
機器學習-準備之主要概念
一 數學
1 代數
-
變數、係數和函式
-
線性方程式,例如 y = b +w1x1 +w2x2
-
對數和對數方程式,例如 y = In(1+ez)
-
S 型函式
前面幾個知識點比較好理解,我們看一下 S 型函式
S型函式(Sigmoid function)是BP神經網路中常用的非線性作用函式,即sigmoid函式,公式是f(x)=1/(1+e^-x)(-x是冪數)。Sigmoid函式又分為Log-Sigmoid函式和Tan-Sigmoid函式。由於BP神經網路的傳遞函式必須可微,所以感知器的傳遞函式–二值函式在這裡不可用,故BP神經網路一般使用Sigmoid函式或者線性函式作為傳遞函式。而Sigmoid函式又分為Log-Sigmoid函式(一般所說的S型函式就是這個的簡稱)和Tan-Sigmoid函式(又稱為雙曲正切S型函式),前者的值域為(0,1),後者的值域為(-1,1)。
2 線性代數
-
張量和張量等級
-
矩陣乘法
張量(Tensor)是一個定義在一些向量空間和一些對偶空間的笛卡兒積上的多重線性對映,其座標是|n|維空間內,有|n|個分量的一種量, 其中每個分量都是座標的函式, 而在座標變換時,這些分量也依照某些規則作線性變換。r 稱為該張量的秩或階(與矩陣的秩和階均無關係)。
在同構的意義下,第零階張量 (r = 0) 為標量 (Scalar),第一階張量 (r = 1) 為向量 (Vector), 第二階張量 (r = 2) 則成為矩陣 (Matrix)。例如,對於3維空間,r=1時的張量為此向量:(x,y,z)。由於變換方式的不同,張量分成協變張量 (Covariant Tensor,指標在下者)、逆變張量 (Contravariant Tensor,指標在上者)、 混合張量 (指標在上和指標在下兩者都有) 三類。

3 三角學
Tanh(作為啟用函式進行講解,無需提前掌握相關知識)
tanh是雙曲函式中的一個,tanh()為雙曲正切。在數學中,雙曲正切“tanh”是由基本雙曲函式雙曲正弦和雙曲餘弦推導而來。
函式:y=tanh x;定義域:R,值域:(-1,1)。y=tanh x是一個奇函式,其函式影象為過原點並且穿越Ⅰ、Ⅲ象限的嚴格單調遞增曲線,其影象被限制在兩水平漸近線y=1和y=-1之間
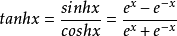
4 統計資訊
-
均值、中間值、離群值和標準偏差
離群值(outlier),也稱逸出值,是指在資料中有一個或幾個數值與其他數值相比差異較大。chanwennt準則規定,如果一個數值偏離觀測平均值的概率小於等於1/(2n),則該資料應當捨棄(其中n為觀察例數,概率可以很據資料的分佈進行估計)。
標準差也被稱為標準偏差,標準差(Standard Deviation)描述各資料偏離平均數的距離(離均差)的平均數,它是離差平方和平均後的方根,用σ表示。標準差是方差的算術平方根。標準差能反映一個數據集的離散程度,標準偏差越小,這些值偏離平均值就越少,反之亦然。標準偏差的大小可通過標準偏差與平均值的倍率關係來衡量。平均數相同的兩個資料集,標準差未必相同。
總體標準偏差 ,
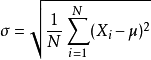
u代表總體X的均值。
5 微積分
-
導數概念(您不必真正計算導數)
-
梯度或斜率
-
偏導數(與梯度緊密相關)
-
鏈式法則(帶您全面瞭解用於訓練神經網路的反向傳播演算法)
導數(Derivative)是微積分中的重要基礎概念。當函式y=f(x)的自變數x在一點x0上產生一個增量Δx時,函式輸出值的增量Δy與自變數增量Δx的比值在Δx趨於0時的極限a如果存在,a即為在x0處的導數,記作f’(x0)或df(x0)/dx。
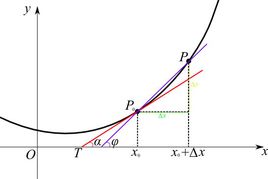
梯度的本意是一個向量(向量),表示某一函式在該點處的方向導數沿著該方向取得最大值,即函式在該點處沿著該方向(此梯度的方向)變化最快,變化率最大(為該梯度的模)。
在單變數的實值函式的情況,梯度只是導數,或者,對於一個線性函式,也就是線的斜率。
斜率亦稱“角係數”,表示平面直角座標系中表示一條直線對橫座標軸的傾斜程度的量
偏導數反映的是函式沿座標軸正方向的變化率。
鏈式法則是微積分中的求導法則,用於求一個複合函式的導數,是在微積分的求導運算中一種常用的方法。複合函式的導數將是構成複合這有限個函式在相應點的 導數的乘積,就像鎖鏈一樣一環套一環,故稱鏈式法則。