
43.scrapy爬取鏈家網站二手房資訊-1
阿新 • • 發佈:2018-11-12
首先分析:
目的:採集鏈家網站二手房資料
1.先分析一下二手房主介面資訊,顯示情況如下:
url = https://gz.lianjia.com/ershoufang/pg1/
顯示總資料量為27589套,但是頁面只給返回100頁的資料,每頁30條資料,也就是隻給返回3000條資料。
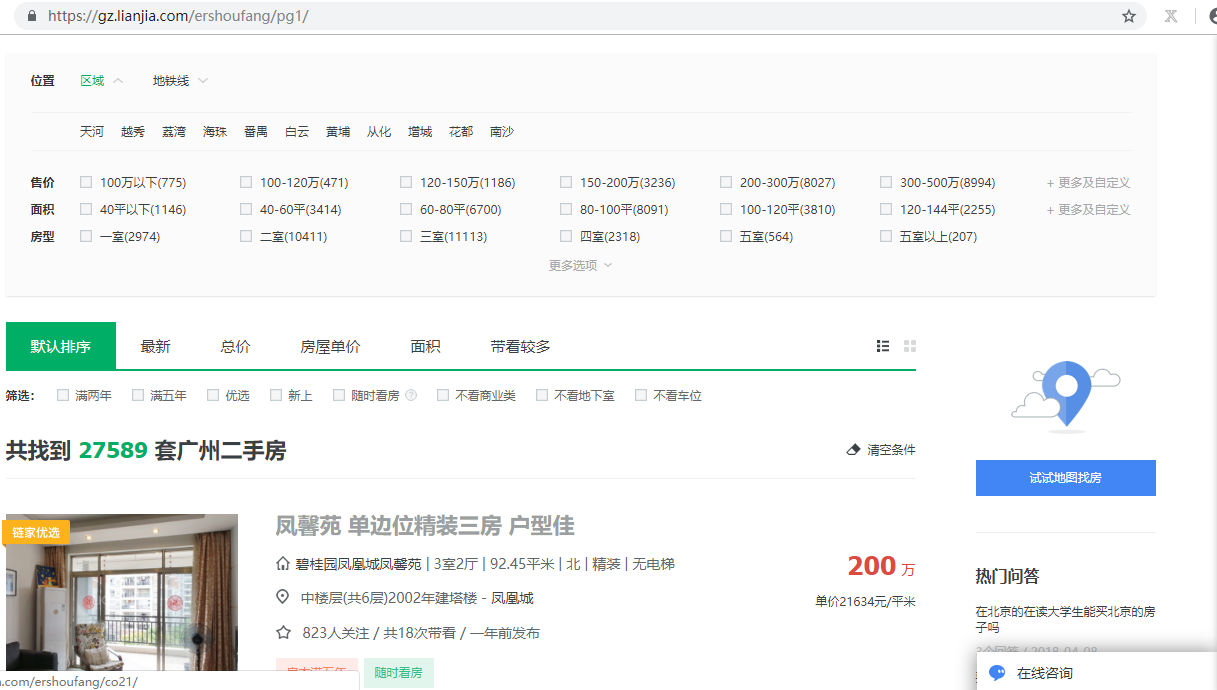
2.再看一下篩選條件的情況:
100萬以下(775):https://gz.lianjia.com/ershoufang/pg1p1/(p1是篩選條件引數,pg1是頁面引數) 頁面返回26頁資訊
100萬-120萬(471):https://gz.lianjia.com/ershoufang/pg1p2/ 頁面返回16頁資訊
以此類推也就是網站只給你返回檢視最多100頁,3000條的資料,登陸的話情況也是一樣的情況。
3.採集程式碼如下:
這個是 linjia.py 檔案,這裡需要注意的問題就是 setting裡要設定
ROBOTSTXT_OBEY = False,不然頁面不給返回資料。
# -*- coding: utf-8 -*- import scrapy class LianjiaSpider(scrapy.Spider): name = 'lianjia' allowed_domains = ['gz.lianjia.com'] start_urls = ['https://gz.lianjia.com/ershoufang/pg1/']def parse(self, response): #獲取當前頁面url link_urls = response.xpath("//div[@class='info clear']/div[@class='title']/a/@href").extract() for link_url in link_urls: # print(link_url) yield scrapy.Request(url=link_url,callback=self.parse_detail) print('*'*100) #翻頁 for i in range(1,101): url = 'https://gz.lianjia.com/ershoufang/pg{}/'.format(i) # print(url) yield scrapy.Request(url=url,callback=self.parse) def parse_detail(self,response): title = response.xpath("//div[@class='title']/h1[@class='main']/text()").extract_first() print('標題: '+ title) dist = response.xpath("//div[@class='areaName']/span[@class='info']/a/text()").extract_first() print('所在區域: '+ dist) contents = response.xpath("//div[@class='introContent']/div[@class='base']") # print(contents) house_type = contents.xpath("./div[@class='content']/ul/li[1]/text()").extract_first() print('房屋戶型: '+ house_type) floor = contents.xpath("./div[@class='content']/ul/li[2]/text()").extract_first() print('所在樓層: '+ floor) built_area = contents.xpath("./div[@class='content']/ul/li[3]/text()").extract_first() print('建築面積: '+ built_area) family_structure = contents.xpath("./div[@class='content']/ul/li[4]/text()").extract_first() print('戶型結構: '+ family_structure) inner_area = contents.xpath("./div[@class='content']/ul/li[5]/text()").extract_first() print('套內面積: '+ inner_area) architectural_type = contents.xpath("./div[@class='content']/ul/li[6]/text()").extract_first() print('建築型別: '+ architectural_type) house_orientation = contents.xpath("./div[@class='content']/ul/li[7]/text()").extract_first() print('房屋朝向: '+ house_orientation) building_structure = contents.xpath("./div[@class='content']/ul/li[8]/text()").extract_first() print('建築結構: '+ building_structure) decoration_condition = contents.xpath("./div[@class='content']/ul/li[9]/text()").extract_first() print('裝修狀況: '+ decoration_condition) proportion = contents.xpath("./div[@class='content']/ul/li[10]/text()").extract_first() print('梯戶比例: '+ proportion) elevator = contents.xpath("./div[@class='content']/ul/li[11]/text()").extract_first() print('配備電梯: '+ elevator) age_limit =contents.xpath("./div[@class='content']/ul/li[12]/text()").extract_first() print('產權年限: '+ age_limit) try: house_label = response.xpath("//div[@class='content']/a/text()").extract_first() except: house_label = '' print('房源標籤: ' + house_label) # decoration_description = response.xpath("//div[@class='baseattribute clear'][1]/div[@class='content']/text()").extract_first() # print('裝修描述 '+ decoration_description) # community_introduction = response.xpath("//div[@class='baseattribute clear'][2]/div[@class='content']/text()").extract_first() # print('小區介紹: '+ community_introduction) # huxing_introduce = response.xpath("//div[@class='baseattribute clear']3]/div[@class='content']/text()").extract_first() # print('戶型介紹: '+ huxing_introduce) # selling_point = response.xpath("//div[@class='baseattribute clear'][4]/div[@class='content']/text()").extract_first() # print('核心賣點: '+ selling_point) # 以追加的方式及開啟一個檔案,檔案指標放在檔案結尾,追加讀寫! with open('text', 'a', encoding='utf-8')as f: f.write('\n'.join( [title,dist,house_type,floor,built_area,family_structure,inner_area,architectural_type,house_orientation,building_structure,decoration_condition,proportion,elevator,age_limit,house_label])) f.write('\n' + '=' * 50 + '\n') print('-'*100)
4.這裡採集的是全部,沒設定篩選條件,只返回100也資料。
採集資料情況如下:
這裡只採集了15個欄位資訊,其他的資料沒采集。
採集100頁,算一下拿到了2704條資料。

 4.這個是上週寫的,也沒做修改完善,之後會對篩選條件url進行整理,儘量採集網站多的資料資訊,可以通過獲取篩選條件分別獲取完整資料。
4.這個是上週寫的,也沒做修改完善,之後會對篩選條件url進行整理,儘量採集網站多的資料資訊,可以通過獲取篩選條件分別獲取完整資料。