
機器學習入門之四:機器學習的方法-神經網絡(轉載)
轉自 飛鳥各投林
神經網絡
神經網絡(也稱之為人工神經網絡,ANN)算法是80年代機器學習界非常流行的算法,不過在90年代中途衰落。現在,攜著“深度學習”之勢,神經網絡重裝歸來,重新成為最強大的機器學習算法之一。
神經網絡的誕生起源於對大腦工作機理的研究。早期生物界學者們使用神經網絡來模擬大腦。機器學習的學者們使用神經網絡進行機器學習的實驗,發現在視覺與語音的識別上效果都相當好。
在BP算法(加速神經網絡訓練過程的數值算法)誕生以後,神經網絡的發展進入了一個熱潮。BP算法的發明人之一是前面介紹的機器學習大牛Geoffrey Hinton(圖1中的中間者)。
具體說來,神經網絡的學習機理是什麽?簡單來說,就是分解與整合。在著名的Hubel-Wiesel試驗中,學者們研究貓的視覺分析機理是這樣的。
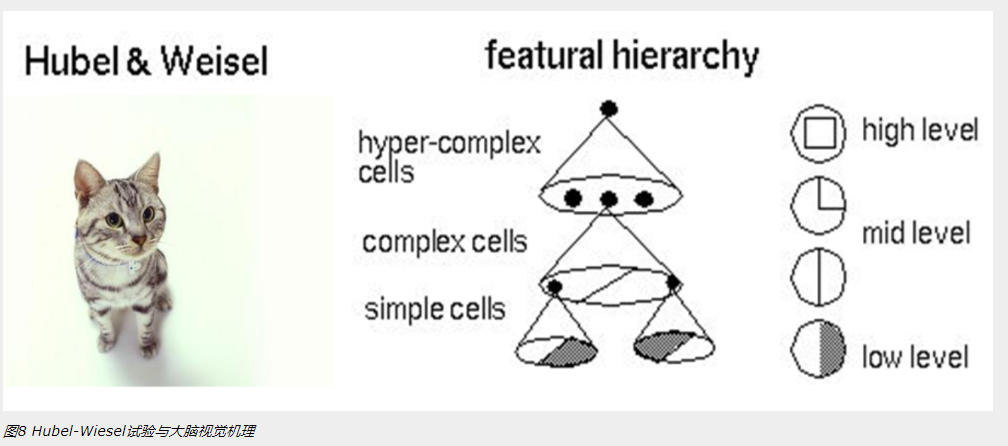
比方說,一個正方形,分解為四個折線進入視覺處理的下一層中。四個神經元分別處理一個折線。每個折線再繼續被分解為兩條直線,每條直線再被分解為黑白兩個面。於是,一個復雜的圖像變成了大量的細節進入神經元,
神經元處理以後再進行整合,最後得出了看到的是正方形的結論。這就是大腦視覺識別的機理,也是神經網絡工作的機理。
讓我們看一個簡單的神經網絡的邏輯架構。在這個網絡中,分成輸入層,隱藏層,和輸出層。輸入層負責接收信號,隱藏層負責對數據的分解與處理,最後的結果被整合到輸出層。每層中的一個圓代表一個處理單元,
可以認為是模擬了一個神經元,若幹個處理單元組成了一個層,若幹個層再組成了一個網絡,也就是"神經網絡"。
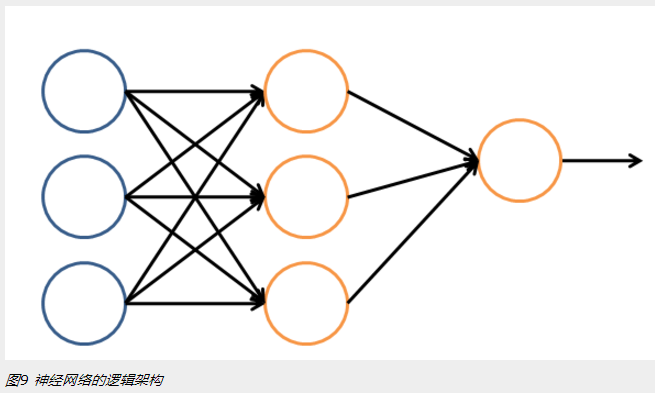
在神經網絡中,每個處理單元事實上就是一個邏輯回歸模型,邏輯回歸模型接收上層的輸入,把模型的預測結果作為輸出傳輸到下一個層次。通過這樣的過程,神經網絡可以完成非常復雜的非線性分類。
下圖會演示神經網絡在圖像識別領域的一個著名應用,這個程序叫做LeNet,是一個基於多個隱層構建的神經網絡。通過LeNet可以識別多種手寫數字,並且達到很高的識別精度與擁有較好的魯棒性。
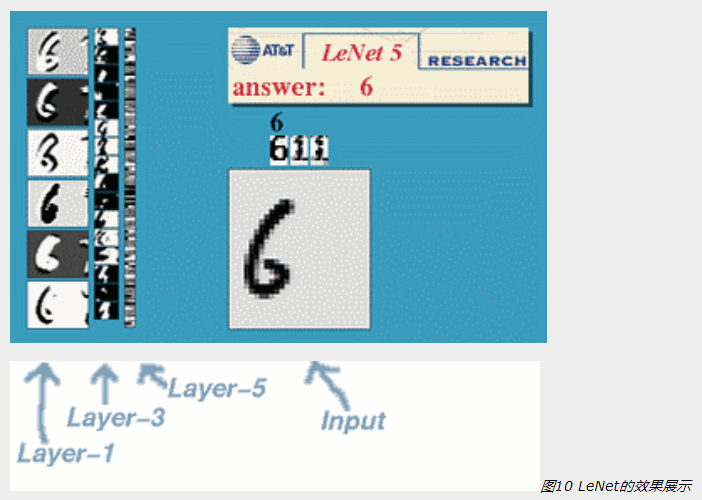
右下方的方形中顯示的是輸入計算機的圖像,方形上方的紅色字樣“answer”後面顯示的是計算機的輸出。左邊的三條豎直的圖像列顯示的是神經網絡中三個隱藏層的輸出,可以看出,隨著層次的不斷深入,
越深的層次處理的細節越低,例如層3基本處理的都已經是線的細節了。LeNet的發明人就是前文介紹過的機器學習的大牛Yann LeCun(圖1右者)。
進入90年代,神經網絡的發展進入了一個瓶頸期。其主要原因是盡管有BP算法的加速,神經網絡的訓練過程仍然很困難。因此90年代後期支持向量機(SVM)算法取代了神經網絡的地位。
機器學習入門之四:機器學習的方法-神經網絡(轉載)