
併發中的volatile
目錄
1. 概述
由於執行緒有本地記憶體的存在, 一個執行緒修改的共享變數不會及時的重新整理到主記憶體中, 使得另一個執行緒讀取共享變數時讀取到的仍舊是舊值, 就導致了記憶體可見性問題. 現在volatile就可以解決這個問題, 為什麼能解決記憶體可見性問題呢? 本文就來揭開volatile的神祕面紗.
2. volatile的特性
理解volatile特性的一個好方法就是把對volatile單個變數的讀/寫, 看成是使用同一個鎖對單個變數的讀/寫做了同步.
鎖的happens-before規則保證釋放鎖和獲取鎖的兩個執行緒之間的記憶體可見性, 這意味著對一個volatile變數的讀, 總是能看到(任意執行緒)對這個volatile變數最後的寫入.
鎖的語義決定了臨界區程式碼的執行具有原子性. 這意味著, 即使是64位的long型和double型變數, 只要它是volatile變數, 對該變數的讀/寫就具有原子性. 如果是多個volatile操作或類似於volatile++這種複合操作, 這些操作整體上不具有原子性.
簡言之, volatile變數自身具有以下特性.
- 可見性: 對一個volatile變數的讀, 總是能看到任意執行緒對這個volatile變數最後的寫入.
- 原子性: 對任意單個volatile變數的讀/寫具有原子性, volatile變數的複合操作不具有原子性.
3. volatile寫-讀的記憶體語義
volatile寫的記憶體語義
當寫一個volatile變數時, JMM會把該執行緒對應的本地記憶體中的共享變數值重新整理到主記憶體中.
volatile讀的記憶體語義
當讀一個volatile變數時, JMM會把執行緒對應的本地記憶體中的共享變數值置為無效, 執行緒接下來將從主記憶體中讀取共享變數.
volatile記憶體語義總結
- 執行緒A寫一個volatile變數, 實質上是執行緒A向接下來將要讀這個volatile變數的某個執行緒發出了(其對共享變數所做修改的)訊息.
- 執行緒B讀一個volatile變數, 實質上是執行緒B接收了之前某個執行緒發出的(在寫這個volatile變數之前對共享變數所做修改的)訊息.
- 執行緒A寫一個volatile變數, 隨後執行緒B讀這個volatile變數, 這個過程實質上是執行緒A通過主記憶體向執行緒B傳送訊息.
4. volatile記憶體語義的實現
前面提到過重排序分為編譯器重排序和處理器重排序. 為了實現volatile語義, JMM會分別限制這兩種型別的重排序型別.
JMM針對編譯器制定的volatile重排序規則表

從圖中可以看出:
- 當第二個操作是volatile寫時, 不管第一個操作是什麼, 都不能重排序. 這個規則確保volatile寫之前的操作不會被編譯器重排序到volatile寫之後.
- 當第一個操作是volatile讀時, 不管第二個操作是什麼, 都不能重排序. 這個規則確保volatile讀之後的操作不會被編譯器重排序到volatile讀之前.
- 當第一個操作是volatile寫, 第二個操作是volatile讀時, 不能重排序.
為了實現volatile的記憶體語義, 編譯器在生成位元組碼時, 會在指令序列中插入記憶體屏障來禁止特定型別的處理器重排序. 對於編譯器來說, 發現一個最優佈置來最小化插入屏障的總數幾乎不可能. 為此, JMM採取保守策略. 下面是基於保守策略的JMM記憶體屏障插入策略.
- 在每個volatile寫操作的前面插入一個StoreStore屏障.
- 在每個volatile寫操作的後面插入一個StoreLoad屏障.
- 在每個volatile讀操作的後面插入一個LoadLoad屏障.
- 在每個volatile讀操作的後面插入一個LoadStore屏障.
上述記憶體屏障插入策略非常保守, 但它可以保證在任意處理器平臺, 任意的程式中都能得到正確的volatile記憶體語義.
在實際執行時, 只要不改變volatile寫-讀的記憶體語義, 編譯器可以根據具體情況省略不必要的屏障. 舉個例子.
有如下程式碼:
public class Demo {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; // 第一個volatile讀
int j = v2; // 第二個volatile讀
a = i + j; // 普通寫
v1 = i + 1; // 第一個volatile寫
v2 = j * 2; // 第二個 volatile寫
}
}針對readAndWrite()方法, 理論上生成位元組碼時會如下:
int i = v1; // volatile讀後面插入LoadLoad和LoadStore屏障
LoadLoad; // 確保v1的裝載先於後續裝載指令
LoadStore; // 確保v1的載入先於後續儲存指令
int j = v2; // volatile讀後面插入LoadLoad和LoadStore屏障
LoadLoad; // 確保v2的裝載先於後續裝載指令
LoadStore; // 確保v2的載入先於後續儲存指令
a = i + j; // 普通讀寫無屏障
StoreStore; // 確保之前的儲存指令要先於v1的儲存
v1 = i + 1; // volatile寫前加StoreStore屏障, 後加StoreLoad屏障
StoreLoad; // 確保v1的儲存要先於後續的裝載指令
StoreStore; // 確保之前的儲存指令要先於v1的儲存
v2 = j + 1; // volatile寫前加StoreStore屏障, 後加StoreLoad屏障
StoreLoad; // 確保v1的儲存要先於後續的裝載指令由於不同的處理器有不同的"鬆緊度"的處理器記憶體模型, 記憶體屏障的插入還可以根據具體的處理器記憶體模型繼續優化, 以X86處理器為例, 處理最後的StoreLoad屏障外, 其它的屏障都會被省略. X86處理器僅會對寫-讀操作做重排序, 不會對讀-讀, 讀-寫和寫-寫操作做重排序. 因此X86處理器會省略掉這3中操作型別對應的記憶體屏障. 所以在X86處理器中, JMM僅需在volatile寫後面插入一個StoreLoad屏障即可實現volatile寫-讀的記憶體語義.
下面是X86處理器優化之後的記憶體屏障
int i = v1; // volatile讀後面插入LoadLoad和LoadStore屏障
// LoadLoad; // 確保v1的裝載先於後續裝載指令
// LoadStore; // 確保v1的載入先於後續儲存指令
int j = v2; // volatile讀後面插入LoadLoad和LoadStore屏障
// LoadLoad; // 確保v2的裝載先於後續裝載指令
// LoadStore; // 確保v2的載入先於後續儲存指令
a = i + j; // 普通讀寫無屏障
// StoreStore; // 確保之前的儲存指令要先於v1的儲存
v1 = i + 1; // volatile寫前加StoreStore屏障, 後加StoreLoad屏障
StoreLoad; // 確保v1的儲存要先於後續的裝載指令
// StoreStore; // 確保之前的儲存指令要先於v1的儲存
v2 = j + 1; // volatile寫前加StoreStore屏障, 後加StoreLoad屏障
StoreLoad; // 確保v1的儲存要先於後續的裝載指令5. JSR-133為什麼要增強volatile的記憶體語義
JSR-133也就是在JDK1.5中加入的.
在JSR-133之前的舊Java記憶體模型中, 雖然不允許volatile變數之間重排序, 但舊的Java記憶體模型允許volatile變數與普通變數重排序.
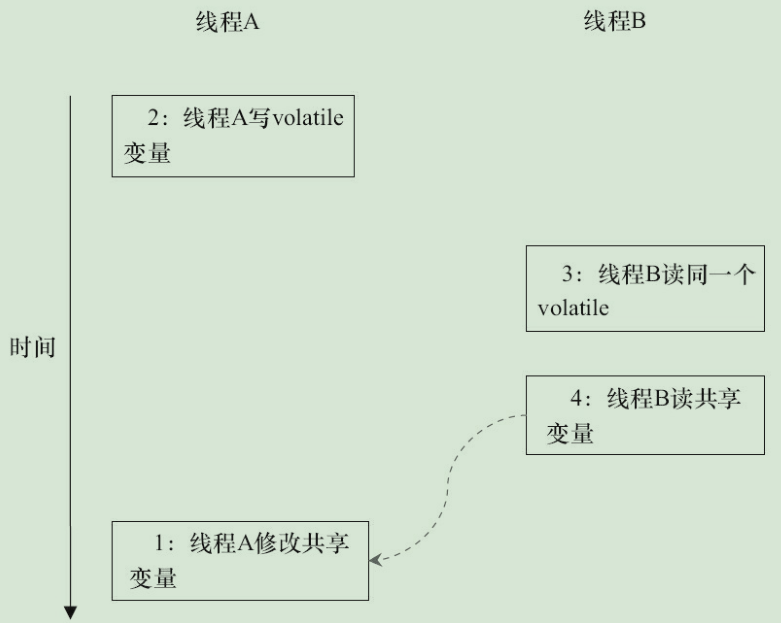
在舊的記憶體模型中, 當1和2之間沒有資料依賴關係時, 1和2之間就可能被重排序(3和4類似). 其結果就是: 讀執行緒B執行4時, 不一定能看到寫執行緒A在執行1時對共享變數的修改.
因此, 在舊的記憶體模型中, volatile的寫-讀沒有鎖的釋放-獲所具有的記憶體語義. 為了提供一種比鎖更輕量級的執行緒之間通訊的機制, JSR-133專家組決定增強volatile的記憶體語義: 嚴格限制編譯器和處理器對volatile變數與普通變數的重排序, 確保volatile的寫-讀和鎖的釋放-獲取具有相同的記憶體語義. 從編譯器重排序規則和處理器記憶體屏障插入策略來看, 只要volatile變數與普通變數之間的重排序可能會破壞volatile的記憶體語義, 這種重排序就會被編譯器重排序規則和處理器記憶體屏障插入策略禁止.
6. 總結
volatile能保證記憶體可見性正是通過記憶體屏障來實現的, 並且不同的編譯器對記憶體屏障的支援不同, 但是由於大多數處理器都使用了寫緩衝區, 所以大多數處理器都支援StoreLoad屏障.