.org/pdf/1811.02155.pdf
摘要:大多數文字到語音的架構使用了 WaveNet 語音編碼器來合成高保真的音訊波形,但由於自迴歸取樣太慢,其在實際應用中存在侷限性。人們近期提出的 Parallel WaveNet 通過整合逆向自迴歸流(IAF)到並行取樣中實現了實時的音訊合成。然而,Parallel WaveNet 需要兩個階段的訓練流水線,其中設計一個訓練良好的教師網路,並且如果僅使用 probability distillation 訓練容易導致模式崩潰。FloWaveNet 僅需要單個最大似然損失函式,而不需要任何其它輔助項,並且由於基於流的變換的使用,其內在地是並行的。該模型可以高效地實時取樣原始音訊,其語音清晰度和 WaveNet 以及 ClariNet 相當。
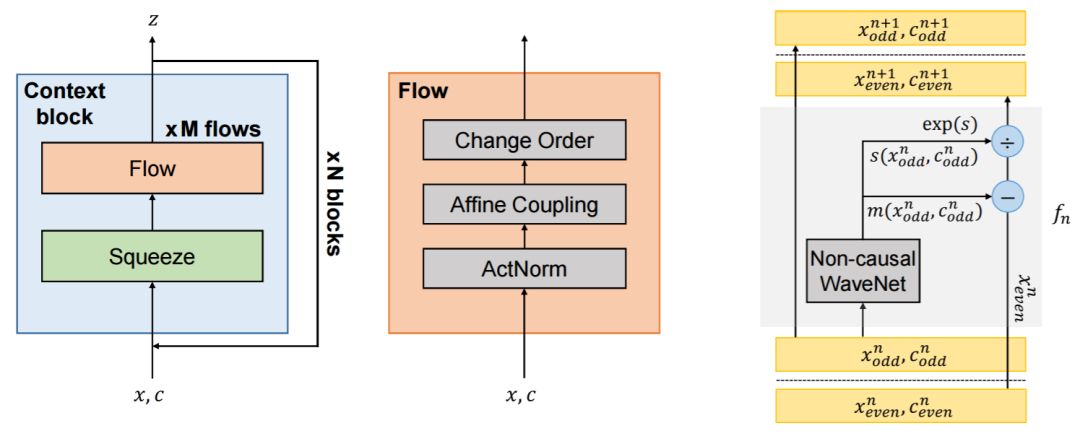
圖 1:FloWaveNet 模型圖示。左圖:FloWaveNet 的整個前向傳播過程,由 N 個上下文模組構成。中間:流操作的抽象圖示。右圖:affine coupling 操作細節。
論文:WAVEGLOW: A FLOW-BASED GENERATIVE NETWORK FOR SPEECH SYNTHESIS
論文地址:https://arxiv.org/pdf/1811.00002.pdf
摘要:在本文中我們提出了 WaveGlow,這是一個基於流的可以從梅爾譜圖生成高質量語音的網路。WaveGlow 結合了 Glow 和 WaveNet 的思想,以提供快速、高效和高質量的音訊合成,不需要使用自迴歸。WaveGlow 僅使用單個網路實現,用單個損失函式訓練:最大化訓練資料的似然度,這使得訓練過程簡單而穩定。平均意見分數評估表明該方法能生成和最佳的 WaveNet 實現質量相當的結果。

圖 1: WaveGlow 模型圖示。
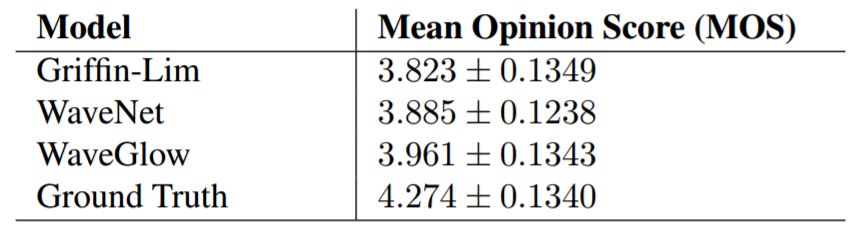
表 1:WaveGlow 平均意見分數評估結果。
我們大致能看到:FloWaveNet 和 WaveNet 都採用了基於流的生成模型思想;摒棄了自迴歸;摒棄兩階段訓練過程;不需要額外輔助損失項;只需要似然度作為損失函式;只需要一個網路;能生成和 WaveNet 質量相當的語音...... 如此正面剛的撞車,難怪一作疼的流淚。
當然,通過後面對基於流的生成模型的解釋,我們能發現,他們的研究的大部分重合點就是對這種模型的採用,其它的都是連帶效應。這到底是什麼樣的生成模型,可以一己之力扭轉乾坤,還讓相隔千里的 AI 研究者垂涎仰望,不覺撞車?
其實,最驚喜/驚奇的援手還是來自他們的冤大頭——英偉達。WaveGlow 的作者之一 Bryan Catanzaro 在 Reddit 上稱讚了他們的工作,還邀請他們去實習,在語音生成研究上合作......

學術界也是充滿了戲劇性~
為什麼要選擇基於流的生成模型
基於流的生成模型是繼 GAN 和 VAE 之後的第三種生成模型,但這只是很多人的初步印象。其實這種模型在 2014 年就被提出,比 GAN 還早,但僅在近期由於 OpenAI 提出了 Glow 模型才被人注意到。基於流的生成模型具有可逆和內在並行性的優點。
實際上,生成模型可以分為四個類別:自迴歸、GAN、VAE、flow-based(基於流)。以影象生成為例,自迴歸模型需要逐畫素地生成整張影象,每次新生成的畫素會作為生成下一個畫素的輸入。這種模型計算成本高,並行性很差,在大規模生成任務中效能有限。上述的 WaveNet 就是一種自迴歸模型,最大的缺點就是慢。其它典型的自迴歸模型還有 PixelRNN 和 PixelCNN。此外,自迴歸模型也是可逆的。相對於自迴歸模型,基於流的生成模型的優勢是其並行性。
相對於 VAE 和 GAN,基於流的生成模型的優勢是:可以用隱變數精確地建模真實資料的分佈,即精確估計對數似然,得益於其可逆性。而 VAE 儘管是隱變數模型,但只能推斷真實分佈的近似值,而隱變數分佈與真實分佈之間的 gap 是不可度量的,這也是 VAE 的生成影象模糊的原因。GAN 是一種學習正規化,並不特定於某種模型架構,並且由於其存在兩個模型互相博弈的特點,理論的近似極限也是無法確定的。基於流的生成模型卻可以在理論上保證可以完全逼近真實的資料分佈。
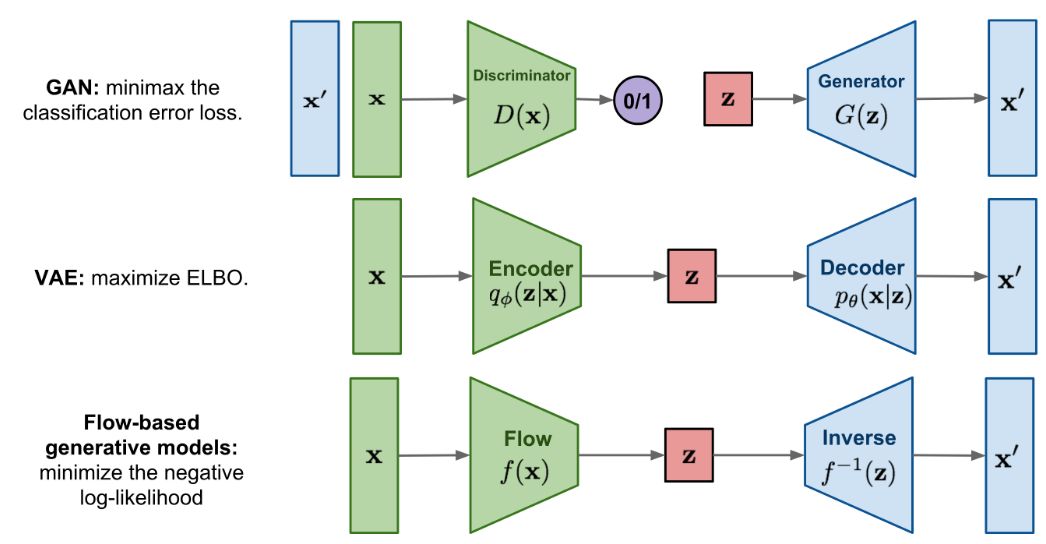
有這麼多的優點,以一己之力輕鬆克服 WaveNet 的缺點也不是什麼難事了,至於更深入的細節,還請參閱原論文。
基於流的生成模型可以大致理解為:它希望將資料表示成簡單的隱變數分佈,並可以從該分佈中完全還原真實資料的分佈。也就是說,它要學習的是一個可逆函式。利用雅可比矩陣的這個性質:一個函式的雅可比矩陣的逆矩陣,是該函式的反函式的雅可比矩陣,NICE 和 RealNVP 提出了通過順序的可逆函式變換,將簡單分佈逐步還原複雜的真實資料分佈的歸一化流過程,如下圖所示。後來在 Glow 中提出用 1x1 可逆卷積替換 NICE 和 RealNVP 中的可逆變換。

由於可以進行精確的密度估計,基於流的生成模型在很多下游任務中具備天然優勢,例如資料補全、資料插值、新資料生成等。
在 Glow 中,這種模型展示了其在影象生成和影象屬性操控上的潛力:

Glow 實現的人臉影象屬性操作。訓練過程中沒有給模型提供屬性標籤,但它學習了一個潛在空間,其中的特定方向對應於鬍鬚密度、年齡、頭髮顏色等屬性的變化。
這類模型是不是能超越 GAN 不好說,但相對於 VAE 還是有很明顯的優勢,在未來的生成模型研究領域中也是非常值得期待和關注的方向。
參考內容
https://lilianweng.github.io/lil-log/2018/10/13/flow-based-deep-generative-models.html
https://www.reddit.com/r/MachineLearning/comments/9uxbbj/p_flowavenet_a_generative_flow_for_raw_audio/