
Linux TC的ifb原理以及ingress流控
阿新 • • 發佈:2018-11-12
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
首先貼上Linux核心的ifb.c的檔案頭註釋:
for sharing of resources:
1) qdiscs/policies that are per device as opposed to system wide.
ifb allows for a device which can be redirected to thus providing
an impression of sharing.
2) Allows for queueing incoming traffic for shaping instead of
dropping.
The original concept is based on what is known as the IMQ
driver initially written by Martin Devera, later rewritten
by Patrick McHardy and then maintained by Andre Correa.
You need the tc action mirror or redirect to feed this device
packets.
This program is free software; you can redistribute it and/or
modify it under the terms of the GNU General Public License
as published by the Free Software Foundation; either version
2 of the License, or (at your option) any later version.
Authors: Jamal Hadi Salim (2005)
ifb驅動太簡單,以至於很短的話就可以將其說清,然後上一幅全景圖,最後留下一點如何使用它的技巧,本文就完了。
ifb驅動模擬一塊虛擬網絡卡,它可以被看作是一個只有TC過濾功能的虛擬網絡卡,說它只有過濾功能,是因為它並不改變資料包的方向,即對於往外發的資料包被重定向到ifb之後,經過ifb的TC過濾之後,依然是通過重定向之前的網絡卡發出去,對於一個網絡卡接收的資料包,被重定向到ifb之後,經過ifb的TC過濾之後,依然被重定向之前的網絡卡繼續進行接收處理,不管是從一塊網絡卡傳送資料包還是從一塊網絡卡接收資料包,重定向到ifb之後,都要經過一個經由ifb虛擬網絡卡的dev_queue_xmit操作。說了這麼多,看個圖就明白了:
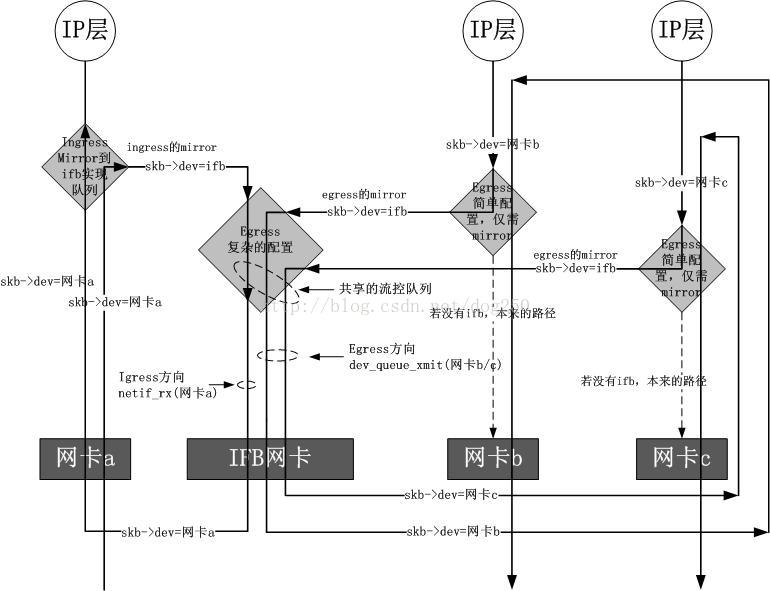
ingress佇列
Linux TC是一個控發不控收的框架,然而這是對於TC所置於的位置而言的,而不是TC本身的限制,事實上,你完全可以自己在ingress點上實現一個佇列機制,說TC控發不控收只是因為Linux TC目前的實現沒有實現ingress佇列而已。Linux的協議棧上有諸多的鉤子點,Netfilter當然是最顯然的了,它不但可以實現防火牆和NAT,也可以將一個數據包在PREROUTING鉤子點上queue到一個佇列,然後再將此佇列的資料包發往一個虛擬網絡卡,虛擬網絡卡的xmit回撥函式將資料包重新放回Netfilter將資料包STOLEN走的點上,在發往虛擬網絡卡的時候做傳送流控從而變相地實現ingress佇列,這就是IMQ的原理,它工作地不錯,但是需要在skb中增加欄位,使用起來也要牽扯到Netfilter的配置,不是那麼純粹,於是在這個思想的基礎上實現了ifb驅動,這個驅動直接掛在TC本身的ingress鉤子上,並不和Netfilter發生關係,但是由於TC的鉤子機制並沒有將一個數據包偷走再放回的機制,於是只有在做完ifb的流控後在ifb網絡卡的xmit函式中重新呼叫實際網絡卡的rx一次,這個實現和Linux Bridge的實現中完成local deliver的實現如出一轍。
除了ingress佇列之外,在多個網絡卡之間共享一個根Qdisc是ifb實現的另一個初衷,可以從檔案頭的註釋中看出來。如果你有10塊網絡卡,想在這10塊網絡卡上實現相同的流控策略,你需要配置10遍嗎?將相同的東西抽出來,實現一個ifb虛擬網絡卡,然後將這10塊網絡卡的流量全部重定向到這個ifb虛擬網絡卡上,此時只需要在這個虛擬網絡卡上配置一個Qdisc就可以了。
效能問題
也許你覺得,將多塊網絡卡的流量重定向到一塊ifb網絡卡,這豈不是要將所有的本屬於不同的網絡卡佇列被不同CPU處理的資料包排隊到ifb虛擬網絡卡的一個佇列被一個CPU處理嗎?事實上,這種擔心是多餘的。是的,ifb虛擬網絡卡只有一個網絡卡接收佇列和傳送佇列,但是這個佇列並非被一個CPU處理的,而是被原來處理該資料包的CPU(只是儘量,但不能保證就是原來處理該資料包的那個CPU)繼續處理,怎麼做到的呢?事實上ifb採用了tasklet來對待資料包的傳送和接收,在資料包進入fib的xmit函式之後,將資料包排入佇列,然後在本CPU上,注意這個CPU就是原來處理資料包的那個CPU,在本CPU上排程一個tasklet,當tasklet被執行的時候,會取出佇列中的資料包進行處理,如果是egress上被重定向到了ifb,就呼叫原始網絡卡的xmit,如果是ingress上被重定向到了ifb,就呼叫原始網絡卡的rx。當然,tasklet中只是在佇列中取出第一個資料包,這個資料包不一定就是在這個CPU上被排入的,這也許會損失一點cache的高利用率帶來的效能提升,但不管怎樣,如果是多CPU系統,那麼顯然tasklet不會只在一個CPU上被排程執行。另外,開銷還是有一點的,那就是操作單一佇列時的自旋鎖開銷。
優化方式是顯然的,那就是將佇列實現成“每CPU”的,這樣不但可以保證cache的高利用率,也免去了操作單一佇列的鎖開銷。
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
