
常見快取演算法和LRU的c++實現
對於web開發而言,快取必不可少,也是提高效能最常用的方式。無論是瀏覽器快取(如果是chrome瀏覽器,可以通過chrome:://cache檢視),還是服務端的快取(通過memcached或者redis等記憶體資料庫)。快取不僅可以加速使用者的訪問,同時也可以降低伺服器的負載和壓力。那麼,瞭解常見的快取淘汰演算法的策略和原理就顯得特別重要。
常見的快取演算法
- LRU (Least recently used) 最近最少使用,如果資料最近被訪問過,那麼將來被訪問的機率也更高。
- LFU (Least frequently used) 最不經常使用,如果一個數據在最近一段時間內使用次數很少,那麼在將來一段時間內被使用的可能性也很小。
- FIFO (Fist in first out) 先進先出, 如果一個數據最先進入快取中,則應該最早淘汰掉。
LRU快取
像瀏覽器的快取策略、memcached的快取策略都是使用LRU這個演算法,LRU演算法會將近期最不會訪問的資料淘汰掉。LRU如此流行的原因是實現比較簡單,而且對於實際問題也很實用,良好的執行時效能,命中率較高。下面談談如何實現LRU快取:
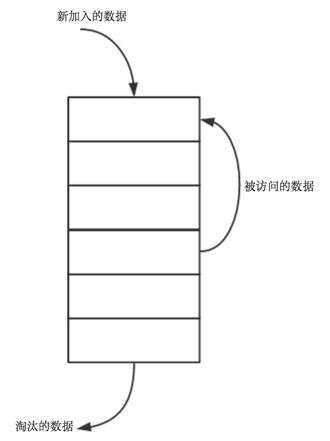
- 新資料插入到連結串列頭部
- 每當快取命中(即快取資料被訪問),則將資料移到連結串列頭部
- 當連結串列滿的時候,將連結串列尾部的資料丟棄
LRU Cache具備的操作:
- set(key,value):如果key在hashmap中存在,則先重置對應的value值,然後獲取對應的節點cur,將cur節點從連結串列刪除,並移動到連結串列的頭部;若果key在hashmap不存在,則新建一個節點,並將節點放到連結串列的頭部。當Cache存滿的時候,將連結串列最後一個節點刪除即可。
- get(key):如果key在hashmap中存在,則把對應的節點放到連結串列頭部,並返回對應的value值;如果不存在,則返回-1。
LRU的c++實現
LRU實現採用雙向連結串列 + Map 來進行實現。這裡採用雙向連結串列的原因是:如果採用普通的單鏈表,則刪除節點的時候需要從表頭開始遍歷查詢,效率為O(n),採用雙向連結串列可以直接改變節點的前驅的指標指向進行刪除達到O(1)的效率。使用Map來儲存節點的key、value值便於能在O(logN)的時間查詢元素,對應get操作。
雙鏈表節點的定義:
struct CacheNode { int key; // 鍵 int value; // 值 CacheNode *pre, *next; // 節點的前驅、後繼指標 CacheNode(int k, int v) : key(k), value(v), pre(NULL), next(NULL) {} };
對於LRUCache這個類而言,建構函式需要指定容量大小
LRUCache(int capacity)
{
size = capacity; // 容量
head = NULL; // 連結串列頭指標
tail = NULL; // 連結串列尾指標
}雙鏈表的節點刪除操作:
void remove(CacheNode *node)
{
if (node -> pre != NULL)
{
node -> pre -> next = node -> next;
}
else
{
head = node -> next;
}
if (node -> next != NULL)
{
node -> next -> pre = node -> pre;
}
else
{
tail = node -> pre;
}
}將節點插入到頭部的操作:
void setHead(CacheNode *node)
{
node -> next = head;
node -> pre = NULL;
if (head != NULL)
{
head -> pre = node;
}
head = node;
if (tail == NULL)
{
tail = head;
}
}get(key)操作的實現比較簡單,直接通過判斷Map是否含有key值即可,如果查詢到key,則返回對應的value,否則返回-1;
int get(int key)
{
map<int, CacheNode *>::iterator it = mp.find(key);
if (it != mp.end())
{
CacheNode *node = it -> second;
remove(node);
setHead(node);
return node -> value;
}
else
{
return -1;
}
}set(key, value)操作需要分情況判斷。如果當前的key值對應的節點已經存在,則將這個節點取出來,並且刪除節點所處的原有的位置,並在頭部插入該節點;如果節點不存在節點中,這個時候需要在連結串列的頭部插入新節點,插入新節點可能導致容量溢位,如果出現溢位的情況,則需要刪除連結串列尾部的節點。
void set(int key, int value)
{
map<int, CacheNode *>::iterator it = mp.find(key);
if (it != mp.end())
{
CacheNode *node = it -> second;
node -> value = value;
remove(node);
setHead(node);
}
else
{
CacheNode *newNode = new CacheNode(key, value);
if (mp.size() >= size)
{
map<int, CacheNode *>::iterator iter = mp.find(tail -> key);
remove(tail);
mp.erase(iter);
}
setHead(newNode);
mp[key] = newNode;
}
}至此,LRU演算法的實現操作就完成了,完整的原始碼參考:https://github.com/cpselvis/leetcode/blob/master/solution146.cpp